






最小二乘法
一、最小二乘法概念以及应用
最小二乘法(Least Squares Method, LSE)是一种数学优化技术,主要用于寻找最佳拟合给定数据点的函数。它通过最小化观测值与模型预测值之间的差的平方和来估计模型参数。
换成听得懂的话说就是,我们有一组数据(x1,y1),(x2,y2)…(xn,yn),我们也知道他的数学表达式的形式例如y=kx+b(但是不知道k、b的具体值),但是(xn,yn)等这些点不是完全落到表达式上,那么需要拟合一条直线y=k0x+b0让它最契合(xn,yn)这些点,并把k0、b0给求出来。
那么我们什么时候可以认定f(x)=k0*x+b0最契合我们数据(xn,yn)呢,在19世纪,勒让德认为让“误差的平方和最小”估计出来的模型是最接近的。为什么就是误差平方而不是其它的,这里推荐一篇其他博主的帖子最小二乘法的原理理解_最小二乘法原理-优快云博客。
什么是误差的平方和最小呢?其实就是:
L
=
∑
i
=
0
n
(
y
i
−
f
(
x
i
)
)
2
L=\sum_{i=0}^{n}(y_i-f(x_i))^2 \\
L=i=0∑n(yi−f(xi))2
其中的yi就是我们真实的数据,f(x)=k0x+b0是我们要拟合的直线,让每个真实的数据yi和要拟合的数据f(x)做差后取平方(平方就是乘两次,也就是二乘)最后加起来,是一个L关于k0、b0的一个函数,那么L肯定是大于等于0的,当让L最小时,取的k0、b0的值就最契合我们的数据了,那么这个过程就是最小二乘法了。其中L这个公式呢称为代价函数(Cost Function),也称为损失函数(Loss Function)或误差函数,是用来衡量模型预测输出与实际数据之间差距的一个函数,也就是说最小二乘其实就是一种损失函数。像除了使用最小二乘(主要用于线性回归问题),根据不同的情景还可以使用均方误差(Mean Squared Error, MSE)、对数损失(Log Loss)、交叉熵(Cross-Entropy) 等等算法。
最小二乘法可以应用以下方面:
- **线性回归:**这是最小二乘法最常见的应用之一。
- **多项式回归**:通过引入更高次项扩展线性模型。
- **非线性回归**:当关系不是严格线性时,可以通过变换变量或其他技巧应用最小二乘法。
- **信号处理**:用于滤波和平滑数据(其实就是在一堆杂乱信号中,找到我们想要频率的信号)。
二、最小二乘法-线性回归方程
上面呢我们大体知道了最小二乘的一个过程(就是让真实数据和拟合数据做差后取平方,最后找到L的最小点),那么这个算法具体是怎么求出我们预测模型中的系数k0和b0的呢,最常用的方法是线性回归方程(但是需要注意的是,线性回归法只能解决线性拟合问题,比如y=kx+b,对于非线性问题,比如y=a+b*sin(wt),的求解是不准确的,需要其他的方法,比如梯度下降法、牛顿法等),这一节本文分为两个部分,第一个部分举一个例子,方便理解,第二部分通过公式推导,最终形成一个类似的模版,只要记住这个模版,只要将数据代入其中就能解出我们的系数。
2.1实例演示
比如我们有一组数据:
(
x
1
,
y
1
)
=
(
1.1
,
1.0
)
(
x
2
,
y
2
)
=
(
2.0
,
2.1
)
(
x
3
,
y
3
)
=
(
3.0
,
3.0
)
(x_1,y_1)=(1.1,1.0)\\(x_2,y_2)=(2.0,2.1)\\(x_3,y_3)=(3.0,3.0) \\
(x1,y1)=(1.1,1.0)(x2,y2)=(2.0,2.1)(x3,y3)=(3.0,3.0)
我们假设用曲线y=kx+b去拟合上面这组数据(很明显这组数据最契合y=x曲线,我们用最小二乘法求出来看一下k是否为1,b是否为0)。
我们把数据代入到损失函数L中得到:
L
[
k
,
b
]
=
∑
i
=
0
n
(
y
i
−
f
(
x
i
)
)
2
=
(
y
1
−
f
(
x
1
)
)
2
+
(
y
2
−
f
(
x
2
)
)
2
+
(
y
2
−
f
(
x
2
)
)
2
=
[
1
−
(
1.1
k
+
b
)
]
2
+
[
2.1
−
(
2
k
+
b
)
]
2
+
[
3
−
(
3
k
+
b
)
]
2
=
14.21
k
2
−
28.6
k
+
3
b
2
−
12.2
b
+
12.2
k
b
+
14.41
L[k,b]=\sum_{i=0}^{n}(y_i-f(x_i))^2=(y_1-f(x_1))^2+(y_2-f(x_2))^2+(y_2-f(x_2))^2\\ =[1-(1.1k+b)]^2+[2.1-(2k+b)]^2+[3-(3k+b)]^2\\ =14.21k^2-28.6k+3b^2-12.2b+12.2kb+14.41
L[k,b]=i=0∑n(yi−f(xi))2=(y1−f(x1))2+(y2−f(x2))2+(y2−f(x2))2=[1−(1.1k+b)]2+[2.1−(2k+b)]2+[3−(3k+b)]2=14.21k2−28.6k+3b2−12.2b+12.2kb+14.41
可以看到,当我们把数据代入后,构建了一个L关于k和b的函数(这个就是损失函数)。只要通过某些特定方法找到使L最小点时的k和b的值,就能拟合出曲线了。这些特定方法包括但不限于导数法、几何法、梯度下降法、线性回归法。其中线性回归法对于求解线性拟合问题可以化简为一个模版,它是最简单,最基础,最好用的方法,具体算法留到第二小节再推导。
我们在这里暂时先不用上面这些方法,我们就把他当做一个数学题来解。我们一看原始数据就知道b接近0,如果此时我们让b=0代入上面公式,其实L就是k的一个二次函数,我们求导找到极点就可以了(当然了,这种做法在实际中肯定没法用,我们这里只是简单地展示一下)。
L
=
14.21
k
2
−
28.6
k
+
14.41
L=14.21k^2-28.6k+14.41
L=14.21k2−28.6k+14.41
我们不难发现当L最小时,k=0.9937。如果不知道b=0,我们可以用偏导数,求L关于k,b的偏导数,找到曲线的极点,这里我们就不展示了。回过来看,其实我们把曲线拟合问题转换成了求L最小点的问题,虽然我们不能直接拟合曲线,但我们有大量的方法求函数的最小点。
2.2线性回归方程
在2.1小节中,当我们只有一个参数k需要拟合的时候,还是比较好处理的,一旦遇到两个参数k、b时,勉强也能够解决,但是遇到多个参数时,处理起来比较棘手,那么此时我们要寻求一种比较好用的、比较通用的解法——线性回归方程。
其实线性回归其本质还是求导找极值,但是通过数学推导后会化简很多东西,这里需要注意的是,线性回归法只能解决线性拟合问题,对于非线性问题的求解是不准确的,需要其他的方法。
假设我们共有m个原始数据(这里y有多个自变量):
(
x
11
,
x
12
,
.
.
,
x
1
n
,
y
1
)
(
x
21
,
x
22
,
.
.
,
x
2
n
,
y
2
)
.
.
.
(
x
m
1
,
x
m
2
,
.
.
,
x
m
n
,
y
m
)
(x_{11},x_{12},..,x_{1n},y_{1})\\ (x_{21},x_{22},..,x_{2n},y_{2})\\ ...\\ (x_{m1},x_{m2},..,x_{mn},y_{m})\\
(x11,x12,..,x1n,y1)(x21,x22,..,x2n,y2)...(xm1,xm2,..,xmn,ym)
将自变量x每列单独列出,可以获得n个m×1维的列向量:
X
1
=
(
x
11
,
x
21
,
.
.
.
x
m
1
)
T
X
2
=
(
x
12
,
x
22
,
.
.
.
x
m
2
)
T
.
.
.
X
n
=
(
x
1
n
,
x
2
n
,
.
.
.
x
m
n
)
T
X_1=(x_{11},x_{21},...x_{m1})^T\\ X_2=(x_{12},x_{22},...x_{m2})^T\\ ...\\ X_n=(x_{1n},x_{2n},...x_{mn})^T\\
X1=(x11,x21,...xm1)TX2=(x12,x22,...xm2)T...Xn=(x1n,x2n,...xmn)T
Y = ( y 1 , y 2 , . . . y m ) T Y=(y_1,y_2,...y_m)^T Y=(y1,y2,...ym)T
假设我们的预测模型为:
H
[
a
0
,
a
1
,
a
2
.
.
.
a
n
]
=
a
0
+
a
1
X
1
+
a
2
X
2
+
.
.
.
+
a
n
X
n
H[a_0,a_1,a_2...a_n]=a_0 + a_1X_{1}+a_2X_{2}+...+a_nX_{n}
H[a0,a1,a2...an]=a0+a1X1+a2X2+...+anXn
系数矩阵为:
A
=
[
a
0
,
a
1
,
a
2
,
.
.
.
a
n
]
T
A=[a_0,a_1,a_2,...a_n]^T
A=[a0,a1,a2,...an]T
即
H
1
[
a
0
,
a
1
,
a
2
.
.
.
a
n
]
=
a
0
+
a
1
x
11
+
a
2
x
12
+
.
.
.
+
a
n
x
1
n
H
2
[
a
0
,
a
1
,
a
2
.
.
.
a
n
]
=
a
0
+
a
1
x
21
+
a
2
x
22
+
.
.
.
+
a
n
x
2
n
.
.
.
H
m
[
a
0
,
a
1
,
a
2
.
.
.
a
n
]
=
a
0
+
a
1
x
m
1
+
a
2
x
m
2
+
.
.
.
+
a
n
x
m
n
H_1[a_0,a_1,a_2...a_n]=a_0 + a_1x_{11}+a_2x_{12}+...+a_nx_{1n}\\ H_2[a_0,a_1,a_2...a_n]=a_0 + a_1x_{21}+a_2x_{22}+...+a_nx_{2n}\\ ...\\ H_m[a_0,a_1,a_2...a_n]=a_0 + a_1x_{m1}+a_2x_{m2}+...+a_nx_{mn}
H1[a0,a1,a2...an]=a0+a1x11+a2x12+...+anx1nH2[a0,a1,a2...an]=a0+a1x21+a2x22+...+anx2n...Hm[a0,a1,a2...an]=a0+a1xm1+a2xm2+...+anxmn
我们为了可以运用矩阵,假设x0=1,我们把X扩展一下:
X
0
=
(
1
,
1
,
.
.
.
1
)
X
=
(
X
0
,
X
1
,
X
2
,
X
3
,
.
.
.
X
n
)
H
[
a
0
,
a
1
,
a
2
.
.
.
a
n
]
=
a
0
X
0
+
a
1
X
1
+
a
2
X
2
+
.
.
.
+
a
n
X
n
=
X
A
X_0=(1,1,...1)\\ X=(X_0,X_1,X_2,X_3,...X_n)\\ H[a_0,a_1,a_2...a_n]=a_0X_0 + a_1X_{1}+a_2X_{2}+...+a_nX_{n}=XA
X0=(1,1,...1)X=(X0,X1,X2,X3,...Xn)H[a0,a1,a2...an]=a0X0+a1X1+a2X2+...+anXn=XA
我们构造代价函数:
L
=
∑
i
=
0
n
(
y
i
−
f
(
x
i
)
)
2
=
∣
∣
H
−
Y
∣
∣
2
=
∣
∣
X
m
×
(
n
+
1
)
A
(
n
+
1
)
×
1
−
Y
m
×
1
∣
∣
2
=
(
X
m
×
(
n
+
1
)
A
(
n
+
1
)
×
1
−
Y
m
×
1
)
T
(
X
m
×
(
n
+
1
)
A
(
n
+
1
)
×
1
−
Y
m
×
1
)
L=\sum_{i=0}^{n}(y_i-f(x_i))^2=||H-Y||^2=||X_{m×(n+1)}A_{(n+1)×1}-Y_{m×1}||^2=(X_{m×(n+1)}A_{(n+1)×1}-Y_{m×1})^T(X_{m×(n+1)}A_{(n+1)×1}-Y_{m×1})
L=i=0∑n(yi−f(xi))2=∣∣H−Y∣∣2=∣∣Xm×(n+1)A(n+1)×1−Ym×1∣∣2=(Xm×(n+1)A(n+1)×1−Ym×1)T(Xm×(n+1)A(n+1)×1−Ym×1)
这里呢,我们涉及到了一些关于矩阵的运算法则,我们回顾一下。
- ||H-Y||2 这里竖线内是Frobenius 范数,Frobenius 范数的平方等于矩阵所有元素的平方和。那么最后可以化简成||A-B|| 2=(A-B)T(A-B)
- (A-B)T=AT-BT
- (A*B)T=BTAT
- (A + B)*(C+D)=AC+AD+BC+BD
对代价函数进一步化简:
L
=
(
X
m
×
(
n
+
1
)
A
(
n
+
1
)
×
1
−
Y
m
×
1
)
T
(
X
m
×
(
n
+
1
)
A
(
n
+
1
)
×
1
−
Y
m
×
1
)
=
X
T
A
T
X
A
−
X
T
A
T
Y
−
Y
T
X
A
+
Y
T
Y
L=(X_{m×(n+1)}A_{(n+1)×1}-Y_{m×1})^T(X_{m×(n+1)}A_{(n+1)×1}-Y_{m×1})\\ =X^TA^TXA-X^TA^TY-Y^TXA+Y^TY
L=(Xm×(n+1)A(n+1)×1−Ym×1)T(Xm×(n+1)A(n+1)×1−Ym×1)=XTATXA−XTATY−YTXA+YTY
此时,我们为了找到L关于A的最小值,我们可以用L对A进行求导找极值。
∂
L
∂
A
=
∂
X
T
A
T
X
A
∂
A
−
∂
X
T
A
T
Y
∂
A
−
∂
Y
T
X
A
∂
A
+
∂
Y
T
Y
∂
A
\partial \frac {L}{\partial A}= \frac {\partial X^TA^TXA}{\partial A}-\frac{\partial X^TA^TY}{\partial A}-\frac{\partial Y^TXA}{\partial A}+ \frac{\partial Y^TY}{\partial A}
∂∂AL=∂A∂XTATXA−∂A∂XTATY−∂A∂YTXA+∂A∂YTY
这里呢,我们涉及到了一些关于矩阵的偏微分运算,我们回顾一下。
1.
∂
X
T
A
∂
A
=
∂
A
T
X
∂
A
=
X
2.
∂
A
T
X
A
∂
A
=
X
A
+
X
T
A
1.\frac {\partial X^TA}{\partial A}=\frac {\partial A^TX}{\partial A}=X\\ 2.\frac {\partial A^TXA}{\partial A}=XA+X^TA
1.∂A∂XTA=∂A∂ATX=X2.∂A∂ATXA=XA+XTA
根据两个公式进行化简:
∂
L
∂
A
=
2
X
T
X
A
−
2
X
T
Y
=
0
\partial \frac {L}{\partial A}=2X^TXA-2X^TY=0
∂∂AL=2XTXA−2XTY=0
那么可以求得:
A
=
(
X
T
X
)
−
1
X
T
Y
A=(X^TX)^{-1}X^TY
A=(XTX)−1XTY
最终我们可以简化到只剩下一个公式。只要代入我们原始数据,便可求出系数。
2.3验证线性回归方程
我们还是用第一章中的数据。
(
x
1
,
y
1
)
=
(
1.1
,
1.0
)
(
x
2
,
y
2
)
=
(
2.0
,
2.1
)
(
x
3
,
y
3
)
=
(
3.0
,
3.0
)
(x_1,y_1)=(1.1,1.0)\\(x_2,y_2)=(2.0,2.1)\\(x_3,y_3)=(3.0,3.0) \\
(x1,y1)=(1.1,1.0)(x2,y2)=(2.0,2.1)(x3,y3)=(3.0,3.0)
那么
X
=
(
X
0
,
X
1
)
=
(
1
1.1
1
2.0
1
3.0
)
X=(X_0,X_1)=\begin{pmatrix} 1 & 1.1 \\ 1 & 2.0 \\ 1&3.0 \end{pmatrix}
X=(X0,X1)=
1111.12.03.0
Y = ( 1 2.1 3 ) Y=\begin{pmatrix} 1 \\ 2.1\\ 3 \end{pmatrix} Y= 12.13
代入到公式中
A
=
(
X
T
X
)
−
1
X
T
Y
=
(
(
1
1
1
1.1
2.0
3.0
)
(
1
1.1
1
2.0
1
3.0
)
)
−
1
(
1
1
1
1.1
2.0
3.0
)
(
1
2.1
3
)
=
(
3.0
6.1
6.1
14.21
)
−
1
(
1
1
1
1.1
2.0
3.0
)
(
1
2.1
3
)
=
(
2.62177
−
1.12546
−
1.12546
0.553506
)
(
1
1
1
1.1
2.0
3.0
)
(
1
2.1
3
)
=
(
−
0.101292
1.04982
)
A=(X^TX)^{-1}X^TY=(\begin{pmatrix} 1 & 1 & 1 \\ 1.1 & 2.0 & 3.0 \end{pmatrix}\begin{pmatrix} 1 & 1.1 \\ 1 & 2.0 \\ 1&3.0 \end{pmatrix})^{-1}\begin{pmatrix} 1 & 1 & 1 \\ 1.1 & 2.0 & 3.0 \end{pmatrix}\begin{pmatrix} 1 \\ 2.1\\ 3 \end{pmatrix}\\ =\begin{pmatrix} 3.0 & 6.1\\ 6.1 & 14.21 \end{pmatrix}^{-1}\begin{pmatrix} 1 & 1 & 1 \\ 1.1 & 2.0 & 3.0 \end{pmatrix}\begin{pmatrix} 1 \\ 2.1\\ 3 \end{pmatrix}\\ =\begin{pmatrix} 2.62177 & -1.12546\\ -1.12546 & 0.553506 \end{pmatrix}\begin{pmatrix} 1 & 1 & 1 \\ 1.1 & 2.0 & 3.0 \end{pmatrix}\begin{pmatrix} 1 \\ 2.1\\ 3 \end{pmatrix}\\ =\begin{pmatrix} -0.101292 \\ 1.04982 \end{pmatrix}\\
A=(XTX)−1XTY=((11.112.013.0)
1111.12.03.0
)−1(11.112.013.0)
12.13
=(3.06.16.114.21)−1(11.112.013.0)
12.13
=(2.62177−1.12546−1.125460.553506)(11.112.013.0)
12.13
=(−0.1012921.04982)
即,最终的拟合结果为
H
[
a
0
,
a
1
]
=
a
0
+
a
1
x
=
1.04982
x
−
0.101292
H[a_0,a_1]=a_0+a_1x=1.04982x-0.101292
H[a0,a1]=a0+a1x=1.04982x−0.101292
也可以写个简单地matlab程序,试一下辨识结果。
clear;
x=-100:1:100-1;
x=x’;
y =10 * (x + 5*randn(200,1))-100;%增加一些噪声 k=10 b=-100,辨识结果准确度和噪声有关
grid onplot(x,y)
X=zeros(200,2);
X(:,1)=X(:,1)+1;
X(:,2)=x;
Y=y;
A=(X’* X)^(-1) * X ’ * Y;
A
三、最小二乘-梯度下降法
3.1梯度下降法基础知识
在第二章中我们知道在拟合线性直线的时候,线性回归方程很简单的就能拟合出来,但是遇到非线性问题线性回归法就不好用了,甚至就没办法用了(但是在局部范围内还是能用的,比如在拟合A*sin(x)这个函数时,我们知道当x ~ 0时,sin(x) ~ x,那么在这个范围可以近似一下,但归根接地还是不好用)。那么我们就要搬出我们的梯度下降法了。一般来说,非线性拟合时,一般很难一步直接求出损失函数的最小值,甚至求不出损失函数的最小值(比如说遇到超越方程时)。
但是:
- 既然一步求不出来,我们可以进行多次迭代
- 既然求不出最小值,那么我们可以多次迭代,直到认为当L小到一定程度时,就达到曲线拟合精度的要求了
在了解梯度下降算法之前,我们先了解一下几个概念,以便于我们更好的理解它(方向导数与梯度_梯度grad计算公式-优快云博客想要详细了解,可以参考这个博主的文章)
- 偏导数:是多个数,是指多元函数沿坐标轴方向的方向导数。
- 梯度:其是一个向量,每个元素为函数对一元变量的偏导数;它既有大小(其大小为最大方向导数),也有方向。
- 方向导数:其是一个数;反应的是f(x,y),在 P P P点沿着方向 l ⃗ \vec l l的变化率。
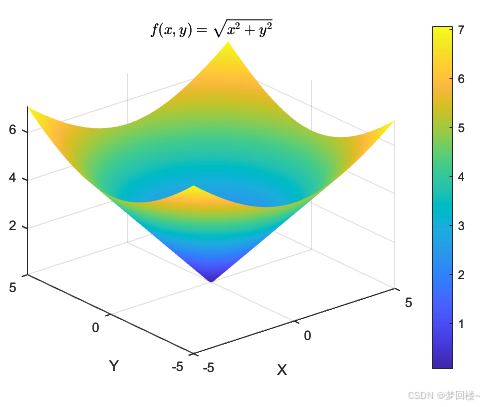
接下来,以一个圆锥体的函数 f ( x , y ) = x 2 + y 2 f(x,y)=\sqrt{x^2+y^2} f(x,y)=x2+y2,我们就分别求一下上面这三个东西,
1.偏导数
偏导数衡量的是一个多变量函数在一个特定变量方向上的变化率,而保持其他所有变量不变。对于一个二元函数
f
(
x
,
y
)
f(x,y)
f(x,y),偏导数的定义如下:
∂
f
∂
x
=
lim
t
→
∞
f
(
x
+
t
,
y
)
−
f
(
x
,
y
)
t
∂
f
∂
y
=
lim
t
→
∞
f
(
x
,
y
+
t
)
−
f
(
x
,
y
)
t
\partial \frac{ f}{\partial x}=\lim_{t \to \infty}\frac{f(x+t,y)-f(x,y)}{t}\\ \partial \frac{ f}{\partial y}=\lim_{t \to \infty}\frac{f(x,y+t)-f(x,y)}{t}
∂∂xf=t→∞limtf(x+t,y)−f(x,y)∂∂yf=t→∞limtf(x,y+t)−f(x,y)
例如对我们的函数求偏导:
∂
f
∂
x
=
x
x
2
+
y
2
∂
f
∂
y
=
y
x
2
+
y
2
\partial \frac{ f}{\partial x}=\frac{x}{\sqrt{x^2+y^2}}\\ \partial \frac{ f}{\partial y}=\frac{y}{\sqrt{x^2+y^2}}
∂∂xf=x2+y2x∂∂yf=x2+y2y
2.梯度
梯度是一个向量,它包含了所有偏导数的信息。对于一个二元函数
f
(
x
,
y
)
f(x,y)
f(x,y)在点P时,其梯度记为
∇
f
∣
P
\nabla f|_{P}
∇f∣P,或者是
g
r
a
d
f
∣
P
grad f|_P
gradf∣P。
∇
f
∣
P
=
g
r
a
d
f
∣
P
=
(
∂
f
∂
x
,
∂
f
∂
y
)
\nabla f|_P=grad f|_P=(\partial \frac{ f}{\partial x},\partial \frac{ f}{\partial y})
∇f∣P=gradf∣P=(∂∂xf,∂∂yf)
梯度向量指向函数值增加最快的方向,并且它的模(长度)表示这个最大变化率的大小。换句话说,梯度不仅告诉我们函数在哪一点增长得最迅速,还告诉我们这种增长的速度是多少。那么反方向就是函数下降最快的地方!(就是
−
∇
f
∣
P
-\nabla f|_P
−∇f∣P),我们在曲线拟合非线性函数时,可能很难直接找到损失函数的最小值,那么我们根据梯度的反方向就能更加快速的找到。
那么我们在点
P
(
2
,
3
)
P(2,3)
P(2,3)处的梯度为:
∇
f
∣
P
(
2
,
3
)
=
g
r
a
d
f
∣
P
(
2
,
3
)
=
(
∂
f
∂
x
,
∂
f
∂
y
)
=
(
x
x
2
+
y
2
,
y
x
2
+
y
2
)
=
(
2
13
,
3
13
)
\nabla f|_P(2,3)=grad f|_P(2,3)=(\partial \frac{ f}{\partial x},\partial \frac{ f}{\partial y})=(\frac{x}{\sqrt{x^2+y^2}},\frac{y}{\sqrt{x^2+y^2}})=(\frac{2}{\sqrt{13}},\frac{3}{\sqrt{13}})
∇f∣P(2,3)=gradf∣P(2,3)=(∂∂xf,∂∂yf)=(x2+y2x,x2+y2y)=(132,133)
3.方向导数
在
P
P
P点,沿着
l
⃗
\vec l
l方向的方向导数计算公式为:
∂
f
∂
l
∣
P
=
∂
f
∂
x
c
o
s
α
+
∂
f
∂
y
c
o
s
β
+
∂
f
∂
z
c
o
s
γ
\partial \frac {f}{\partial l}|_{P}= \frac{\partial f}{\partial x}cos{\alpha}+\frac{\partial f}{\partial y}cos{\beta}+\frac{\partial f}{\partial z}cos{\gamma}
∂∂lf∣P=∂x∂fcosα+∂y∂fcosβ+∂z∂fcosγ
其中
(
c
o
s
α
,
c
o
s
β
,
c
o
s
γ
)
(cos{\alpha},cos{\beta},cos{\gamma})
(cosα,cosβ,cosγ)是
l
⃗
\vec l
l与三个坐标轴之间夹角的方向余弦。比如
l
⃗
=
(
3
,
4
,
5
)
\vec{l} =(3,4,5)
l=(3,4,5),那么:
∣
l
⃗
∣
=
3
2
+
4
2
+
5
2
=
5
2
c
o
s
α
=
x
l
∣
l
⃗
∣
=
3
5
2
=
3
2
10
c
o
s
β
=
y
l
∣
l
⃗
∣
=
4
5
2
=
4
2
10
c
o
s
γ
=
z
l
∣
l
⃗
∣
=
5
5
2
=
5
2
10
|\vec{l}|=\sqrt{3^2+4^2+5^2}=5\sqrt2\\ cos{\alpha}=\frac{x_l}{|\vec{l}|}=\frac{3}{5\sqrt{2}}=\frac{3\sqrt{2}}{10}\\ cos{\beta}=\frac{y_l}{|\vec{l}|}=\frac{4}{5\sqrt{2}}=\frac{4\sqrt{2}}{10}\\ cos{\gamma}=\frac{z_l}{|\vec{l}|}=\frac{5}{5\sqrt{2}}=\frac{5\sqrt{2}}{10}\\
∣l∣=32+42+52=52cosα=∣l∣xl=523=1032cosβ=∣l∣yl=524=1042cosγ=∣l∣zl=525=1052
我们在
P
=
(
2
,
3
)
P=(2,3)
P=(2,3)点处沿着方向
l
⃗
(
5
,
6
)
\vec{l}(5,6)
l(5,6)的方向导数为:
∂
f
∂
l
∣
P
=
(
2
,
3
)
=
∂
f
∂
x
c
o
s
α
+
∂
f
∂
y
c
o
s
β
=
x
x
2
+
y
2
x
l
∣
l
⃗
∣
+
y
x
2
+
y
2
y
l
∣
l
⃗
∣
=
2
2
2
+
3
2
5
61
+
3
2
2
+
3
2
6
61
=
28
793
\partial \frac {f}{\partial l}|_{P=(2,3)}= \frac{\partial f}{\partial x}cos{\alpha}+\frac{\partial f}{\partial y}cos{\beta}\\ =\frac{x}{\sqrt{x^2+y^2}}\frac{x_l}{|\vec{l}|}+\frac{y}{\sqrt{x^2+y^2}}\frac{y_l}{|\vec{l}|}\\ =\frac{2}{\sqrt{2^2+3^2}}\frac{5}{\sqrt{61}}+\frac{3}{\sqrt{2^2+3^2}}\frac{6}{\sqrt{61}}\\ =\frac{28}{\sqrt{793}}\\
∂∂lf∣P=(2,3)=∂x∂fcosα+∂y∂fcosβ=x2+y2x∣l∣xl+x2+y2y∣l∣yl=22+322615+22+323616=79328
上面呢我们回归了梯度的一下概念,也模糊的、大概地知道梯度下降法是通过求梯度一步一步迭代更新参数来逐次使得L->0,即慢慢的让曲线去契合我们的原始数据。在真正去写梯度下降法的代码时,我们也像2.1节中那样,先实验一个小例子,把我们代入到处理器的视角里,看看我们人为迭代的过程。
3.2实例演示
我们假设有m组数据
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
.
.
.
(
x
m
,
y
m
)
(x_1,y_1),(x_2,y_2),...(x_m,y_m)
(x1,y1),(x2,y2),...(xm,ym),这组数据的预测模型是
f
(
x
)
=
a
x
2
+
b
x
+
c
f(x)=ax^2+bx+c
f(x)=ax2+bx+c,我们要通过最小二乘-梯度下降法像求2.1节例子中k,b似的,求出
K
=
[
a
,
b
,
c
]
K=[a,b,c]
K=[a,b,c]这三个参数。
(
x
1
,
y
1
)
=
(
−
2
,
13
)
(
x
2
,
y
2
)
=
(
−
1
,
4
)
(
x
3
,
y
3
)
=
(
0
,
1
)
(
x
4
,
y
4
)
=
(
1
,
4
)
(
x
5
,
y
5
)
=
(
2
,
13
)
(x_1,y_1)=(-2,13)\\ (x_2,y_2)=(-1,4)\\ (x_3,y_3)=(0,1)\\ (x_4,y_4)=(1,4)\\ (x_5,y_5)=(2,13)\\
(x1,y1)=(−2,13)(x2,y2)=(−1,4)(x3,y3)=(0,1)(x4,y4)=(1,4)(x5,y5)=(2,13)
(1)构造损失函数。这里的数据其实是
f
(
x
)
=
3
x
2
+
1
生成的
f(x)=3x^2+1生成的
f(x)=3x2+1生成的,也就是
K
=
[
a
,
b
,
c
]
=
[
3
,
0
,
1
]
K=[a,b,c]=[3,0,1]
K=[a,b,c]=[3,0,1],我们还是试一下梯度下降法能不能迭代出来这个参数来。
首先我们要构造我们的损失函数:
L
(
a
,
b
,
c
)
=
∑
i
=
1
m
(
f
(
x
i
)
−
y
i
)
2
=
(
a
x
1
2
+
b
x
1
+
c
−
y
1
)
2
+
(
a
x
2
2
+
b
x
2
+
c
−
y
2
)
2
+
.
.
.
(
a
x
5
2
+
b
x
5
+
c
−
y
5
)
2
=
(
4
a
−
2
b
+
c
−
13
)
2
+
(
a
−
b
+
c
−
4
)
2
+
(
c
−
1
)
2
+
(
a
+
b
+
c
−
4
)
2
+
(
4
a
+
2
b
+
c
−
13
)
2
=
16
a
2
+
4
b
2
+
c
2
+
169
−
16
a
b
+
8
a
c
−
104
a
−
4
b
c
+
52
b
−
26
c
L(a,b,c)=\sum_{i=1}^m(f(x_i)-y_i)^2=(ax_1^2+bx_1+c-y_1)^2+(ax_2^2+bx_2+c-y_2)^2+...(ax_5^2+bx_5+c-y_5)^2\\ =(4a-2b+c-13)^2+(a-b+c-4)^2+(c-1)^2+(a+b+c-4)^2+(4a+2b+c-13)^2\\ =16a^2+4b^2+c^2+169−16ab+8ac−104a−4bc+52b−26c
L(a,b,c)=i=1∑m(f(xi)−yi)2=(ax12+bx1+c−y1)2+(ax22+bx2+c−y2)2+...(ax52+bx5+c−y5)2=(4a−2b+c−13)2+(a−b+c−4)2+(c−1)2+(a+b+c−4)2+(4a+2b+c−13)2=16a2+4b2+c2+169−16ab+8ac−104a−4bc+52b−26c
(2)求梯度函数。这个时候L就是关于a,b,c的函数了。接下来我们就求L的最小值就行了,但是我们用尽办法,都求不出来(L函数太麻烦了)。那么可以试几个
K
n
=
[
a
n
,
b
n
,
c
n
]
K_n=[a_n,b_n,c_n]
Kn=[an,bn,cn],如果能让L一直减小,直到L小到一定数量级,比如
L
<
1
L<1
L<1,如果此时的精度如果能满足我们应用的精度,那么我们就可以认为此时的
K
n
=
[
a
n
,
b
n
,
c
n
]
K_n=[a_n,b_n,c_n]
Kn=[an,bn,cn]就可以用了,其中n是我们尝试的次数,也就是迭代的次数。但是我们在尝试参数的时候,总不能随便乱试吧,我们总得有一个目标,或者有一个路线,那么我们可以按照梯度下降最快的方向去试。
梯度向量为:
∂
L
∂
a
=
∑
i
=
1
m
2
(
a
x
i
2
+
b
x
i
+
c
−
y
i
)
x
i
2
∂
L
∂
b
=
∑
i
=
1
m
2
(
a
x
i
2
+
b
x
i
+
c
−
y
i
)
x
i
∂
L
∂
c
=
∑
i
=
1
m
2
(
a
x
i
2
+
b
x
i
+
c
−
y
i
)
\partial \frac{L}{\partial a}=\sum_{i=1}^m2(ax_i^2+bx_i+c-y_i)x_i^2\\ \partial \frac{L}{\partial b}=\sum_{i=1}^m2(ax_i^2+bx_i+c-y_i)x_i\\ \partial \frac{L}{\partial c}=\sum_{i=1}^m2(ax_i^2+bx_i+c-y_i)\\
∂∂aL=i=1∑m2(axi2+bxi+c−yi)xi2∂∂bL=i=1∑m2(axi2+bxi+c−yi)xi∂∂cL=i=1∑m2(axi2+bxi+c−yi)
(3)设定初始值和学习步长。比如我们第一次尝试
K
0
=
[
a
0
,
b
0
,
c
0
]
=
[
1
,
1
,
1
]
K_0=[a_0,b_0,c_0]=[1,1,1]
K0=[a0,b0,c0]=[1,1,1](这个也就是初始值,如果我们知道曲线的f(x)的a大概范围如果在100左右,我们可以让a0=100,这样迭代的次数会大大降低)。
接下来就要开始按照我们梯度最小方向进行参数
K
=
[
a
,
b
,
c
]
K=[a,b,c]
K=[a,b,c]的迭代了,那我们这里还有思考一个非常重要的问题,我们参数减小的方向知道了,但是每次要减小多少呢?这里减小的多少就是我们的 迭代步长也叫学习步长、学习率 ,它是决定在参数空间中每一步更新的大小的关键参数。选择合适的学习率对于确保模型能够有效地收敛到最小化损失函数的解非常重要。其实,如何确定一个合适的学习率并不是一件简单的事情,很多算法就是为了找这个迭代步长,因为太大的学习率可能会导致算法跳过最小值,这样就迭代不出最佳的拟合曲线了,而太小的学习率则会导致收敛过程非常缓慢,甚至数据都用完了可能都没拟合出曲线来。以下是几种确定学习率的方法(AI的回答):
- 手动调整:这是最直接的方式,开始时选择一个相对较小的学习率,然后逐步增加,直到找到一个既能保证收敛速度又不会导致震荡的学习率。
- 网格搜索(Grid Search):尝试一系列预定义的学习率值,并评估每个值下的模型性能,从中选择表现最好的。
- 随机搜索(Random Search):与网格搜索类似,但是不是遍历所有可能的值,而是随机选择一些值进行测试。
- 基于验证集的表现:使用验证集来监控不同学习率下模型的表现,选择使得验证误差最小的那个学习率。
- 自适应学习率方法:有一些优化算法可以自动调整学习率,比如AdaGrad、RMSProp、Adam等。这些算法根据梯度的历史信息动态调整每个参数的学习率。
- 学习率衰减(Learning Rate Decay):设定一个初始学习率,并随着训练过程逐渐减少它。这可以通过多种策略实现,例如指数衰减、分段常数衰减等。
- 循环学习率(Cyclical Learning Rates):这种方法让学习率在一个范围内周期性变化,有时能帮助跳出局部极小值。
- Warm-Up:在训练初期使用非常小的学习率,然后逐渐增加到预定的最大值,这样可以帮助模型更稳定地开始训练。
除了1,其他的看起来都不简单。但是在一般工程中呢(数据量不是特别特别大),我们可以慢慢的去试一个值,比如这里我们去学习步长为 γ = 0.01 \gamma=0.01 γ=0.01。
①把我们的初试参数
K
0
=
[
a
0
,
b
0
,
c
0
]
=
[
1
,
1
,
1
]
K_0=[a_0,b_0,c_0]=[1,1,1]
K0=[a0,b0,c0]=[1,1,1]代入进L,此时我们的损失函数和梯度函数中:
L
(
a
0
,
b
0
,
c
0
)
=
146
∂
L
∂
a
∣
a
0
=
1
=
∑
i
=
1
m
2
(
a
x
i
2
+
b
x
i
+
c
−
y
i
)
x
i
2
=
−
80
∂
L
∂
b
∣
b
0
=
1
=
∑
i
=
1
m
2
(
a
x
i
2
+
b
x
i
+
c
−
y
i
)
x
i
=
48
∂
L
∂
c
∣
c
0
=
1
=
∑
i
=
1
m
2
(
a
x
i
2
+
b
x
i
+
c
−
y
i
)
=
−
36
∇
f
∣
(
a
0
,
b
0
,
c
0
)
=
(
∂
L
∂
a
,
∂
L
∂
b
,
∂
L
∂
c
)
=
[
−
80
,
48
,
−
36
]
L(a_0,b_0,c_0)=146\\ \partial \frac{L}{\partial a}|_{a_0=1}=\sum_{i=1}^m2(ax_i^2+bx_i+c-y_i)x_i^2=-80\\ \partial \frac{L}{\partial b}|_{b_0=1}=\sum_{i=1}^m2(ax_i^2+bx_i+c-y_i)x_i=48\\ \partial \frac{L}{\partial c}|_{c_0=1}=\sum_{i=1}^m2(ax_i^2+bx_i+c-y_i)=-36\\ \nabla f|_{(a_0,b_0,c_0)}=(\partial \frac{L}{\partial a},\partial \frac{L}{\partial b},\partial \frac{L}{\partial c})=[-80,48,-36]
L(a0,b0,c0)=146∂∂aL∣a0=1=i=1∑m2(axi2+bxi+c−yi)xi2=−80∂∂bL∣b0=1=i=1∑m2(axi2+bxi+c−yi)xi=48∂∂cL∣c0=1=i=1∑m2(axi2+bxi+c−yi)=−36∇f∣(a0,b0,c0)=(∂∂aL,∂∂bL,∂∂cL)=[−80,48,−36]
②我们发现损失函数L=146要远大于1,所以我们需要继续更新参数K,并将新的参数K1代入到损失函数和梯度中,进行下一次迭代:
K
1
=
[
a
1
,
b
1
,
c
1
]
=
K
0
−
γ
∇
f
=
[
1
,
1
,
1
]
−
0.01
∗
[
−
80
,
48
,
−
36
]
=
[
1.8
,
0.52
,
1.36
]
L
(
a
1
,
b
1
,
c
1
)
=
43.6720
∂
L
∂
a
∣
a
1
=
−
433.84
∂
L
∂
b
∣
b
1
=
32.8
∂
L
∂
c
∣
c
1
=
−
39.76
K_1=[a_1,b_1,c_1]=K_0-\gamma \nabla f=[1,1,1]-0.01*[-80,48,-36]=[1.8,0.52,1.36]\\ L(a_1,b_1,c_1)=43.6720\\ \partial \frac{L}{\partial a}|_{a_1}=-433.84\\ \partial \frac{L}{\partial b}|_{b_1}=32.8\\ \partial \frac{L}{\partial c}|_{c_1}=-39.76\\
K1=[a1,b1,c1]=K0−γ∇f=[1,1,1]−0.01∗[−80,48,−36]=[1.8,0.52,1.36]L(a1,b1,c1)=43.6720∂∂aL∣a1=−433.84∂∂bL∣b1=32.8∂∂cL∣c1=−39.76
我们可以看到L在往小的地方走了,但是L还是大于1,继续迭代。
③我们更新我们的参数K,并将新的参数K2代入到损失函数和梯度中:
K
2
=
[
a
2
,
b
2
,
c
2
]
=
K
0
−
γ
∇
f
=
[
1.8
,
0.52
,
1.2
]
−
0.01
∗
[
−
35.12
,
33.16
,
−
40.8
]
=
[
2.2384
,
0.1924
,
1.7576
]
L
(
a
1
,
b
1
,
c
1
)
=
11.4198
∂
L
∂
a
∣
a
2
=
−
21.3824
∂
L
∂
b
∣
b
2
=
24.7520
∂
L
∂
c
∣
c
2
=
−
6.328
K_2=[a_2,b_2,c_2]=K_0-\gamma \nabla f=[1.8,0.52,1.2]-0.01*[-35.12,33.16,-40.8]=[2.2384,0.1924,1.7576]\\ L(a_1,b_1,c_1)=11.4198\\ \partial \frac{L}{\partial a}|_{a_2}=-21.3824\\ \partial \frac{L}{\partial b}|_{b_2}=24.7520\\ \partial \frac{L}{\partial c}|_{c_2}=-6.328\\
K2=[a2,b2,c2]=K0−γ∇f=[1.8,0.52,1.2]−0.01∗[−35.12,33.16,−40.8]=[2.2384,0.1924,1.7576]L(a1,b1,c1)=11.4198∂∂aL∣a2=−21.3824∂∂bL∣b2=24.7520∂∂cL∣c2=−6.328
我们可以看到
K
=
[
a
,
b
,
c
]
K=[a,b,c]
K=[a,b,c]已将往着
K
=
[
3
,
0
,
1
]
K=[3,0,1]
K=[3,0,1]的方向在走了,继续迭代下去就可以完成我们的曲线拟合(但是由于原始数据量比较少,所以拟合结果可能有较大的偏差)。
…
如果我们把原始数据弄多一些,学习步长设置到0.001,迭代10步后的结果如下,红色是拟合的结果,蓝色是原始数据:

④跳出迭代。我们发现损失函数到了L=0.7665<1,那么此时达到我们要求的精度了,可以跳出迭代循环,保存
K
10
=
[
a
10
,
b
10
,
c
10
]
=
[
2.998
,
−
0.0081
,
1.10479
]
K_{10}=[a_{10},b_{10},c_{10}]=[2.998,-0.0081,1.10479]
K10=[a10,b10,c10]=[2.998,−0.0081,1.10479]。
下一节,我们把理论转换成matlab程序。看看在理论转换成程序过程中,需要注意什么,需要做出那些变动。
3.3梯度下降法matlab程序
在写程序前呢,我们重新梳理一下最小二乘法-梯度下降法的思路:
-
(1)构造损失函数 L = ∑ i = 0 m ( y i − f ( x i ) ) L=\sum_{i=0}^{m}(y_i-f(x_i)) L=∑i=0m(yi−f(xi))
-
(2)求梯度 ∇ f = ( ∂ L ∂ a , ∂ L ∂ b , ∂ L ∂ c . . . ) \nabla f=(\partial \frac{L}{\partial a},\partial \frac{L}{\partial b},\partial \frac{L}{\partial c}...) ∇f=(∂∂aL,∂∂bL,∂∂cL...)
-
(3)设定初试参数 K 0 K_0 K0以及学习步长 γ \gamma γ
-
(4)将 K n K_n Kn代入到损失函数和梯度函数中
-
(5)算出新的损失函数值和梯度值,并更新参数 K n + 1 = K n − γ ∇ f ∣ ( a n , b n , c n ) K_{n+1}=K_n-\gamma \nabla f|_{(a_n,b_n,c_n)} Kn+1=Kn−γ∇f∣(an,bn,cn)
-
(6)判断损失函数L是否小于到了可以接受的数值,如L达到了我们预设值,那么跳转到(7),没到预设值返回到(4)
-
(7)结束
clear;
% 假设我们有以下数据
x = -2:0.01:2; % 时间向量
y = 10*x.^2 + 1 + 0.1*randn(size(x)); % 含噪声的真实数据
% 初始化参数
a = 3; % 随机初始化 a
b = 1; % 随机初始化 b
c = 0; % 随机初始化 c
learning_rate = 0.01; % 学习步长
iterations = 1000; % 迭代次数
m = length(x); % 数据点的数量
% 梯度下降主循环
for iter = 1:iterations
% 计算预测值
y_pred = a*x.^2 + b*x + c;
% 构造损失函数
loss = sum( (y_pred - y).^2 );
% 计算梯度
grad_a = sum(2*(y_pred - y).*x.^2)/ m;
grad_b = sum(2*(y_pred - y).*x)/ m ;
grad_c = sum(2*(y_pred - y) )/ m;
% 更新参数
a = a - learning_rate * grad_a;
b = b - learning_rate * grad_b;
c = c - learning_rate * grad_c;
% 打印迭代信息(可选)
if mod(iter, 10) == 0
fprintf('Iteration %d | Loss: %.4f\n', iter, loss);
end
% 如果损失足够小,可以提前终止
if loss < 0.1
break;
end
end
% 输出最终结果
fprintf('Final parameters: a=%.4f, b=%.4f, c=%.4f\n', a, b, c);
% 绘制拟合曲线与原始数据对比图
figure;
scatter(x, y, 'filled'); hold on;
plot(x, a*x.^2 + b*x + c, '-r', 'LineWidth', 2);
legend('Data Points', 'Fitted Curve');
xlabel('x');
ylabel('y');
title('Quadratic Fit Using Gradient Descent');

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









