







SQL的逻辑语句有时候也很巧妙,以下的小练习包含常用的几个逻辑。
目录
1.编写SQL查询以查找至少连续出现三次的所有数字
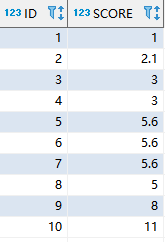
数据准备:
INSERT INTO score (id,SCORE) VALUES(1,1);
INSERT INTO score (id,SCORE) VALUES(2,2.1);
INSERT INTO score (id,SCORE) VALUES(3,3);
INSERT INTO score (id,SCORE) VALUES(4,3);
INSERT INTO score (id,SCORE) VALUES(5,5.6);
INSERT INTO score (id,SCORE) VALUES(6,5.6);
INSERT INTO score (id,SCORE) VALUES(7,5.6);
INSERT INTO score (id,SCORE) VALUES(8,5);
INSERT INTO score (id,SCORE) VALUES(9,8);
INSERT INTO score (id,SCORE) VALUES(10,11);SQL逻辑:
select DISTINCT a.score from score a , score b ,score c
where a.id=b.id -1
and b.id=c.id -1
and a.score = b.score
and b.score =c.score运行结果:

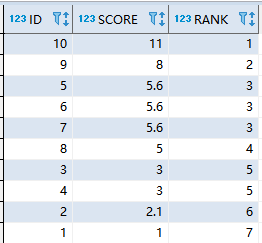
2.对全部分数的排名
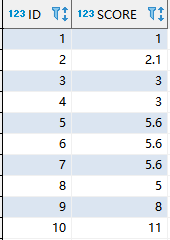
编写SQL查询以对分数进行排名,如果两个分数之间相等,则两个分数应具有相同的排名。请注意,平局后,下一个排名数字应该是下一个连续的整数值。
原数据:
SQL逻辑:
方式1:
SELECT a.*,COUNT( DISTINCT b.score)RANK FROM score a INNER JOIN score b
ON a.score<=b.score
GROUP BY a.id,a.score
ORDER BY a.score DESC方式2:
SELECT A.Score,
(SELECT COUNT(DISTINCT(Score)) FROM
Score WHERE Score >= A.Score) AS Rank
FROM Score A ORDER BY Score DESC;运行结果:
3.查找部门工资最高的员工
使用oracle的scott自带的emp和dept表。
要求:显示出员工名称、工作、工资和部门名称
思路:首先分组找到每个部门最高工资
然后找到对应的员工信息
最后和部门dept表关联,找到部门名称
SELECT e.ename,e.job,e.sal,d.DNAME
FROM EMP e,(
SELECT DEPTNO,MAX(SAL) maxsal
FROM EMP
GROUP BY DEPTNO)temp ,dept d
WHERE e.DEPTNO=temp.deptno
AND e.SAL=temp.maxsal
AND e.DEPTNO=d.DEPTNO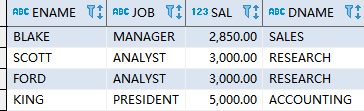
4.查找部门工资前二高的员工
使用oracle的scott自带的emp和dept表。
要求:显示出员工名称、工作、工资和部门名称
思路:emp表自关联,通过限制大于某一个salary的数量选择出前几名高工资
SELECT e.ENAME,e.JOB,SAL,d.DNAME
FROM emp e,DEPT d
WHERE
2>(
SELECT COUNT(DISTINCT SAL)
FROM emp e2
WHERE e2.sal>e.sal
AND e.DEPTNO=e2.DEPTNO
)
AND e.DEPTNO=d.DEPTNO
ORDER BY e.DEPTNO,e.sal 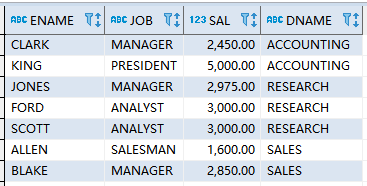
5.连续三天及以上的人流量筛选问题
X 市建了一个新的体育馆,每日人流量信息被记录在这三列信息中:序号 (id)、日期 (date)、 人流量 (people)。
请编写一个查询语句,找出高峰期时段,要求连续三天及以上,并且每天人流量均不少于100。
CREATE TABLE stadium (
id int,
time varchar(20),
people int
)
INSERT INTO stadium VALUES(1,'2021-01-01',10);
INSERT INTO stadium VALUES(2,'2021-01-02',109);
INSERT INTO stadium VALUES(3,'2021-01-03',106);
INSERT INTO stadium VALUES(4,'2021-01-04',99);
INSERT INTO stadium VALUES(5,'2021-01-05',113);
INSERT INTO stadium VALUES(6,'2021-01-06',105);
INSERT INTO stadium VALUES(7,'2021-01-07',103);
INSERT INTO stadium VALUES(8,'2021-01-09',101);
INSERT INTO stadium VALUES(9,'2021-01-19',121);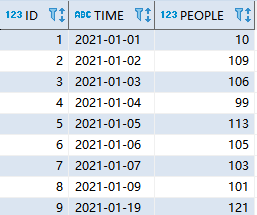
原题目中time和id都是连续的,所以那位作者用一个取巧的方法(不推荐):
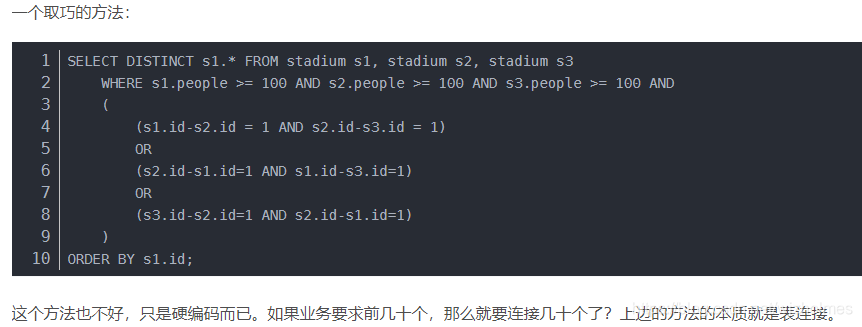
但是这种方法性能上和逻辑上都不推荐。
下面是参考SQL:
SELECT ID,time,people FROM (
SELECT id ,time,people,rownum,diffday,COUNT(*) OVER(PARTITION BY temp.DIFFDAY) cntday
FROM (
SELECT id ,time,people,rownum,
TO_DATE(time,'yyyy-mm-dd') -TO_DATE('2000-01-19','yyyy-mm-dd')-rownum diffday
FROM stadium
WHERE people>100
)temp
)temp2
WHERE cntday>=3
运行结果:
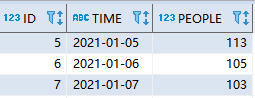
解题思路:
对人数的筛选很简单,难的是连续天数的选择,可以用下面这个例子的规律:
1000 - 1 =999
1001 - 2 =999
1002 - 3 =999
也就是连续的天数减去递增的一列数是相同数值。
所以
1. 最里面的from子查询 temp 就是用时间减去历史时间'2000-01-19',得到具体的天数,然后减去rownum这个自增列,得到天数的差值
2. 外面的temp2的子查询是计算相同差值有多少天cntday
3. 最后对cntday天数筛选
方法二:如果时间连续可以用下面逻辑
select distinct stadium.id,time, people
from stadium,
(
select s1.id
from stadium s1,stadium s2,stadium s3
where s1.id - s2.id = 1
and s2.id - s3.id = 1
and s1.people >=100 and s2.people >=100 and s3.people >=100
) t
where (t.id - stadium.id) between 0 and 26. 行程和取消率
Trips 表中存所有出租车的行程信息。每段行程有唯一键 Id,Client_Id 和 Driver_Id 是 Users 表中 Users_Id 的外键。
Status 是枚举类型,枚举成员为 (‘completed’, ‘cancelled_by_driver’, ‘cancelled_by_client’)。
+----+-----------+-----------+--------------------+----------+
| Id | Client_Id | Driver_Id | Status |Request_at|
+----+-----------+-----------+--------------------+----------+
| 1 | 1 | 10 | completed |2013-10-01|
| 2 | 2 | 11 | cancelled_by_driver|2013-10-01|
| 3 | 3 | 12 | completed |2013-10-01|
| 4 | 4 | 13 | cancelled_by_client|2013-10-01|
| 5 | 1 | 10 | completed |2013-10-02|
| 6 | 2 | 11 | completed |2013-10-02|
| 7 | 3 | 12 | completed |2013-10-02|
| 8 | 2 | 12 | completed |2013-10-03|
| 9 | 3 | 10 | completed |2013-10-03|
| 10 | 4 | 13 | cancelled_by_driver|2013-10-03|
+----+-----------+-----------+--------------------+----------+
Users 表存所有用户。每个用户有唯一键 Users_Id。Banned 表示这个用户是否被禁止,Role 则是一个表示(‘client’, ‘driver’, ‘partner’)的枚举类型。
+----------+--------+--------+
| Users_Id | Banned | Role |
+----------+--------+--------+
| 1 | No | client |
| 2 | Yes | client |
| 3 | No | client |
| 4 | No | client |
| 10 | No | driver |
| 11 | No | driver |
| 12 | No | driver |
| 13 | No | driver |
+----------+--------+--------+
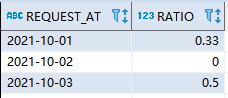
写一段 SQL 语句查出 2013年10月1日 至 2013年10月3日 期间非禁止用户的取消率。
基于上表,你的 SQL 语句应返回如下结果,取消率(Cancellation Rate)保留两位小数。
+------------+-------------------+
| Day | Cancellation Rate |
+------------+-------------------+
| 2013-10-01 | 0.33 |
| 2013-10-02 | 0.00 |
| 2013-10-03 | 0.50 |
+------------+-------------------+CREATE TABLE trip (
id int,
Client_Id int,
Driver_Id int,
Status varchar(30),
Request_at varchar(30)
)
INSERT INTO trip VALUES(1,1,10,'completed','2021-10-01');
INSERT INTO trip VALUES(2,2,11,'cancelled_by_driver','2021-10-01');
INSERT INTO trip VALUES(3,3,12,'completed','2021-10-01');
INSERT INTO trip VALUES(4,4,13,'cancelled_by_client','2021-10-01');
INSERT INTO trip VALUES(5,1,10,'completed','2021-10-02');
INSERT INTO trip VALUES(6,2,11,'completed','2021-10-02');
INSERT INTO trip VALUES(7,3,12,'completed','2021-10-02');
INSERT INTO trip VALUES(8,2,12,'completed','2021-10-03');
INSERT INTO trip VALUES(9,3,10,'completed','2021-10-03');
INSERT INTO trip VALUES(10,4,13,'cancelled_by_driver','2021-10-03');
CREATE TABLE users(
users_id int,
banned varchar(20),
ROLE varchar(20)
)
INSERT INTO users VALUES(1, 'No' ,'client');
INSERT INTO users VALUES(2, 'Yes','client' );
INSERT INTO users VALUES(3, 'No' ,'client');
INSERT INTO users VALUES(4, 'No' ,'client');
INSERT INTO users VALUES(10,'No' ,'driver');
INSERT INTO users VALUES(11,'No' ,'driver');
INSERT INTO users VALUES(12,'No' ,'driver');
INSERT INTO users VALUES(13,'No' ,'driver');SQL参考:
SELECT REQUEST_AT,ROUND(COUNT(temp.cnt1)/COUNT(temp.cnt2),2) ratio FROM (
SELECT t1.REQUEST_AT,
CASE when (t1.STATUS<>'completed' AND u1.banned='No')
THEN t1.CLIENT_ID ELSE NULL
END cnt1,
CASE WHEN (u1.banned='No')
THEN u1.banned ELSE NULL
END cnt2 FROM TRIP t1,users u1
WHERE t1.CLIENT_ID=u1.users_id
)temp
GROUP BY temp.REQUEST_AT
ORDER BY temp.REQUEST_AT;思路:
首先子查询里通过case判断语句选择出分子和分母,无效值设置为null
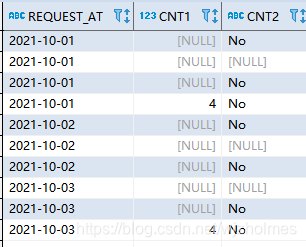
然后在对结果进行count和除法
7. Oracle 的列转行的几种方法
数据准备:
CREATE TABLE city_rank(
province varchar(20),
city varchar(20),
ranking varchar(20)
)
INSERT INTO city_rank VALUES('四川省','成都市','第一');
INSERT INTO city_rank VALUES('四川省','绵阳市','第二');
INSERT INTO city_rank VALUES('四川省','德阳市','第三');
INSERT INTO city_rank VALUES('四川省','宜宾市','第四');
INSERT INTO city_rank VALUES('湖北省','武汉市','第一');
INSERT INTO city_rank VALUES('湖北省','宜昌市','第二');
INSERT INTO city_rank VALUES('湖北省','襄阳市','第三');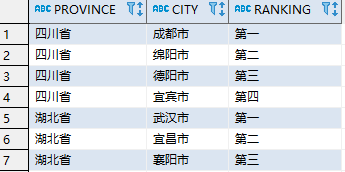
将以上数据行转列为如下

参考SQL:
select *
from city_rank pivot(
max(city) for ranking in ( --ranking 即要转成列的字段
'第一' as 第一 ,'第二' AS 第二,'第三' AS 第三,'第四' AS 第四
)
); 

















 969
969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











