








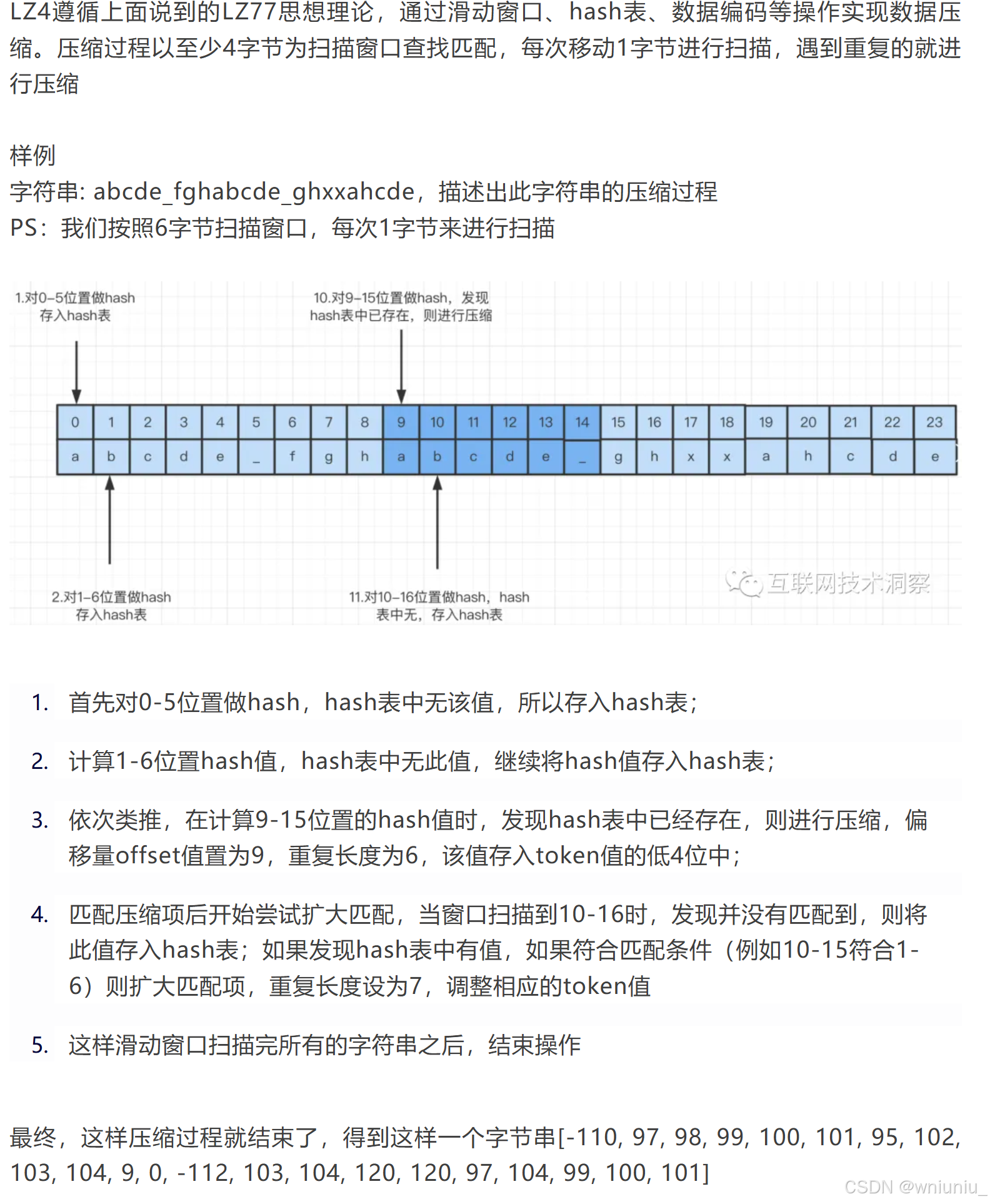
上面是lz4压缩序列的示意图
这张图展示了LZ4序列(LZ4 Sequence)的结构组成,以下结合图来详细解释:
1. Token(令牌)
- 位置:位于序列的起始位置,占用1个字节。
- 作用:令牌被分为两个4位的字段。其中,4 - high - bits(高4位)用于表示字面量长度(literal length),4 - low - bits(低4位)用于表示匹配长度(match length) 。例如,如果令牌的高4位是0101,那就表示字面量长度为5(二进制0101转换为十进制是5);低4位若为0011,则表示匹配长度为3(二进制0011转换为十进制是3)。
2. Literal length+ (optional)(字面量长度 这个只有在令牌的高位不够用的时候才会有)
- 位置:紧跟在Token之后。
- 长度:占用0 - n个字节。
- 作用:当令牌的高4位为15(二进制1111)时,说明字面量长度超过了4位所能表示的范围(0 - 15),此时就需要额外的字节来完整表示字面量长度。例如,若实际字面量长度为20,令牌高4位是15,那么后面会紧跟一个或多个字节来补充表示完整的长度20。如果没有超出范围,这部分就不存在(即0字节)。
3. Literals(字面量)
- 位置:在Literal length+(如果存在的话)之后。
- 长度:占用0 - L个字节,L由Literal length确定。
- 作用:字面量是指在数据中没有重复出现,或者尚未找到重复模式的字节序列。例如,在一段文本数据中,如果遇到了一些独特的字符组合,这些字符组合就会作为字面量存储在这里。
4. Offset(偏移量)
- 位置:在Literals之后。
- 长度:固定占用2个字节,采用小端序(little endian)存储。
- 作用:偏移量用于指示从已解码的输出缓冲区中多远处开始复制匹配的数据。比如,在解压缩过程中,根据这个偏移量信息,从已解压的数据中找到对应的位置,去获取匹配的字节序列。
5. Match length+ (optional)(匹配长度 + 可选部分)
- 位置:在Offset之后。
- 长度:占用0 - n个字节。
- 作用:当令牌的低4位为15(二进制1111)时,说明匹配长度超过了4位所能表示的范围(0 - 15),此时就需要额外的字节来完整表示匹配长度。例如,若实际匹配长度为25,令牌低4位是15,那么后面会紧跟一个或多个字节来补充表示完整的长度25。如果没有超出范围,这部分就不存在(即0字节)。
总体来说,LZ4序列通过这种结构,将数据中的字面量信息和重复匹配信息进行编码存储,从而实现数据的压缩与解压缩 。
如果想要看例子可以看看这个



















 1942
1942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











