




定义:具有超大规模参数的预训练语言模型
架构:Transformer解码器架构
训练:预训练(base model) 后训练(instruct model)
预训练阶段可以理解为学习知识的过程,而后训练阶段可以理解为学习解题的过程。
预训练时,为了有好的学习基础,所以数据数量和数据质量非常重要。
后训练阶段,可以理解为练题阶段,一是指令微调(Instruction Tuning),方法是使用输入于输出配对的指令,目的是提升任务求解能力。二是人类对齐(Human Alignment),想要模型输出的结果好(符合人类的期望需求),需要加入评判,引入基于人类反馈的强化学习方法(RLHF)。
大模型的训练过程在数据和算力方面投入都很大,似乎投入越大能力越强?
扩展定律说明了这点:通过扩展参数规模、数据规模、计算能力,大模型的能力会显著提升
KM扩展定律:OpenAI团队建立的神经语言模型性能与参数规模(N)、数据规模(D)、计算算力(C)之间的幂律关系
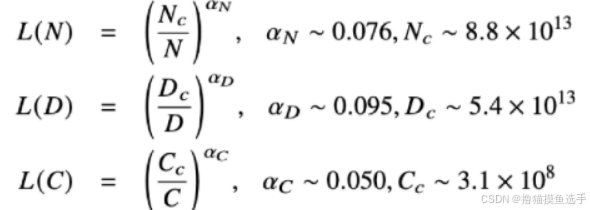
Chinchilla扩展定律:DeepMind团队2022年提出的另一种形式的扩展定律
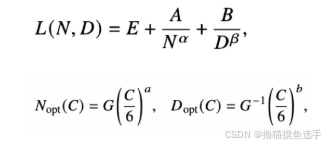
模型的语言建模损失:不可约损失(真实数据分布的熵)+可约损失(真实和模型的KL散度,可通过优化减少)
扩展定律可能存在边际效益递减
可预测的扩展:
小模型预估大模型
训练过程中模型早期性能预估后续性能
涌现能力:在小模型中不存在、但在大模型中出现的能力
代表性能力:指令遵循、上下文学习、逐步推理
涌现能力和扩展定律是两种描述规模效应的度量方法


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









