




 本文介绍如何使用SQL实现数据累加效果,包括通过表自连接求和的方法。进一步探讨如何找出累计产量达到总产量50%的前N条记录,采用窗口函数ROW_NUMBER()进行排序并累加,最终筛选出符合条件的数据。
本文介绍如何使用SQL实现数据累加效果,包括通过表自连接求和的方法。进一步探讨如何找出累计产量达到总产量50%的前N条记录,采用窗口函数ROW_NUMBER()进行排序并累加,最终筛选出符合条件的数据。
通过SQL实现数据累加的效果
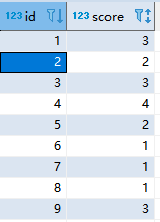
原数据如下:
SELECT * FROM temp.wjz
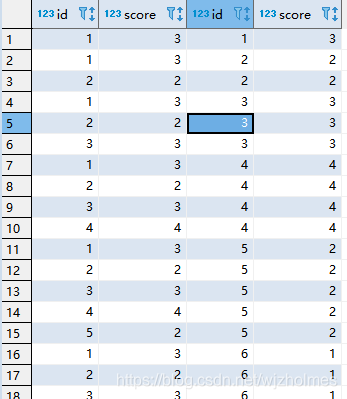
通过inner join 准备累加之前的数据:
SELECT * FROM temp.wjz s1
inner join temp.wjz s2
on s1.id<=s2.id
order by s2.id,s1.id
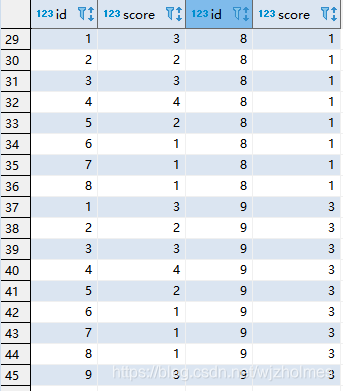
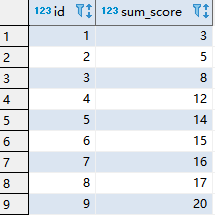
大家可以看到,通过表自连接本身,并且再分组求和一次就可以实现累加效果了:
SELECT s2.id,sum(s1.score) sum_score FROM temp.wjz s1
inner join temp.wjz s2
on s1.id<=s2.id
GROUP by s2.id
order by sum_score
升级的问题:求前n条数据,这n条数据的产量之和,占总产量的50%
有了上面的铺垫后我们计算本问题,首先根据score排序后的结果进行累加,如下:
with temp1 as (
SELECT *,ROW_NUMBER() OVER(order by score DESC ) as num FROM temp.wjz
order by score DESC
)
,
temp2 as (
SELECT s2.num,sum(s1.score) sum_score from temp1 s1
inner join temp1 s2
on s1.num<=s2.num
GROUP by s2.num
)
SELECT temp1.id,temp1.score,temp2.sum_score from temp1,temp2
where temp1.num=temp2.num
order by temp1.num
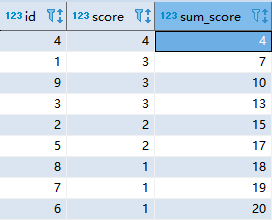
再选取出累加值小于等于最大值50%的就是所需要的结果:
with temp1 as (
SELECT *,ROW_NUMBER() OVER(order by score DESC ) as num FROM temp.wjz
order by score DESC
)
,
temp2 as (
SELECT s2.num,sum(s1.score) sum_score from temp1 s1
inner join temp1 s2
on s1.num<=s2.num
GROUP by s2.num
)
SELECT temp1.id,temp1.score,temp2.sum_score from temp1,temp2
where temp1.num=temp2.num
and temp2.sum_score <=(SELECT MAX(sum_score)*0.5 from temp2 )
order by temp1.num
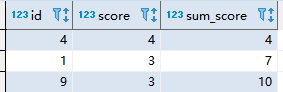


















 4772
4772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











