






导读
历史工资结果:系统工资结果有几种方式,每个方式都有他特定的业务场景,今天使用的方式更多的考虑业务人员的角度,如果快速的收集数据并导入数据。目前开发的程序有三个,一个导入SAP标准表数据(万能导入程序),一个是整理T558B、一个是整理T558D数据,第一个是通过abap程序,因为能重复利用,另外两个是python编写的一次性程序。
作者:vivi,来源:osinnovation
1 主数据
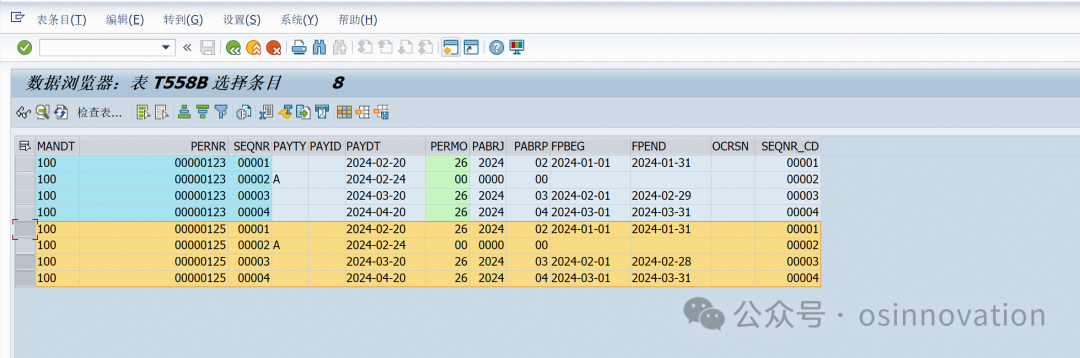
导入工资结果主要是T558B、T558D,T558B是记录员工时间记录信息,例如工资核算12个月,那么就需要再系统导入12条数据。下图介绍下几个重要的字段,payty如果是奖金就填写A,如果是工资为空即可,paydt是工资的支付日期,permo是工资发放周期(例如本月发本月工资,发上月工资等)。如果是年终奖不需要填写,pabrj是工资发放年度,pabrp是发放月份,fpbeg是发放月的第一天,fpend是发放月的最后一天,seqnr_cd是工资的序号,是个流水号。
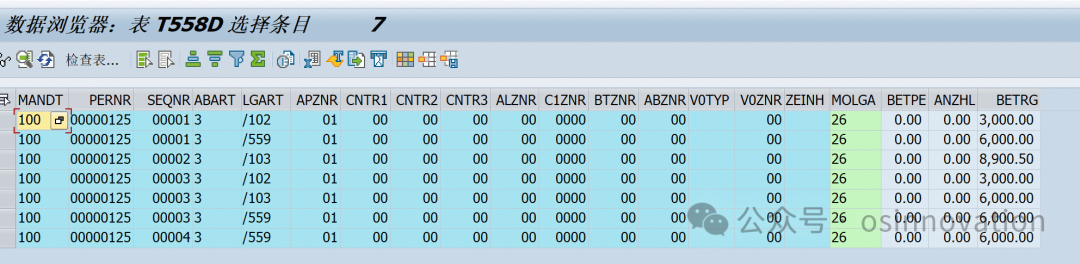
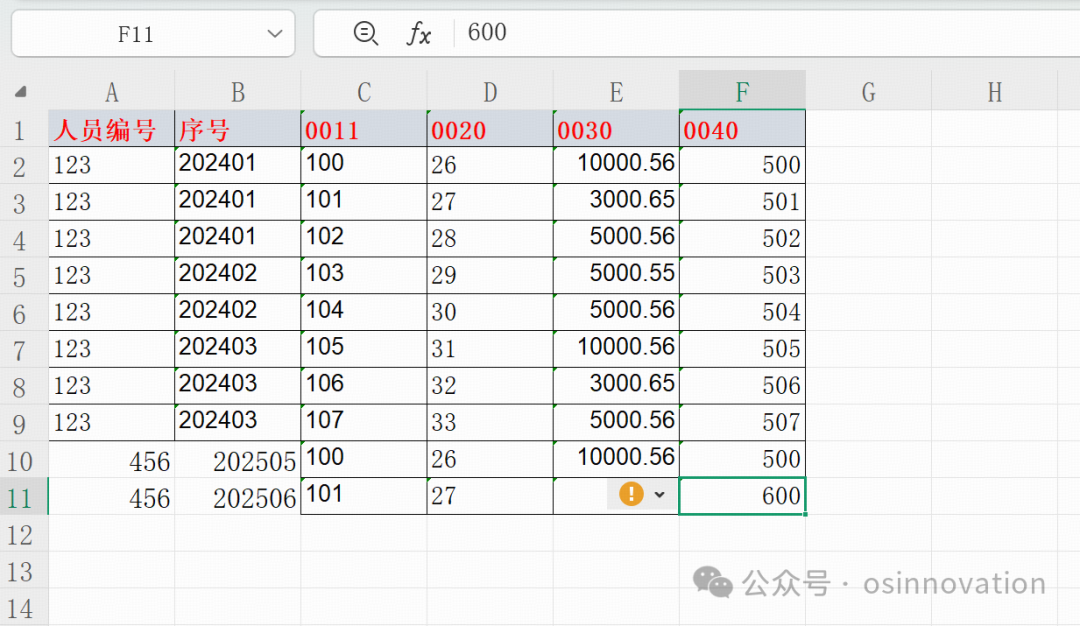
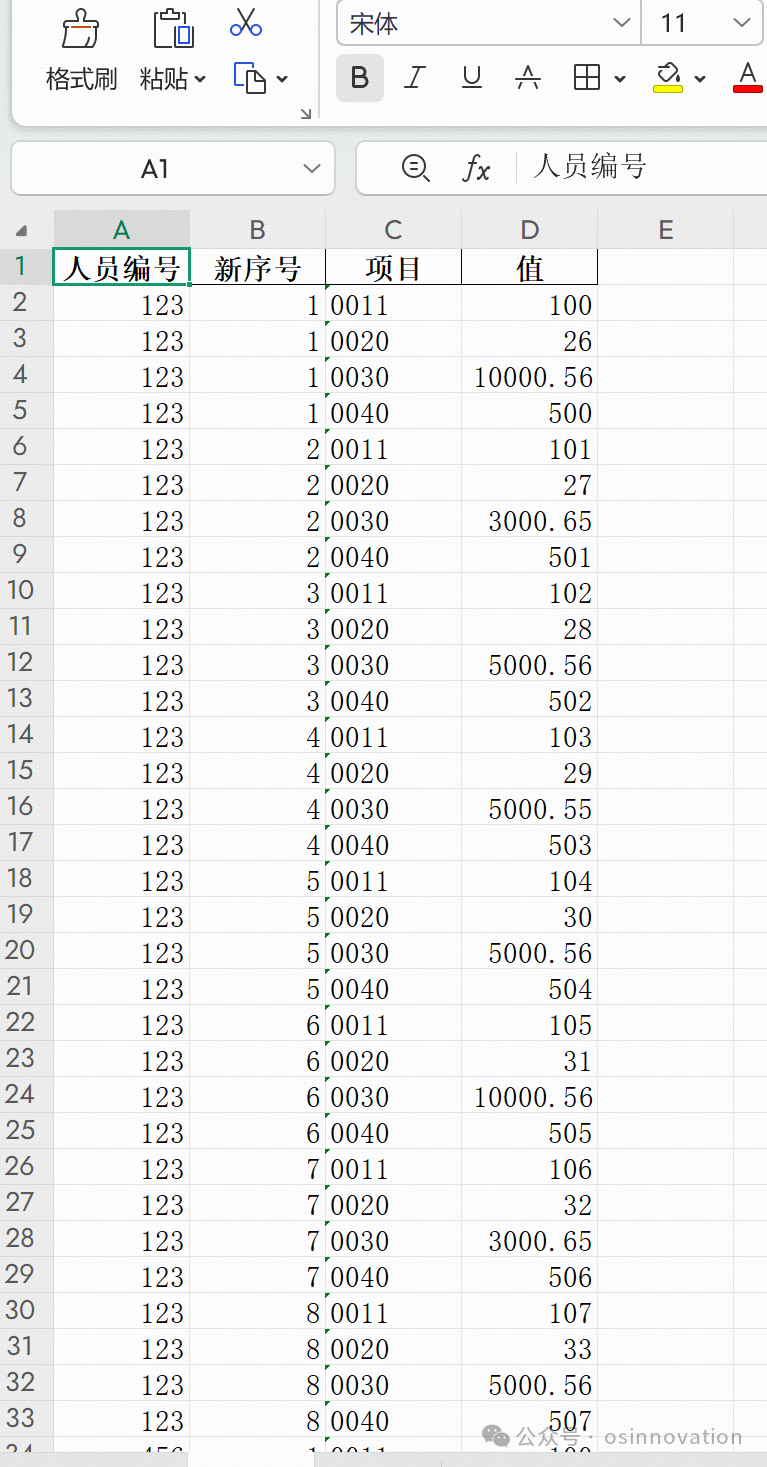
T588D是根据seqnr与t588bseqnr_cd关联,然后就是多条工资项目,导入模版是多条存储方式,对产品设计角度而言没毛病,因为可以适配不同的企业,但是对于业务人员,想从列转到行的其实操作不是很方便,所以通过一个python写一个脚本把列转换成行。
2 SCHEMA拷贝
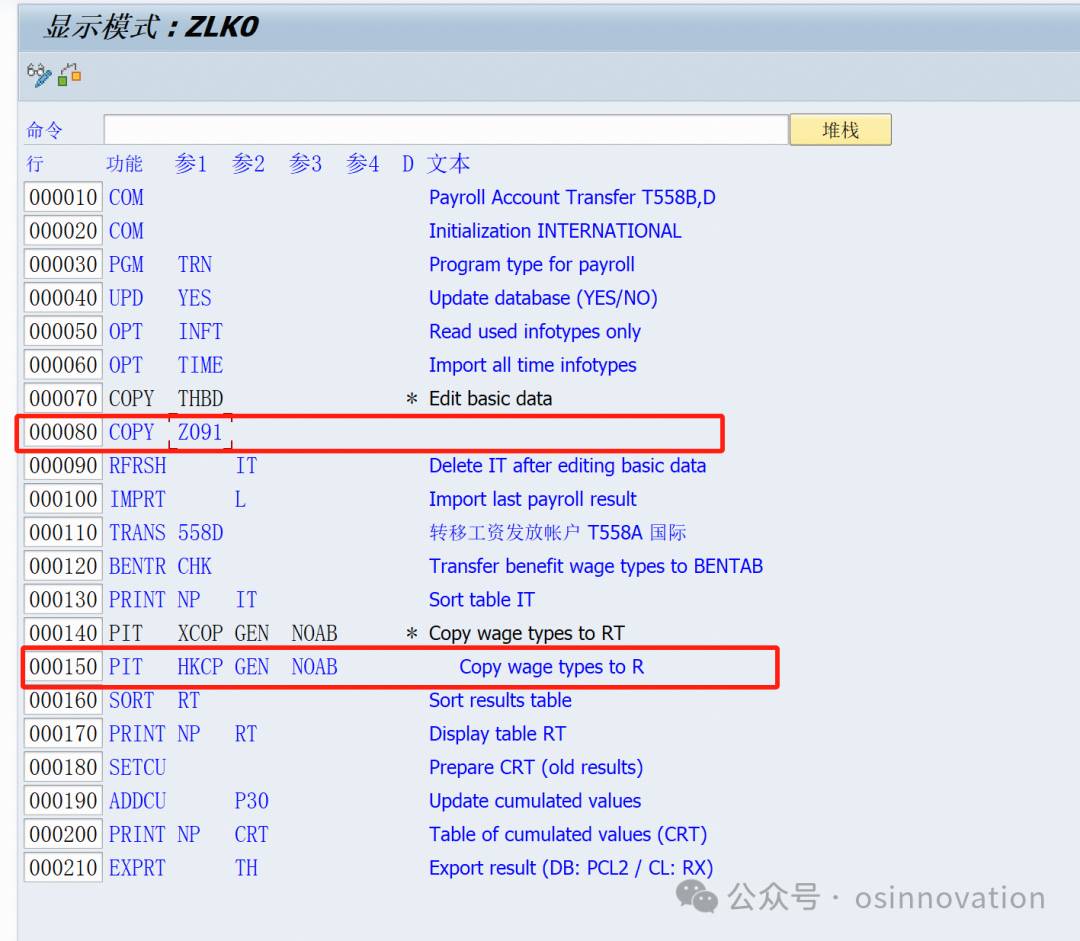
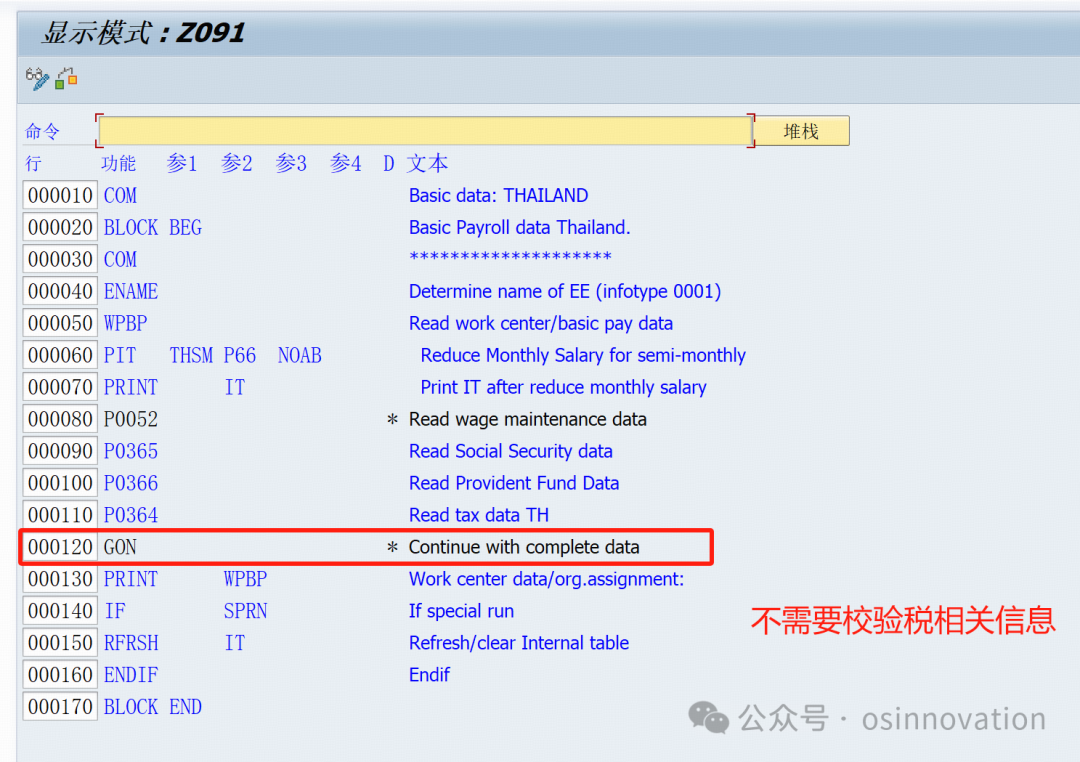
因为标准提供一个版本,我们只需要复制对应的版本,然后稍微调整一下即可,我就是复制XLK0,我只要修改两个地方,一个是主数据的校验,不需要维护税相关信息,一个是RT表写入的时候有相关的序号。
3 自定义程序
①导入t558d与t558b的程序,导入模版第一行是表的字段名称,第二行是开始导入数据。因为叫万能程序,所以原则上可以导入任何表。
PARAMETER: P_TABLE(20).PARAMETER: p_file LIKE rlgrap-filename DEFAULT 'C:\config.xls'.SELECTION-SCREEN ULINE /1(70).SELECTION-SCREEN COMMENT /1(70) TEXT-001.SELECTION-SCREEN COMMENT /1(70) TEXT-002.tables: t510.data: it_t510 like table of t510 WITH HEADER LINE .DATA: dy_table TYPE REF TO data,dy_line TYPE REF TO data,dy2_table type ref to data,dy2_line TYPE REF TO data,ifc TYPE lvc_t_fcat,xfc TYPE lvc_s_fcat.FIELD-SYMBOLS: <dyn_table> TYPE STANDARD TABLE,<dyn_table_ori> TYPE STANDARD TABLE,<dyn_wa>,<DYN_WA_ORI>,<dyn_field>,<fs>,<FS_ORI>.data: begin of it_header occurs 0,col like ALSMEX_TABLINE-COL,field(20),end of it_header.AT SELECTION-SCREEN on value-request for p_file.perform help_l_path.AT SELECTION-SCREEN.* AUTHORITY-CHECK OBJECT 'Z_TABLE'* ID 'TABLE' FIELD P_TABLE* ID 'ACTVT' FIELD '02'.* IF SY-SUBRC <> 0.* MESSAGE E016(ZHXII) WITH P_TABLE.* ENDIF.start-of-selection.perform define_itab.perform get_xls.perform update_table.*&---------------------------------------------------------------------**& Form DEFINE_ITAB*&---------------------------------------------------------------------** text*----------------------------------------------------------------------*FORM DEFINE_ITAB .DATA: IT_FIELDS TYPE TABLE OF DFIES WITH HEADER LINE.data: l_tabname TYPE DDOBJNAME.l_tabname = P_TABLE.CALL FUNCTION 'DDIF_FIELDINFO_GET'EXPORTINGTABNAME = L_TABNAMETABLESDFIES_TAB = It_fields[]* FIXED_VALUES =EXCEPTIONSNOT_FOUND = 1INTERNAL_ERROR = 2OTHERS = 3.IF SY-SUBRC <> 0.* MESSAGE ID SY-MSGID TYPE SY-MSGTY NUMBER SY-MSGNO* WITH SY-MSGV1 SY-MSGV2 SY-MSGV3 SY-MSGV4.ENDIF.loop at it_fields.break ibm_yangjf.move-corresponding it_fields to xfc.XFC-INTLEN = IT_FIELDS-LENG.if it_fields-FIELDNAME = 'BETRG'.xfc-intlen = 11.endif.append xfc to ifc.endloop.CALL METHOD cl_alv_table_create=>create_dynamic_tableEXPORTINGit_fieldcatalog = ifcIMPORTINGep_table = dy_table.CALL METHOD cl_alv_table_create=>create_dynamic_tableEXPORTINGit_fieldcatalog = ifcIMPORTINGep_table = dy2_table.assign dy_table->* to <dyn_table>.assign dy2_table->* to <dyn_table_ori>.CREATE DATA dy_line LIKE LINE OF <dyn_table>.CREATE DATA dy2_line LIKE LINE OF <dyn_table_ori>.*同理设定指针ASSIGN dy_line->* TO <dyn_wa>.ASSIGN dy2_line->* TO <dyn_wa_ori>.ENDFORM. " DEFINE_ITAB*&---------------------------------------------------------------------**& Form GET_XLS*&---------------------------------------------------------------------** text*----------------------------------------------------------------------*FORM GET_XLS .DATA: l_intern TYPE alsmex_tabline OCCURS 0 WITH HEADER LINE.DATA: c_row TYPE i VALUE 1,c_col TYPE i VALUE 1,l_index TYPE i,l_msg(60) TYPE c,g_mod TYPE d,l_row(5) TYPE n,LI_LEN TYPE INT2,L_CSTR(4).CALL FUNCTION 'ALSM_EXCEL_TO_INTERNAL_TABLE'EXPORTINGfilename = P_FILEi_begin_col = C_COLi_begin_row = C_ROWi_end_col = 50i_end_row = 9999TABLESintern = l_internEXCEPTIONSinconsistent_parameters = 1upload_ole = 2OTHERS = 3.SORT l_intern BY row col.l_row = c_row.LOOP AT l_intern.if l_intern-row = 1.it_header-col = l_intern-col.it_header-field = l_intern-VALUE.append it_header.else.MOVE l_intern-col TO l_index.read table it_header index l_index.if sy-subrc = 0.ASSIGN COMPONENT it_header-field OF STRUCTURE <dyn_wa> TO <fs>.if sy-subrc = 0.MOVE l_intern-value TO <fs>.endif.endif.AT END OF row.append <dyn_wa> to <dyn_table>.IF P_TABLE = 'T510'.MOVE-CORRESPONDING <DYN_WA> TO IT_T510.APPEND IT_T510.ENDIF.clear <dyn_wa>.* it_RECORD-rowno = l_row.* APPEND it_RECORD.g_mod = l_row MOD 100.IF g_mod = 0.* CONCATENATE c_progress0 l_row INTO l_msg SEPARATED BY space.* progress_indicator: l_msg.ENDIF.l_row = l_row + 1.* CLEAR it_RECORD.ENDAT.ENDIF.ENDLOOP.*删除空行ENDFORM. " GET_XLS*&---------------------------------------------------------------------**& Form help_l_path*&---------------------------------------------------------------------** text*----------------------------------------------------------------------*FORM help_l_path.DATA: l_help.DATA: repid LIKE d020s-prog,dynnr LIKE sy-dynnr.DATA: dynpread LIKE dynpread OCCURS 50 WITH HEADER LINE.repid = sy-repid.dynnr = sy-dynnr.REFRESH dynpread.dynpread-fieldname = 'P_FILE'.dynpread-stepl = '0'.APPEND dynpread.CALL FUNCTION 'DYNP_VALUES_READ'EXPORTINGdyname = repiddynumb = dynnrTABLESdynpfields = dynpread.* l_maske = ',*.*,'.l_help = p_file+1(1).IF l_help = ':'.* l_def_path = l_path.ENDIF.LOOP AT dynpread. ENDLOOP.* FILENAME = DYNPREAD-FIELDVALUE.p_file = dynpread-fieldvalue.IF p_file EQ space.* CONCATENATE p_file '*.XLS' INTO p_file.CONCATENATE P_FILE '*.TXT' INTO P_FILE.ENDIF.CALL FUNCTION 'WS_FILENAME_GET'EXPORTINGdef_filename = p_filedef_path = '\'mask = ',*.*'mode = 'O'title = text-104IMPORTINGfilename = p_fileEXCEPTIONSinv_winsys = 01no_batch = 02selection_cancel = 03selection_error = 04.IF sy-subrc = 0.* G_STEP = C_TOVALIDATE.ENDIF. " okENDFORM. "HELP_L_PATH*&---------------------------------------------------------------------**& Form UPDATE_TABLE*&---------------------------------------------------------------------** text*----------------------------------------------------------------------** --> p1 text* <-- p2 text*----------------------------------------------------------------------*FORM UPDATE_TABLE .if p_table = 'T510'.MODIFY (P_TABLE) FROM TABLE IT_T510.ELSE.modify (p_table) from table <dyn_table>.ENDIF.IF SY-SUBRC = 0.WRITE:/ '提交成功'.ENDIF.ENDFORM. " UPDATE_TABLE
② 列转行程序
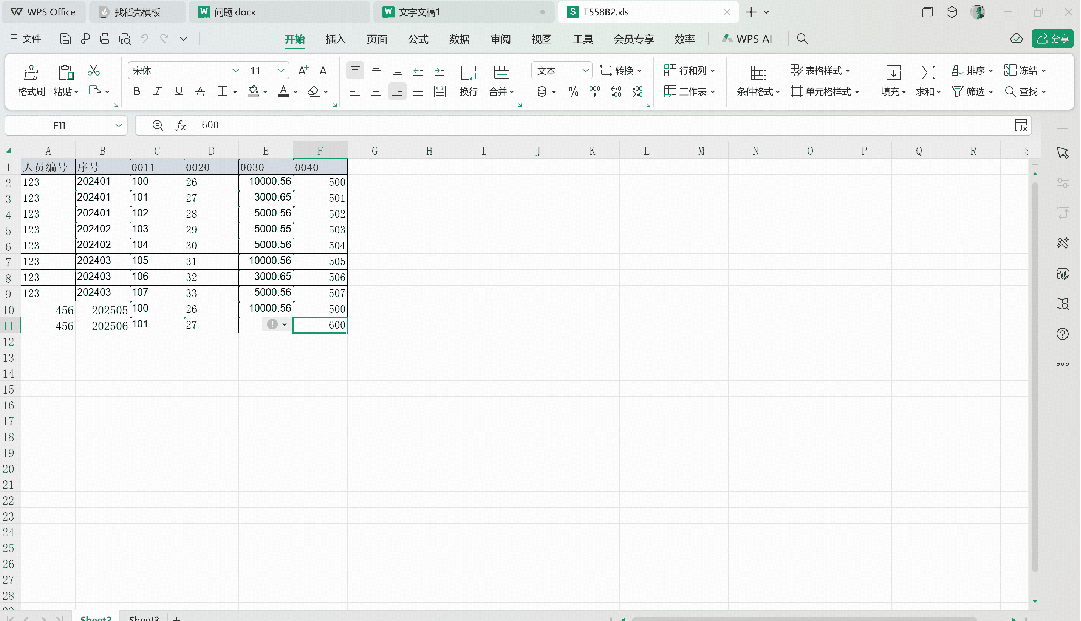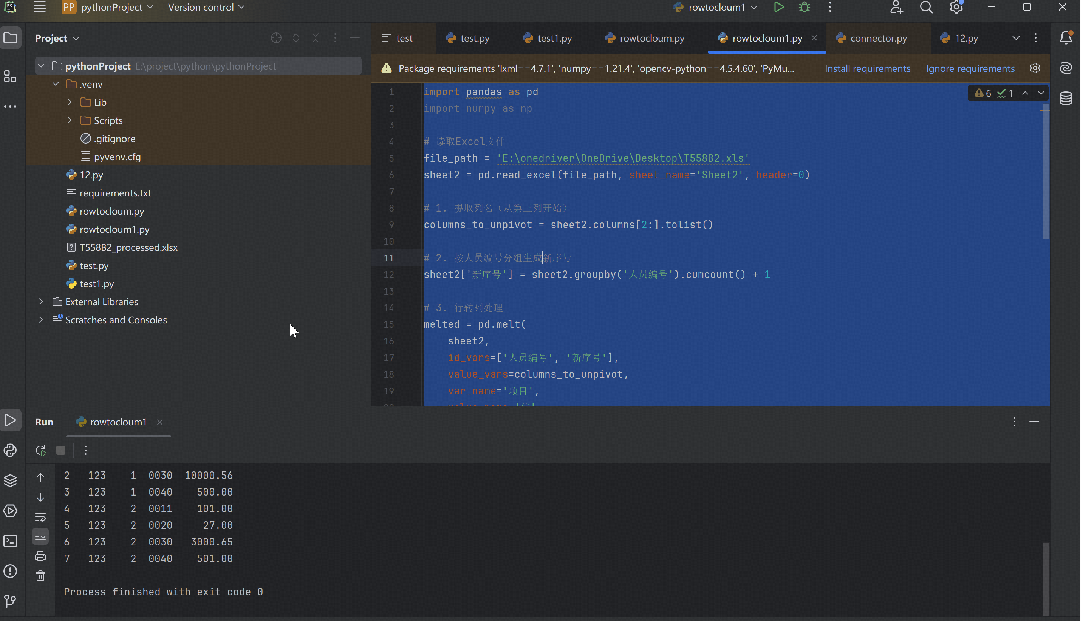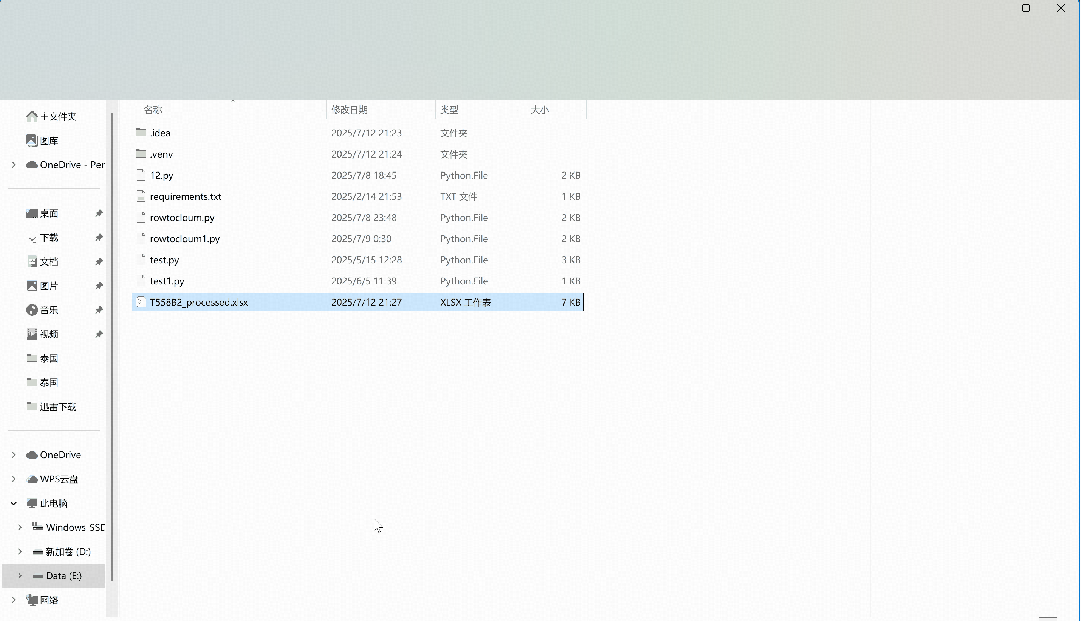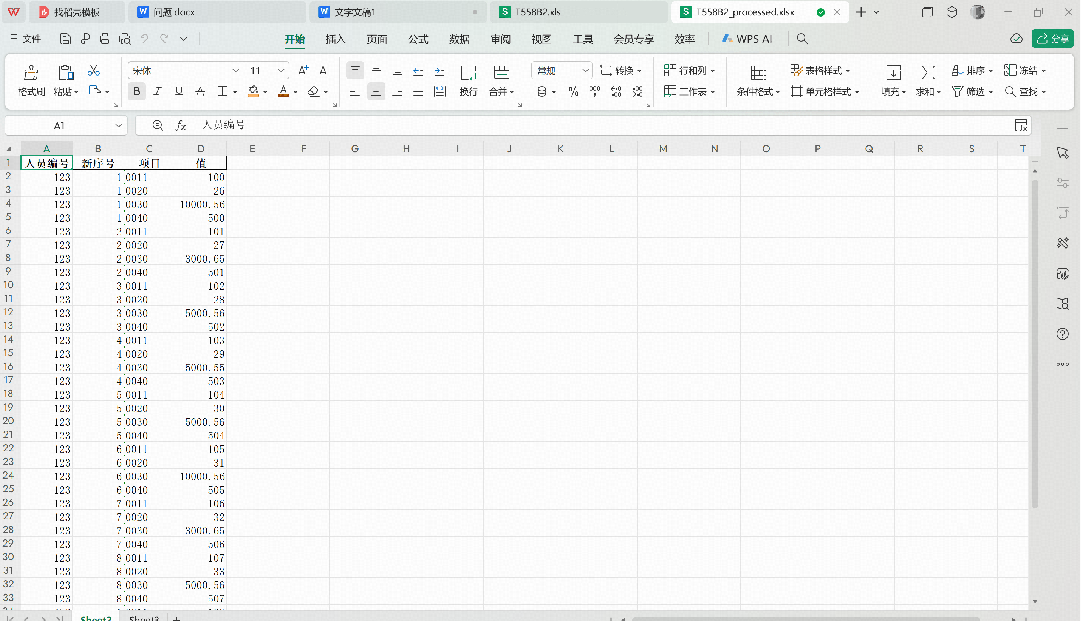
import pandas as pdimport numpy as np# 读取Excel文件file_path = 'E:\onedriver\OneDrive\Desktop\T558B2.xls'sheet2 = pd.read_excel(file_path, sheet_name='Sheet2', header=0)# 1. 提取列名(从第三列开始)columns_to_unpivot = sheet2.columns[2:].tolist()# 2. 按人员编号分组生成新序号sheet2['新序号'] = sheet2.groupby('人员编号').cumcount() + 1# 3. 行转列处理melted = pd.melt( sheet2, id_vars=['人员编号', '新序号'],value_vars=columns_to_unpivot,var_name='项目', value_name='值')# 4. 排序并选择需要的列result = melted[['人员编号', '新序号', '项目', '值']]result = result.sort_values(by=['人员编号', '新序号', '项目']).reset_index(drop=True)# 5. 保存结果到新Excel文件(避免修改原文件)output_path = 'T558B2_processed.xlsx'with pd.ExcelWriter(output_path) as writer: result.to_excel(writer, sheet_name='Sheet2', index=False)# 创建空Sheet3 pd.DataFrame().to_excel(writer, sheet_name='Sheet3', index=False)print(f"处理完成!结果已保存到: {output_path}")print(f"原始数据行数: {len(sheet2)}")print(f"处理后数据行数: {len(result)}")print("处理后的数据结构:")print(result.head(8)) # 显示前8行作为示例
例如下面这个例子























 到【灌水乐园】发言
到【灌水乐园】发言









