






前言
神经网络求解最优参数的方法是利用梯度下降法,梯度下降法其实是计算损失函数(Loss Function/Cost Function)的梯度。
常见的损失函数有:最小二乘法,极大似然估计法,交叉熵;
这三个损失函数是怎么设计出来的呢?有什么不同呢?
一、最小二乘法
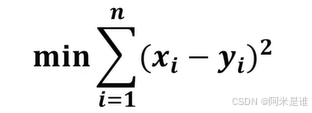
用最小二乘法评估设计模型与实际值之间的差别是最好理解的,就是类似数学上方差的概念。
在回归问题上,线性模型用最小二乘法作为损失函数,函数是数学意义上的凹函数,有利于得到最优解,因此最小二乘法是具有使用场景的。
(针对分类问题,如果用最小二乘法作为损失函数,得到的函数并不是凹函数,因此引入了新的函数)
二、极大似然估计
极大似然估计(Maximum Likelihood Estimate,MLE),通俗理解来说,就是利用已知的样本结果信息,反推最具有可能(最大概率)导致这些样本结果出现的模型参数值!
先通俗的理解下极大似然估计:
以抛硬币举例,问:抛硬币5次,什么情况下能得到抛出5次出现的情况是:正正反反正?
假设:正的概率是:P 反的概率是:1-P那么P(正正反反正)=P*P*(1-P)*(1-P)*P
简单粗暴的计算发现,P=0.6是对应的概率最大,那么对应正正反反正这个结果的模型是P=0.6.
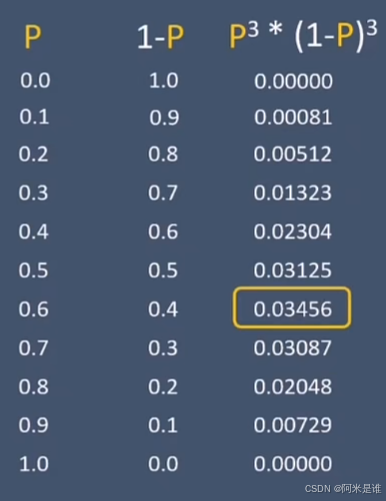
将上面的思路带到图片识别或者二分的问题上:
上图中提前假设的概率P其实就是神经网络中的W,b。在最开始P是未知的,W,b也是未知的。上图通过算出最大的P*P*(1-P)*(1-P)*P来映射到P的值,而下面的公式其实就是在得到类似与P*P*(1-P)*(1-P)*P的表达式。
当有了对应的表达式,那么求最优解就是求这个表达式的最大似然值的解。!!!
与扔硬币一样,通过结果反推模型,结果是正正反反正,概率就是P*P*(1-P)*(1-P)*P;那么图片识别对应的是数据集。简单点如果有10张图(是由人为打标签的),对应的是 是猫 是猫 不是猫 是猫 是猫 不是猫 是猫 不是猫 不是猫 是猫。 这10张图用W/B模型算出的概率为:

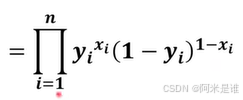
上面的表达式其实就是将x=0 和x=1 合在一个表达式,更所谓的P*(1-P)*... 这种并没有什么太多差别,别被吓到。。
我们更加喜欢连加,因此就加了Log.
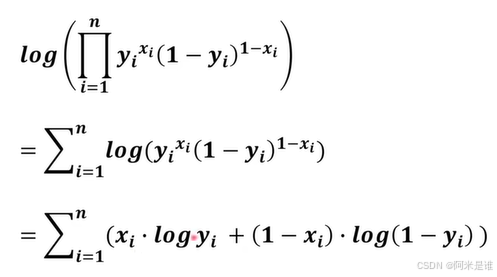
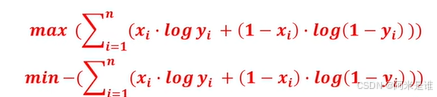
我们的目的是为了求极大似然值,极大似然值对应的w/b就是最优解!!~~
三、交叉熵
1.熵
信息量:
基于信息量的3个特点:小概率事件具有大的信息量;大概率事件具有小的信息量;信息量可以通过不同的信息的信息量相加得到。
信息量的表达式:
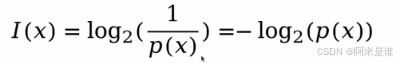
香农熵的表达式:
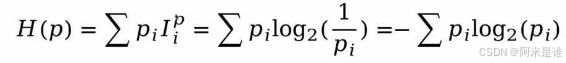
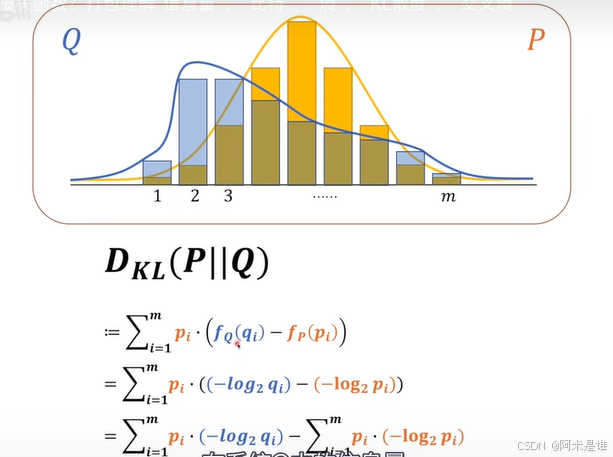
2.相对熵(KL散度)
量化的评价两个概率分布区别的函数
3.交叉熵(Cross Entropy)
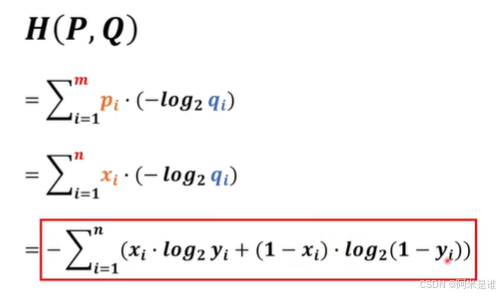
四、总结
从公式发现,交叉熵和极大似然估计表达式极其的一致。所以也许极大似然估计和交叉熵就是一个,也算是殊途同归!!!
参考:
【“损失函数”是如何设计出来的?直观理解“最小二乘法”和“极大似然估计法”】https://www.bilibili.com/video/BV1Y64y1Q7hi?vd_source=9851d72d2a2b26ad67f482059d420c94
【“交叉熵”如何做损失函数?打包理解“信息量”、“比特”、“熵”、“KL散度”、“交叉熵”】https://www.bilibili.com/video/BV15V411W7VB?vd_source=9851d72d2a2b26ad67f482059d420c94

















 503
503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









