







 本文深入浅出地介绍了视频压缩中的帧内和帧间压缩技术,包括宏块的概念、帧内预测的方法及其应用场景,以及帧间压缩中的块匹配、运动估计与补偿等关键步骤。
本文深入浅出地介绍了视频压缩中的帧内和帧间压缩技术,包括宏块的概念、帧内预测的方法及其应用场景,以及帧间压缩中的块匹配、运动估计与补偿等关键步骤。
作者:王婷婷
链接:https://www.zhihu.com/question/20237091/answer/15795367
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
链接:https://www.zhihu.com/question/20237091/answer/15795367
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
帧内压缩类似于图片压缩,跟这一帧的前面(或后面)一帧(或几帧)无关,由当前帧中,已编码的部分来推测当前待编码的这一部分数据是什么。帧间压缩是,由这一帧的前(或后)一帧(或几帧)来推测当前待压缩的这一部分数据是什么。
①什么是宏块(Macroblock)。宏块就是,把视频的每一帧(相当于一张图片)划分成16*16的小块,一块一块的依次压缩,而不是对整张图片一起压缩。这样降低了计算的复杂度,比较节省时间。一个宏块又可以分成16*16,16*8,8*16,8*8,8*4,4*8,4*4,等大小不等的块。具体怎么划分块大小,要看画面有多复杂。一般来说,运动多,细节多的部分,划分成小块来编码;大片的平坦的无变化的,划分成16*16的大块。下图就是块划分情况,图选的不好,选成残差帧了⊙﹏⊙,分块状况还是大致能看出来的。<img src="https://i-blog.csdnimg.cn/blog_migrate/ccee3129aa2a455a3b955c78a1046f64.png" data-rawwidth="401" data-rawheight="332" class="content_image" width="401">②帧内(Intra)压缩。先看这个图片 ②帧内(Intra)压缩。先看这个图片<img
src="https://i-blog.csdnimg.cn/blog_migrate/36c872b029d280a129726d14263c0e4d.png" data-rawwidth="287" data-rawheight="229" class="content_image" width="287">假设现在是按顺序来编码,第一行已经完全编完,⑤也编完了,正要压缩⑥这一块。可以看出,它周围的①②③④⑤,跟⑥简直一模一样啊,如果能用①②③④⑤来推测⑥是什么图像,显然比只压缩⑥要节省空间。这就是帧内预测。一般来说,视频的第一帧是帧内预测帧(废话,它想参考其他帧的数据也没有的参考),场景切换时是帧内预测帧(比如视频里插了一段广告,这个广告跟视频里其他的内容都无关,用它来预测还不如我自己编自己省空间)。帧内预测在H.264编码标准里有以下几种预测方法,具体请查看H.264白皮书。
②帧内(Intra)压缩。先看这个图片<img
src="https://i-blog.csdnimg.cn/blog_migrate/36c872b029d280a129726d14263c0e4d.png" data-rawwidth="287" data-rawheight="229" class="content_image" width="287">假设现在是按顺序来编码,第一行已经完全编完,⑤也编完了,正要压缩⑥这一块。可以看出,它周围的①②③④⑤,跟⑥简直一模一样啊,如果能用①②③④⑤来推测⑥是什么图像,显然比只压缩⑥要节省空间。这就是帧内预测。一般来说,视频的第一帧是帧内预测帧(废话,它想参考其他帧的数据也没有的参考),场景切换时是帧内预测帧(比如视频里插了一段广告,这个广告跟视频里其他的内容都无关,用它来预测还不如我自己编自己省空间)。帧内预测在H.264编码标准里有以下几种预测方法,具体请查看H.264白皮书。 假设现在是按顺序来编码,第一行已经完全编完,⑤也编完了,正要压缩⑥这一块。可以看出,它周围的①②③④⑤,跟⑥简直一模一样啊,如果能用①②③④⑤来推测⑥是什么图像,显然比只压缩⑥要节省空间。这就是帧内预测。一般来说,视频的第一帧是帧内预测帧(废话,它想参考其他帧的数据也没有的参考),场景切换时是帧内预测帧(比如视频里插了一段广告,这个广告跟视频里其他的内容都无关,用它来预测还不如我自己编自己省空间)。帧内预测在H.264编码标准里有以下几种预测方法,具体请查看H.264白皮书。<img
src="https://i-blog.csdnimg.cn/blog_migrate/ad01fa7e522f7048dcb0791ddf9c7a9e.jpeg" data-rawwidth="845" data-rawheight="244" class="origin_image zh-lightbox-thumb" width="845" data-original="https://pic2.zhimg.com/a2c909705a8d128d2b4c460938c7d8f5_r.jpg">③帧间(Inter)压缩。下图是一个视频序列中连续的两帧。(我真没偷懒,这真的是俩不同的帧,不信你看书的位置和人的表情都变了)
假设现在是按顺序来编码,第一行已经完全编完,⑤也编完了,正要压缩⑥这一块。可以看出,它周围的①②③④⑤,跟⑥简直一模一样啊,如果能用①②③④⑤来推测⑥是什么图像,显然比只压缩⑥要节省空间。这就是帧内预测。一般来说,视频的第一帧是帧内预测帧(废话,它想参考其他帧的数据也没有的参考),场景切换时是帧内预测帧(比如视频里插了一段广告,这个广告跟视频里其他的内容都无关,用它来预测还不如我自己编自己省空间)。帧内预测在H.264编码标准里有以下几种预测方法,具体请查看H.264白皮书。<img
src="https://i-blog.csdnimg.cn/blog_migrate/ad01fa7e522f7048dcb0791ddf9c7a9e.jpeg" data-rawwidth="845" data-rawheight="244" class="origin_image zh-lightbox-thumb" width="845" data-original="https://pic2.zhimg.com/a2c909705a8d128d2b4c460938c7d8f5_r.jpg">③帧间(Inter)压缩。下图是一个视频序列中连续的两帧。(我真没偷懒,这真的是俩不同的帧,不信你看书的位置和人的表情都变了)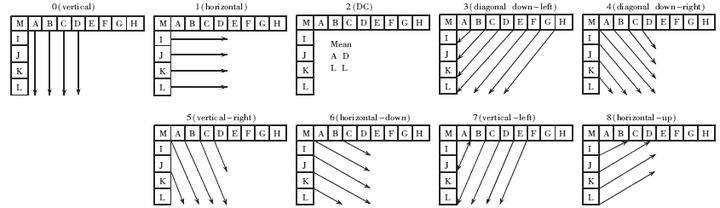 ③帧间(Inter)压缩。下图是一个视频序列中连续的两帧。(我真没偷懒,这真的是俩不同的帧,不信你看书的位置和人的表情都变了)<img
src="https://i-blog.csdnimg.cn/blog_migrate/b9627422c9f5ca6d4a1ab146f25458ef.png" data-rawwidth="287" data-rawheight="229" class="content_image" width="287">
③帧间(Inter)压缩。下图是一个视频序列中连续的两帧。(我真没偷懒,这真的是俩不同的帧,不信你看书的位置和人的表情都变了)<img
src="https://i-blog.csdnimg.cn/blog_migrate/b9627422c9f5ca6d4a1ab146f25458ef.png" data-rawwidth="287" data-rawheight="229" class="content_image" width="287"> <img
src="https://i-blog.csdnimg.cn/blog_migrate/03d1e17d6b4a5b22904c5a4f68f13fea.png" data-rawwidth="287" data-rawheight="229" class="content_image" width="287">如果摄像头没有晃来晃去,那么,在连续的视频图像里面,前后两帧的差别真的很小,比一张图片中连续两个宏块的差别还要小,这时用帧间压缩的效果会比帧内压缩的效果好。
<img
src="https://i-blog.csdnimg.cn/blog_migrate/03d1e17d6b4a5b22904c5a4f68f13fea.png" data-rawwidth="287" data-rawheight="229" class="content_image" width="287">如果摄像头没有晃来晃去,那么,在连续的视频图像里面,前后两帧的差别真的很小,比一张图片中连续两个宏块的差别还要小,这时用帧间压缩的效果会比帧内压缩的效果好。 如果摄像头没有晃来晃去,那么,在连续的视频图像里面,前后两帧的差别真的很小,比一张图片中连续两个宏块的差别还要小,这时用帧间压缩的效果会比帧内压缩的效果好。<img
src="https://i-blog.csdnimg.cn/blog_migrate/075a4789fe3a1b244d5cb57f304619fa.jpeg" data-rawwidth="467" data-rawheight="208" class="origin_image zh-lightbox-thumb" width="467" data-original="https://pic1.zhimg.com/b329a0f1539ae53facd0d3840ef68460_r.jpg">Block
Matching 就是块匹配,就是找找看前面已经编码的几帧里面,和我当前这个块最类似的一个块,这样我就不用编码当前块的内容了,只需要编码当前块和我找到的那个块的差(称为残差)就可以了。找最像的块的过程叫运动搜索(Motion Search),又叫运动估计(Motion Estimation)。用残差和原来的块就能推算出当前块是什么样儿的,这个过程叫运动补偿(Motion Compensation)。有全搜索,菱形搜索法,三步搜索算法,新三步搜索算法,梯度下降搜索算法,运动矢量场自适应搜索算法等各种算法,这也一直是研究和发论文的热点。
如果摄像头没有晃来晃去,那么,在连续的视频图像里面,前后两帧的差别真的很小,比一张图片中连续两个宏块的差别还要小,这时用帧间压缩的效果会比帧内压缩的效果好。<img
src="https://i-blog.csdnimg.cn/blog_migrate/075a4789fe3a1b244d5cb57f304619fa.jpeg" data-rawwidth="467" data-rawheight="208" class="origin_image zh-lightbox-thumb" width="467" data-original="https://pic1.zhimg.com/b329a0f1539ae53facd0d3840ef68460_r.jpg">Block
Matching 就是块匹配,就是找找看前面已经编码的几帧里面,和我当前这个块最类似的一个块,这样我就不用编码当前块的内容了,只需要编码当前块和我找到的那个块的差(称为残差)就可以了。找最像的块的过程叫运动搜索(Motion Search),又叫运动估计(Motion Estimation)。用残差和原来的块就能推算出当前块是什么样儿的,这个过程叫运动补偿(Motion Compensation)。有全搜索,菱形搜索法,三步搜索算法,新三步搜索算法,梯度下降搜索算法,运动矢量场自适应搜索算法等各种算法,这也一直是研究和发论文的热点。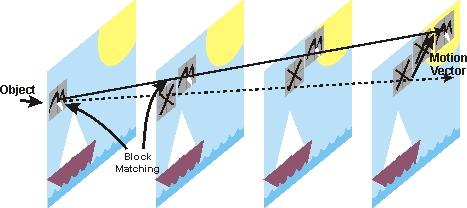
①什么是宏块(Macroblock)。宏块就是,把视频的每一帧(相当于一张图片)划分成16*16的小块,一块一块的依次压缩,而不是对整张图片一起压缩。这样降低了计算的复杂度,比较节省时间。一个宏块又可以分成16*16,16*8,8*16,8*8,8*4,4*8,4*4,等大小不等的块。具体怎么划分块大小,要看画面有多复杂。一般来说,运动多,细节多的部分,划分成小块来编码;大片的平坦的无变化的,划分成16*16的大块。下图就是块划分情况,图选的不好,选成残差帧了⊙﹏⊙,分块状况还是大致能看出来的。<img src="https://i-blog.csdnimg.cn/blog_migrate/ccee3129aa2a455a3b955c78a1046f64.png" data-rawwidth="401" data-rawheight="332" class="content_image" width="401">②帧内(Intra)压缩。先看这个图片
②帧内(Intra)压缩。先看这个图片<img
src="https://i-blog.csdnimg.cn/blog_migrate/36c872b029d280a129726d14263c0e4d.png" data-rawwidth="287" data-rawheight="229" class="content_image" width="287">假设现在是按顺序来编码,第一行已经完全编完,⑤也编完了,正要压缩⑥这一块。可以看出,它周围的①②③④⑤,跟⑥简直一模一样啊,如果能用①②③④⑤来推测⑥是什么图像,显然比只压缩⑥要节省空间。这就是帧内预测。一般来说,视频的第一帧是帧内预测帧(废话,它想参考其他帧的数据也没有的参考),场景切换时是帧内预测帧(比如视频里插了一段广告,这个广告跟视频里其他的内容都无关,用它来预测还不如我自己编自己省空间)。帧内预测在H.264编码标准里有以下几种预测方法,具体请查看H.264白皮书。假设现在是按顺序来编码,第一行已经完全编完,⑤也编完了,正要压缩⑥这一块。可以看出,它周围的①②③④⑤,跟⑥简直一模一样啊,如果能用①②③④⑤来推测⑥是什么图像,显然比只压缩⑥要节省空间。这就是帧内预测。一般来说,视频的第一帧是帧内预测帧(废话,它想参考其他帧的数据也没有的参考),场景切换时是帧内预测帧(比如视频里插了一段广告,这个广告跟视频里其他的内容都无关,用它来预测还不如我自己编自己省空间)。帧内预测在H.264编码标准里有以下几种预测方法,具体请查看H.264白皮书。<img
src="https://i-blog.csdnimg.cn/blog_migrate/ad01fa7e522f7048dcb0791ddf9c7a9e.jpeg" data-rawwidth="845" data-rawheight="244" class="origin_image zh-lightbox-thumb" width="845" data-original="https://pic2.zhimg.com/a2c909705a8d128d2b4c460938c7d8f5_r.jpg">③帧间(Inter)压缩。下图是一个视频序列中连续的两帧。(我真没偷懒,这真的是俩不同的帧,不信你看书的位置和人的表情都变了)③帧间(Inter)压缩。下图是一个视频序列中连续的两帧。(我真没偷懒,这真的是俩不同的帧,不信你看书的位置和人的表情都变了)<img
src="https://i-blog.csdnimg.cn/blog_migrate/b9627422c9f5ca6d4a1ab146f25458ef.png" data-rawwidth="287" data-rawheight="229" class="content_image" width="287"><img
src="https://i-blog.csdnimg.cn/blog_migrate/03d1e17d6b4a5b22904c5a4f68f13fea.png" data-rawwidth="287" data-rawheight="229" class="content_image" width="287">如果摄像头没有晃来晃去,那么,在连续的视频图像里面,前后两帧的差别真的很小,比一张图片中连续两个宏块的差别还要小,这时用帧间压缩的效果会比帧内压缩的效果好。如果摄像头没有晃来晃去,那么,在连续的视频图像里面,前后两帧的差别真的很小,比一张图片中连续两个宏块的差别还要小,这时用帧间压缩的效果会比帧内压缩的效果好。<img
src="https://i-blog.csdnimg.cn/blog_migrate/075a4789fe3a1b244d5cb57f304619fa.jpeg" data-rawwidth="467" data-rawheight="208" class="origin_image zh-lightbox-thumb" width="467" data-original="https://pic1.zhimg.com/b329a0f1539ae53facd0d3840ef68460_r.jpg">Block
Matching 就是块匹配,就是找找看前面已经编码的几帧里面,和我当前这个块最类似的一个块,这样我就不用编码当前块的内容了,只需要编码当前块和我找到的那个块的差(称为残差)就可以了。找最像的块的过程叫运动搜索(Motion Search),又叫运动估计(Motion Estimation)。用残差和原来的块就能推算出当前块是什么样儿的,这个过程叫运动补偿(Motion Compensation)。有全搜索,菱形搜索法,三步搜索算法,新三步搜索算法,梯度下降搜索算法,运动矢量场自适应搜索算法等各种算法,这也一直是研究和发论文的热点。
Block Matching 就是块匹配,就是找找看前面已经编码的几帧里面,和我当前这个块最类似的一个块,这样我就不用编码当前块的内容了,只需要编码当前块和我找到的那个块的差(称为残差)就可以了。找最像的块的过程叫运动搜索(Motion Search),又叫运动估计(Motion Estimation)。用残差和原来的块就能推算出当前块是什么样儿的,这个过程叫运动补偿(Motion Compensation)。有全搜索,菱形搜索法,三步搜索算法,新三步搜索算法,梯度下降搜索算法,运动矢量场自适应搜索算法等各种算法,这也一直是研究和发论文的热点
https://www.zhihu.com/question/20237091。

















 971
971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









