



基于深度强化学习的无人机辅助边缘计算网络路径规划
摘要
移动边缘计算(MEC)利用网络边缘的计算能力,为多种物联网应用执行计算密集型任务。与此同时,无人机(UAV)具有灵活扩展覆盖范围并提升网络性能的巨大潜力。因此,使用无人机为大量物联网设备提供边缘计算服务已成为一种有前景的范式。本文研究了无人机辅助边缘计算网络中的路径规划问题,其中部署配备边缘服务器的无人机以执行从多个设备卸载的计算任务。我们考虑了设备的移动性,采用高斯‐马尔可夫随机移动模型。通过综合考虑无人机在动态飞行和执行任务过程中的能耗,我们将路径规划问题建模为在最小化无人机能耗的同时最大化设备卸载的数据比特量的问题。为了应对复杂环境的动态变化,我们采用深度强化学习(DRL)方法,基于双深度Q学习网络(DDQN)设计了一种在线路径规划算法。大量仿真结果验证了所提出的基于DRL的路径规划算法在收敛速度和系统奖励方面的有效性。
关键词 —深度强化学习, 高斯‐马尔可夫随机模型, 移动边缘计算, Unmanned Aerial Vehicle, 路径优化
一、引言
移动边缘计算(MEC)使得网络边缘的计算能力能够灵活、快速地为海量物联网设备[1]部署创新应用和服务。通过部署MEC,设备可以将其计算密集型任务转移到附近强大的边缘服务器上,以降低时延并节省能耗[1],[2]。与固定边缘服务器不同,近期关于MEC的研究致力于移动边缘服务器,其可在恶劣环境中提供更灵活、更经济高效的计算服务。最近,一些文献提出利用无人机来增强地面物联网设备的连通性[3]。无人机辅助无线通信在灵活部署、完全可控的移动性以及提升网络性能方面展现出优势,因此吸引了越来越多的研究关注。相应地,无人机辅助边缘计算网络成为一种自然且有前景的范式,其中如何优化无人机的飞行路径以满足海量设备的通信与计算需求成为一个重要且具有挑战性的问题。
近年来,一些现有文献研究了无人机辅助移动边缘计算网络中的路径规划问题。在[4]中,在无人机的时延和能耗约束下联合优化了无人机的轨迹和比特分配。然而,在这些工作中,设备被假定为静止的,未考虑其移动性。实际上,设备的位置可能随时间动态变化,因此无人机需要根据移动设备的时变位置相应地调整其轨迹。同时,上述工作主要集中在传统的基于优化的路径规划算法,当无人机和设备数量增加时,该方法可能并不总是有效,因为优化变量的激增导致方法效率低下[5]。在[6]中,通过使用深度神经网络(DNN)进行函数逼近,深度强化学习(DRL)已被证明在逼近Q值方面是有效的。随后,DRL被应用于无线网络中在线资源分配与调度的设计[7]–[9]。具体而言,在[7]中,通过优化卸载决策和计算资源分配,最小化了多用户MEC网络的执行时延和能耗的总系统成本。在[8]中提出了一种在线卸载算法,以最大化支持无线能量收集能力的无线供能MEC网络的加权和计算速率。在[9]中研究了基于深度强化学习的物联网设备计算卸载策略。然而,据我们所知,现有研究很少探讨如何在移动边缘计算网络中智能设计无人机的飞行轨迹以服务海量设备,特别是考虑到设备的动态移动性以及无人机与设备之间的动态关联。
本文研究了无人机辅助边缘计算网络中的路径规划问题,其中部署了一架搭载边缘服务器的无人机,用于执行从多个物联网设备卸载的计算任务。考虑到实际场景中设备的动态移动性,我们采用了高斯‐马尔可夫随机移动模型。一方面,为了充分利用无人机提供的计算能力,我们的目标是最大化从设备卸载到无人机的任务数据比特数量;另一方面,为了延长无人机的寿命,需要最小化无人机在飞行和任务执行过程中的总能耗。因此,我们构建了一个路径规划问题,以优化卸载数据比特的加权量和能耗。
针对动态且复杂的环境,我们采用深度强化学习(DRL)框架,并提出了一种基于双深度Q学习网络(DDQN)的在线路径规划算法。该算法将对周围环境的观测作为输入,通过训练深度神经网络来预测动作的奖励。最后,仿真结果验证了所提出的基于DRL的路径规划算法在收敛速度和系统奖励(即卸载数据比特的加权量和能耗)方面的性能提升。
本文其余部分组织如下。第二节介绍了系统模型和问题建模。第三节提出了基于深度强化学习的路径规划算法。第四节给出了仿真结果,随后是结论。
II. 系统模型与问题建模
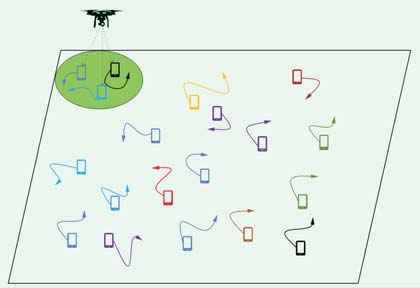
本文考虑了一个如图1所示的时隙无人机辅助边缘计算网络,其中部署了一架携带边缘服务器的无人机,可为N物联网设备提供计算服务。每个设备可以在不同位置之间随机移动,并在每个时隙生成一定量的计算任务。为了完成这些任务,计算能力受限的设备通常会将任务卸载到具有强大计算能力的无人机上。
受限于有效通信距离,无人机只能为覆盖区域内的设备提供服务,因此无人机的动态飞行与悬停可以进一步扩大覆盖区域以服务所有设备。为了简化分析,我们假设无人机只能在M个固定的接入点之一处悬停。当无人机悬停时,可以协助执行当前区域内设备的任务,这被称为无人机与设备之间的关联。
A. 物联网设备移动模型
考虑到设备的移动性,本文采用了高斯‐马尔可夫随机移动模型[10]。相应地,第i个设备在时隙t内的移动速度vi(t)和方向φi(t)被更新为
$$
v_i(t) = c_1 v_i(t - 1) + (1 - c_1) \bar{v} + \sqrt{1 - c_1^2} \Phi_i, \tag{1}
$$
$$
\phi_i(t) = c_2 \phi_i(t - 1) + (1 - c_2) \bar{\phi}_i + \sqrt{1 - c_2^2} \Psi_i. \tag{2}
$$
在上述表达式中,$0 \leq c_1, c_2 \leq 1$ 是用于调整先前状态对当前状态影响的参数,$\bar{v}$ 是所有设备的通用平均速度,$\bar{\phi}_i$ 是第i个设备的平均方向,$\Phi_i$ 和 $\Psi_i$ 是两个服从独立高斯分布的随机变量。
给定移动速度和方向,第i个设备的位置坐标由[11]给出
$$
x_{TD_i}(t) = x_{TD_i}(t - 1) + v_i(t - 1) \cos(\phi_i(t - 1)) T_0, \tag{3}
$$
$$
y_{TD_i}(t) = y_{TD_i}(t - 1) + v_i(t - 1) \sin(\phi_i(t - 1)) T_0, \tag{4}
$$
其中$T_0$表示每个时隙的持续时间。通常,$T_0$足够小,使得设备的位置在任意一个时隙内可视为保持不变,但在不同时隙之间可能发生变化。
B. 无人机边缘计算
在每个时隙中,无人机需要收集并执行其覆盖区域内设备的计算任务。记$\mu_i(t)$为第i个设备在时隙t中卸载的任务数量,$N_i$为每任务数据位数。因此,在时隙t中,从第i个设备卸载到无人机的卸载任务的数据比特数量为
$$
\lambda_i(t) = \mu_i(t) N_i, \tag{5}
$$
根据(3)和(4)中设备的位置,我们可以得到第i个设备与无人机之间的水平距离
$$
R_i(t) = \sqrt{[x_U(t) - x_{TD_i}(t)]^2 + [y_U(t) - y_{TD_i}(t)]^2}, \tag{6}
$$
其中$x_U(t)$, $y_U(t)$是从预设的M个接入点集合中选择的无人机的位置坐标。
如果第i个移动设备想要将其任务卸载到无人机,则它必须位于无人机的覆盖区域内,且水平距离满足[12]
$$
R_i(t) \leq H \tan\beta, \tag{7}
$$
其中H是无人机相对于地面的高度。假设无人机配备有可调波束宽度的定向天线。无人机天线的方位角和俯仰半功率波束宽度相等,均用$\beta \in (0, \pi/2)$表示。我们使用二进制变量$a_i(t) = 1$来指示第i个设备是否位于无人机的覆盖区域内,其表达式为
$$
a_i(t) =
\begin{cases}
1, & R_i(t) \leq H \tan\beta, \quad i \in N \
0, & \text{else},
\end{cases} \tag{8}
$$
其中$a_i(t)$也反映了设备与无人机之间的关联关系。为此,我们可以得到在时隙t中处于无人机覆盖区域内的移动设备集合为$\mathcal{M}(t) = {i \mid i \in {R_i(t) \leq H\tan\beta}}$,其中$M(t) = |\mathcal{M}(t)| = \sum_{i=1}^{N} a_i(t)$是关联设备总数。因此,卸载到无人机的总任务量为
$$
\lambda(t) = \sum_{i=1}^{N} a_i(t) \lambda_i(t). \tag{9}
$$
C. 无人机的能耗模型
事实上,无人机的能源管理在延长无人机寿命和实现良好网络性能方面起着重要作用。无人机的能量不仅消耗于动态飞行,还用于完成从设备卸载的计算任务。当无人机在时隙t中从一个接入点飞往另一个接入点时,其飞行能耗为[11]。
$$
e_f(t) = P_f \frac{L}{V}, \tag{10}
$$
其中,$L = \sqrt{[x_U(t) - x_U(t - 1)]^2 + [y_U(t) - y_U(t - 1)]^2}$为无人机的飞行距离,V和Pf分别表示无人机的飞行速度和功率。当无人机在时隙t‐1到时隙t所选择的位置保持不变时,我们假设无人机在此期间消耗的能量为$e_f(t) = P_0$。
计算能耗取决于卸载到无人机的数据比特总量以及边缘服务器的CPU频率,其表达式为[13]。
$$
e_c(t) = \gamma_c C f_c^2 \lambda(t), \tag{11}
$$
其中$\gamma_c$是有效开关电容,C是每比特CPU周期,$f_c$是边缘服务器的CPU频率。因此,无人机在时隙t内的总能耗为
$$
e(t) = e_c(t) + \eta e_f(t), \tag{12}
$$
其中$\eta$是飞行能耗的惩罚系数,用于减小量级差异。因此,无人机在时隙t内的总剩余能耗为
$$
B(t+1) = B(t) - e(t), \tag{13}
$$
其中初始能量设置为$B(0) = B_0$。
D. 问题建模
为了充分利用无人机提供的计算能力,我们需要最大化从设备卸载到无人机的任务数据量。同时,为了延长寿命,必须最小化总能耗。因此,我们的目标是优化无人机的飞行路径并管理能源资源,以最大化加权数据量。
已卸载的计算任务比特数和能耗,我们可以构建以下优化问题
$$
\max_{x_U(t), y_U(t)} \frac{1}{T} \sum_{t=0}^{T-1} \left( \sum_{i \in \mathcal{M}(t)} \sigma \lambda_i(t) - \phi e(t) \right)
$$
$$
\text{s.t. } (1)-(13), \quad B(t) \geq 0, \forall t, \tag{14}
$$
其中,权重系数$\sigma, \phi$用于平衡数量级。T是时隙总数。
III. 基于深度强化学习的路径规划设计
在本节中,为了实现智能路径规划和能源管理,我们采用深度强化学习来解决所提出的优化问题,并获得在线调度方案。
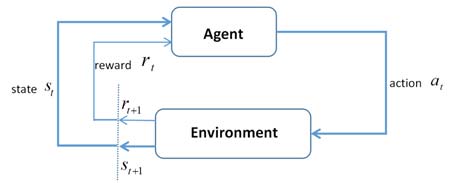
无人机可被视为一个智能体,用于探索未知外部环境。该问题可建模为一个马尔可夫决策过程。如图2所示,在时隙t,智能体处于当前环境状态$s_t$,然后执行动作$a_t$。之后,环境向智能体反馈奖励$r_{t+1}$,并演变为下一个状态$s_{t+1}$。此过程将持续进行,直到环境发送终止状态。状态、动作和奖励函数的细节将在下文介绍。
1) 状态 :状态包括第i个设备的计算任务量$\lambda_i(t)$、设备的当前位置坐标$l_{TD_i}(t) = (x_{TD_i}(t), y_{TD_i}(t))$,以及上一时隙结束时无人机的位置坐标$l_U(t−1) = (x_U(t − 1), y_U(t − 1))$。同时,无人机在该时隙的剩余能量$B(t)$也可作为状态变量。因此,智能体的状态表示为$s_t = (l_{TD_i}(t), l_U(t−1), \lambda_i(t), B(t))$。
2) 动作 :动作为控制无人机的飞行并确定其为物联网设备提供服务的悬停位置。在每个时隙t,无人机需要根据当前状态观测从候选点中选择一个固定的接入点,并继续执行任务卸载。我们用$a_t = l_U(t) = (x_U(t), y_U(t))$表示智能体在时隙t的动作。
3) 奖励 :我们的目标是在保证能耗的前提下,最大化卸载的任务的数据比特数。因此,每个动作的目的都是最大化卸载的任务
在能耗的前提下,系统奖励需要包含这两个因素,即数据比特和能耗,其定义为
$$
r_{t+1} = \sigma \lambda(t) - \phi e(t). \tag{15}
$$
强化学习方法的目的是找到最优策略$\pi^*$(一种从其状态空间S中的状态到动作空间A中每个动作选择概率的映射),以最大化从任意初始状态$G_t$获得的期望奖励,
$$
G_t = \sum_{k=0}^{\infty} \gamma^k r_{t+k+1}, \quad 0 \leq \gamma \leq 1, \tag{16}
$$
其中$\gamma$是一个折扣因子,用于权衡即时奖励和未来奖励的重要性。
本文中,我们采用双深度Q学习和经验回放来训练智能体,以有效学习路径规划策略。基于策略$\pi$, $q_\pi(s, a)$的动作‐状态价值函数为
$$
q_\pi(s, a) = \mathbb{E}_\pi[G_t \mid s_t = s, a_t = a], \tag{17}
$$
其中$G_t$在(16)中定义。如果所有的动作‐状态价值函数$q_\pi(s, a)$均已被获得,则也可确定最优策略。深度Q网络(DQN)是一种基于价值函数的学习算法。在[14], DQN中,通过使用两个深度神经网络来逼近Q值。其中一个为训练网络,其输入为当前状态‐动作对,输出为预测值$Q_{\text{DQN}}^p(s_t, a_t; \theta)$;另一个为目标网络,其输入为下一状态,输出为下一状态中状态‐动作对的最大Q值。DQN的目标值为
$$
Q_{\text{DQN}}^t = r_t + \gamma \max_a Q(s_{t+1}, a; \theta^-).
$$
DQN结构在目标网络中直接选择$\max_a Q(s_{t+1}, a; \theta^-)$,且参数不会随时间更新,这可能导致Q值被高估,从而导致最终策略并非最优,而仅为次优[14]。为了解决Q值过高估计的问题,双深度Q学习网络(DDQN)分别采用不同的动作‐价值函数进行动作选择和评估。与DQN的不同之处在于,DDQN中的目标值定义为
$$
Q_{\text{DDQN}}^t = r_t + \gamma Q(s_{t+1}, \arg\max_a Q(s_{t+1}, a, \theta); \theta^-).
$$
基于DDQN,在每个时隙中,训练和测试阶段都是实现智能路径规划方案所必需的,具体描述如下:
训练阶段 :本文中,路径规划方案基于DDQN算法实现。在无人机学习与探索过程中,将当前环境、动作、反馈奖励以及下一个时隙的状态等信息整合为一个训练样本,即$d(t) = (s_t, a_t, s_{t+1}, r_{t+1})$。所有收集到的训练样本均存储在回放记忆库D中。在每个回合中,从记忆库中均匀抽取一个小批量的经验K,用于通过随机梯度下降的变体来更新$\theta$
为了降低计算复杂度,我们设置了一小部分固定的接入点 M= 9,即动作空间的数量为9。除非另有说明,我们将无人机的初始能量设为B0= 3 ∗10⁶焦耳,飞行速度为V= 20m/s,飞行功率为Pf= 60瓦特,P₀= 80瓦特,C= 1000,fc= 2GHz,Ni= 1兆比特,γc= 10⁻²⁵F,β= π/6和μi(t)在[0, 10]范围内均匀分布。为了实现DDQN算法,采用了一个具有两个隐藏层的四层全连接神经网络,其中两个隐藏层的神经元数量分别设置为400和300。该神经网络采用ReLU,其中 f(x) = max(0, x)作为所有隐藏层的激活函数,并使用优化器以学习率 0.0001更新网络参数。此外,为了更好地探索环境设置 ε= 0.1,经验回放缓冲区大小设置为500,000。假设无人机以一定的初始能量开始为移动设备服务,然后在复杂多变的环境中探索更优的服务路径策略,逐步增加系统奖励,直到能耗耗尽。这一时期称为一个完整回合。在训练阶段,回合数为L_max = 9000,每个回合的最大步数为T_max = 200。
首先,在图3中展示了基于所提出的DDQN算法、DQN、双流DQN和随机基线算法的智能路径规划方案所获得的平均奖励(包括卸载的数据比特和能耗)。在第三节中,路径规划方案基于DDQN算法。我们还展示了仿真
基于DQN和双流DQN算法的改进方案的结果。在这些算法中,双流DQN是DQN的一种变体,它将Q值分解为状态值和优势函数,以获取更有用的信息;而随机基线算法则是在每个时隙随机选择一个固定的接入点供无人机执行相应的任务卸载。我们可以观察到,在经过4000回合后,所有路径规划算法均能达到收敛状态,其中提出的基于DDQN的路径规划算法性能最优,而随机基线算法性能最差。该结果验证了所提出的路径规划算法的优越性。在给定Q值的情况下,如何选择动作的策略会显著影响性能。
在图4中,我们比较了四种动作选择策略的性能。EpsGreedyQ策略是 ε= 0.1的一种贪婪策略。贪婪Q策略是始终选择最大Q值的动作。Boltzmann Q策略是一种Boltzmann Q策略,它根据Q值建立概率规律,并依据该规律返回一个随机选择的动作。最大Boltzmann Q策略是贪婪策略与Boltzmann Q策略的结合。如图所示,EpsGreedyQ策略和贪婪Q策略的性能非常接近,但EpsGreedyQ策略略优于贪婪Q策略。这是因为EpsGreedyQ策略在未知环境中更适于保持一定比例的探索。在这四种策略中,Boltzmann Q策略表现最差。
在无人机辅助边缘计算网络中,无人机的高度会显著影响覆盖区域,移动设备的数量也可能导致不同的性能表现。我们在图5中展示了这两个因素对所实现性能的影响。结果来自10次数值仿真的平均值。如图所示,无人机高度越高,获得的平均奖励越小。这主要是因为无人机高度增加通常会导致通信距离增大、覆盖区域减小,从而使无人机执行的数据比特数量减少。同时,我们发现平均奖励随着移动设备数量的增加而增加。这是因为当移动设备数量增加时,无人机需要消耗更多能耗来完成设备的计算任务,但能耗的权重小于数据的权重
比特卸载,这使得整体奖励上升。
在图6中,展示了物联网设备移动速度的影响,其中无人机的高度设置为30m,设备数量为60。在 v̄=1、2、8、12和15m/s的情况下,所提算法能够收敛,且较小的平均速度 v̄会带来更大的奖励。因为当设备的移动速度较小时,路径规划问题逐渐退化为服务于静态设备的优化问题,最优策略可以更快且更容易地获得。
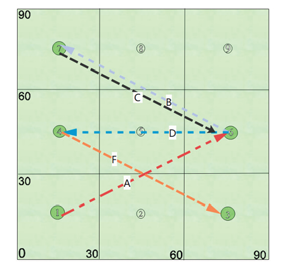
最后,我们在图7中展示了无人机路径轨迹的一个示例,其中考虑了90m×90m的区域,并且v̄=1m/s,H=15√3m,N=30。图中,标有序列号1到9的九个接入点是固定的。经过6000回合的训练阶段后,我们可以观察到在一个完整回合中,无人机通过 1→6→7→6→4→3 的路线为移动设备提供服务。
V. 结论
本文研究了考虑物联网设备移动性的无人机辅助边缘计算网络中的智能路径规划问题。具体而言,我们提出了一种基于深度强化学习的路径规划算法,旨在不仅最大化在无人机上卸载和执行的数据比特数量,同时最小化无人机在飞行和计算操作中的能耗。大量仿真结果验证了所提算法的有效性。在未来的工作中,我们计划为多个无人机辅助边缘计算网络开发多智能体路径规划与资源分配方案,其中无人机可以协作执行移动设备的计算任务。


















 1406
1406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









