







 本文围绕增强语言模型(ALMs)展开,回顾其通过推理技能和使用工具增强能力。探讨了推理策略,如提示引发推理、递归提示等;介绍使用工具的方式,包括调用模型、信息检索等。还讨论了相关研究方向、好处及伦理问题,指出ALMs在未来交互系统中或起核心作用。
本文围绕增强语言模型(ALMs)展开,回顾其通过推理技能和使用工具增强能力。探讨了推理策略,如提示引发推理、递归提示等;介绍使用工具的方式,包括调用模型、信息检索等。还讨论了相关研究方向、好处及伦理问题,指出ALMs在未来交互系统中或起核心作用。
Augmented Language Models: a Survey 阅读与理解
原文链接:https://arxiv.org/abs/2302.07842
简要
本文回顾了大语言模型(LMs)能够通过推理技能和使用工具来增强其能力。这种模型可以被称为增强语言模型(Augmented Language Models ALMs)。他们依然以经典的掩码预测方式训练,学习推理事件和使用工具。
这些LMs涉及调用外部的可能是非参数化的模块,不同于经典的语言建模范式。
如何以完全自我监督的方式为语言模型配备有意义的增强仍然是一个开放的研究问题。 将推理和工具结合起来也是一个不错的方向。
内容
1 引言:调查的动机和定义
1.1动机
大语言模型LLMs带来了广泛的变革,记忆和创作能力赋予了LLMs解决多种任务的可能。但是LLMs仍有许多不足和限制,诸如幻觉等。而且LLMs需要一定的规模,其持续的学习也是一个开放性问题。Goldberg*(Yoav Goldberg. Some remarks on large language models, 2023.)*在关于ChatGPT 的上下文中讨论了LLMs的其他不足。
本文认为带来这些问题的原因之一是上下文的有限性,需要大规模存储上下文中不存在但手头任务所必需的知识。所以出现越来越多的研究来规避LLMs有限的上下文大小。一是通过为LMs配备检索模块从给定上下文的数据库中检索;二是通过推理策略改善上下文;三是LMs利用外部工具。
术语定义
Reasoning 推理 将潜在的复杂任务分解为简单的子任务,无论是通过递归还是迭代。但目前并不能完全的解释LLMs是否真的在推理抑或是对语言的滥用而已。
Tool 工具 一个通过某种规则或特殊标记来调用的外部模块。可以收集外部信息或对物理世界产生影响。LLMs学习与工具交互可能包括学习调用其API。
Act 行为 ALM调用虚拟或物理世界有影响的工具并观察结果,通常会将结果包含在ALM当前的上下文中。
为什么要联合讨论推理和工具
推理能够分解任务,工具可以正确执行任务。
为什么联合讨论工具和行为
LM可以相同的方式调用收集附加信息的工具和对虚拟和物理世界有影响的工具。LM具有行动的潜力。
1.2 章节分类
第二节研究了LM的推理能力,第三节关注LMs与工具的交互和行为,第四节探讨推理和工具的具体用途(启发式or学习(监督or强化)),第五节讨论其他探索路线。本文主要关注LLMs。
2 推理
增强LMs推理技能的各种策略。
2.1 通过提示引发推理
两种提示形式:zero-shot和few-shot。
启发性提示鼓励LMs在预测输出前给出中间步骤,这种可以使LMs在few-shot,zero-shot下均具有更好的推理能力。下面的段落将详细讨论。
Few-shot setting
思维链(chain-of-thought,CoT)是一种few-shot提示技术。如图一所示,输入之后是一系列的推理过程和最终结果。

有研究表明CoT的成功使用需要模型具有一定的规模。表一显示CoT优于标准提示方法

wang等(2022c)*( Self-consistency improves chain of thought reasoning in language models.)提出了自一致性CoT:采用不同推理路径并选择最一致的答案进行输出。Press等(2022)( Measuring and narrowing the compositionality gap in language models)*提出自我询问:回答问题前明确陈述后续问题。并依赖于一个框架(例如,“后续问题:”或“所以最终答案是:”),因此答案更容易解析。作者在他们引入的数据集上展示了对CoT的改进,旨在测量组合性差距。他们观察到,当增加模型的尺寸时,这个差距并没有缩小。请注意,Press等人(2022)**关注的是2-hop问题,即模型只需要组成两个事实即可获得答案的问题。有趣的是,Self-ask可以很容易地通过搜索引擎进行扩展(参见第3节)。ReAct (Yao等人,2022b)是另一种触发推理的少数提示方法,可以在推理步骤中查询三个工具:在Wikipedia中搜索和查找,并完成返回答案。
Zero-shot setting.
Kojima等人*(Large language models are zero-shot reasoners. )*将LMs中引出的推理思想扩展到zero-shot。方法是将“Let’s think step by step”输入,且LLM在GSM8K等任务上表现良好,但不如few-shot-CoT。如图

2.2 递归提示
采用问题分解的方法独立的解决子问题,将答案汇总生成最终答案;或者依次解决子问题,其中下一个子问题的解取决于前一个子问题的答案。
例如,在数学问题的背景下,最小到最大提示(Zhou et al)*( Least-to-most prompting enables complex reasoning in large language models.)*允许语言模型通过将复杂问题分解为子问题列表来解决比演示示例更难的问题。该算法首先采用少镜头提示将复杂问题分解成子问题,然后依次求解提取出来的子问题,利用前一子问题的解来回答下一子问题。
虽然许多早期的工作包括通过远程监督学习分解。和Zhou et al .(2022)一样,最近的许多研究都采用了in-context-learning。其中,还有进一步的差异。例如,Drozdov等人(2022)是Zhou等人(2022)的后续,但不同之处在于使用一系列提示对输入执行递归语法解析,而不是线性分解,并且通过各种启发式自动选择示例也有所不同。Dua等人(2022)与Zhou等人(2022)的同时工作,但不同之处在于将问题分解和回答阶段交织在一起,即下一个子问题预测可以访问以前的问题和答案,而不是独立于任何以前的答案生成所有子问题。另一方面,Yang等人(2022a)使用基于规则的原则和补槽提示进行分解,将问题转化为一系列SQL操作。Khot et al(2022)也使用提示符分解为具体的操作,但随后允许每个子问题被分解
2.3 明确地教授语言模型去推理
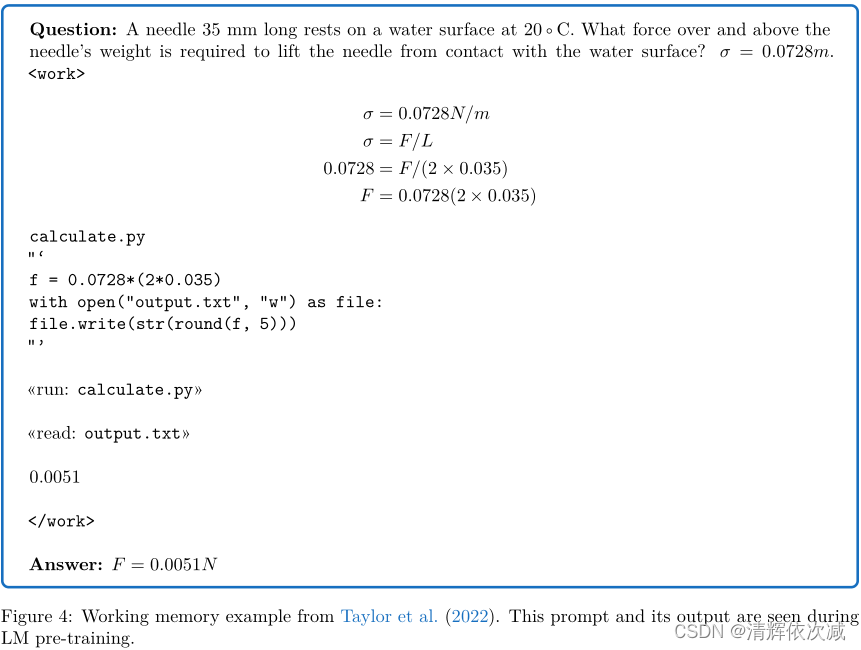
Nye等人引入了scratchpad的概念,允许LM更好地执行多步计算任务,如加法或代码执行。更准确地说,在训练时LM看到输入任务,比如加法,以及相关的中间步骤:这个集成被称为Scratchpad。在测试时,需要模型预测输入任务的步骤和答案。scratchpad与上述提示策略的不同之处在于,它们是对具有相关计算步骤的示例任务的微调。但请注意,Nye等人也在few-shot状态下进行了实验。Taylor等人在大型LM预训练模型的上下文中使用了类似方法:Galactica在科学数据语料库上进行训练,包括一些文档,其中推理步骤用特殊标记和包裹,以模仿内部工作存储。推理时,可以通过token显式地要求模型激活此推理模式。**Taylor等人认为,在对推理示例进行训练时,还会出现另一个问题:由于人类没有明确地写下所有推理步骤,因此从互联网收集的训练数据中可能缺少许多中间推理步骤。为了避免缺少步骤的问题,作者创建了具有详细推理过程的数据集。在Galactica的预训练中看到的提示示例如图4所示。
最近的其他工作通过微调提高了预训练的LMs的推理能力。Zelikman等人提出了一种bootstrap方法,为大量未标记的数据生成推理步骤(称为rationales),并使用该数据对模型进行微调。Yu等人表明,与预先训练的模型相比,对推理任务进行标准LM微调可以产生更好的推理技能,如文本蕴意、溯因推理和类比推理。此外,几种指令微调方法使用思维链式提示在BBH和MMLU 等流行基准上取得了显著的改进。有趣的是,所有这些工作也表明,小尺度指令微调模型比未微调的大尺度模型表现更好,特别是在指令跟随很重要的任务中。
2.4抽象推理的比较与局限性
探索尽可能多的推理路径是困难的,且不能保证中间步骤是有效的。一种产生可信的推理路径的方法是在每一步推理中产生问题及其对应的答案。但仍不能保证其正确性。推理是LMs在自己改善上下文来寻求更多的机会去输出正确的答案。但是它在多大程度上使用了所述的推理步骤人们仍然对此知之甚少(Alert: Adapting language models to reasoning tasks.)。
许多情况下,推理反而会出现本可避免的错误。例如计算步骤中的错误会影响后续答案。上面研究的一些作品(Yao 等人(ReAct);Press等人,2022)已经利用简单的外部工具,如搜索引擎或计算器来验证中间步骤。更一般地说,本文的下一部分侧重于LMs可以查询的各种工具,以增加输出正确答案的机会。
3 使用工具及其动作
3.1 调用另一个模型
LM的迭代调用
作为对单个优化Prompt进行优化的替代方法,LM获得更好结果的直观方法包括反复调用模型以迭代地改进其输出。
Re3 (Yang et al ., 2022c)利用这个想法自动生成了超过两千字的故事。准确地说,Re3首先通过提示GPT3产生一个计划、故事设置和人物。然后,Re3迭代地将来自计划和当前故事状态的信息注入到新的GPT3 Prompt中,以生成新的故事段落。Yang等人(2022b)对这项工作进行了改进,他们使用了一个学习过的详细大纲,迭代地将简短的初始大纲扩展到任何所需的粒度(granularity)级别。其他教模型以无监督的方式迭代改进文本的方法包括空白填充等应用(Shen等人,2020;Donahue et al, 2020)将高斯向量序列去噪为词向量(Li et al, 2022c)。例如,PEER (Schick et al, 2022)是一个基于LM-Adapted T5 (rafael et al, 2020)初始化的模型,并依托维基百科的编辑行为进行训练,学习如何进行编辑以及如何计划下一步。因此,PEER能够通过重复规划和编辑来开发文章,如图5所示。
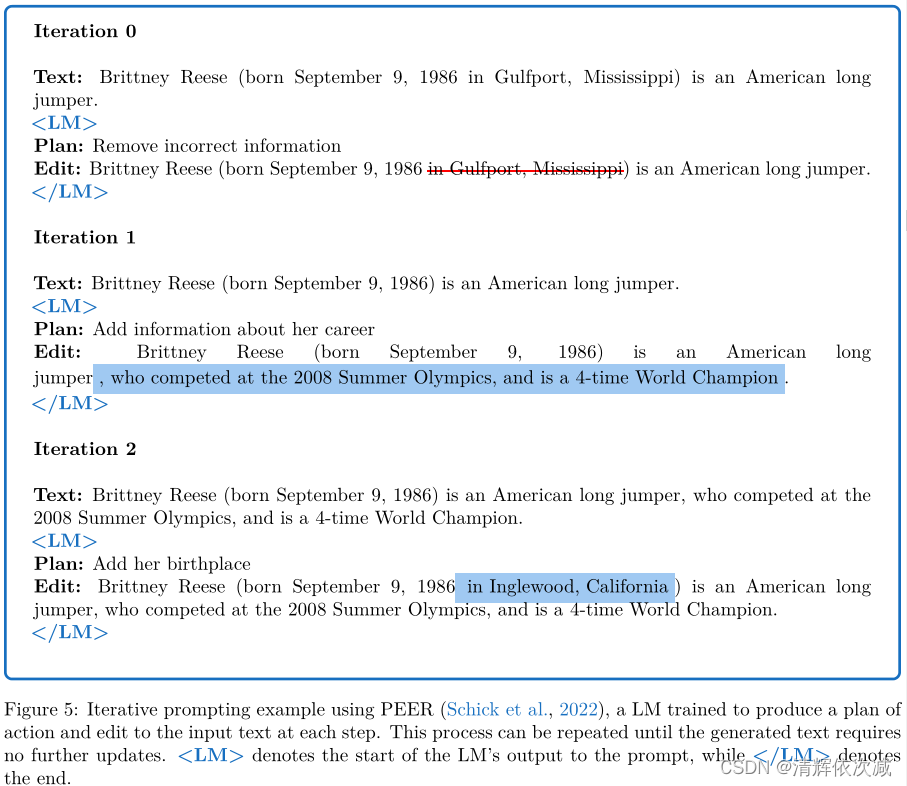
迭代方法还有一个额外的好处,就是允许像故事和文章生成这样的复杂任务分解成更小的子任务。重要的是,除了PEER之外,上面提到的作品还使用启发式方法来调用LM。未来的研究方向可能包括允许LM重复调用自己,直到输出满足某个标准。Wu等人(2022a)提出了一个用于管道的交互接口,允许将多个LMs链接在一起,其中一个步骤的输出作为输入传递给下一个步骤,而不仅仅是重复调用单个模型。这样的贡献允许非人工智能专家改进单个LM无法适当处理的复杂任务的解决方案。
利用其他模态
文本形式下的Prompt可能不包含足够的上下文来正确执行给定的任务。例如,如果一个问题是用严肃或讽刺的语气提出的,那么它需要不同的答案。在上下文中包含各种模态可能对诸如聊天机器人之类的LMs很有用。正如Hao等人(2022)和Alayrac等人(2022)最近所证明的,LMs也可以用作在不同模态上预训练的模型的通用接口。例如,Hao等人(2022)采用了许多预训练的Encoders,这些编码器可以处理视觉和语言等多种模态,并将它们连接到作为通用任务层的LM。接口和模块Encoder通过半因果(Semi-causal)语言建模目标进行联合预训练。这种方法结合了因果和非因果语言建模的优点,支持上下文学习和开放式生成,以及Encoder的轻松微调。类似地,Alayrac等人(2022)引入了Flamingo,这是一个视觉语言模型(VLMs)家族,可以处理任何交错的视觉和文本数据序列。Flamingo模型在包含交错文本和图像的大规模多模态网络语料库上进行训练,这使它们能够在上下文中显示多模态任务的few-shot能力。仅使用少量注释示例,Flamingo就可以轻松适应生成任务(如视觉问答和字幕)以及分类任务(如选择题视觉问答)。Zeng等人(2022)引入了苏格拉底模型(Socratic Models),这是一个模块化的框架,在这个框架中,各种模型在不同的模态上进行预训练,可以进行zero-shot Prompt。这允许模型彼此交换信息并获得新的多模态功能,而无需额外的微调。通过与外部api和数据库(如搜索引擎)的接口,苏格拉底模型可以实现新的应用程序,如机器人感知和规划,关于自我中心视频的自由形式问答,或多模态辅助对话。有趣的是,可以将图像等其他模态纳入到中等大小的LMs中来提
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 249
249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











