




这里写自定义目录标题
0 数据竞赛的tips
- 赛题理解
- 赛题分析
- 数据探索
- 数据处理\特征工程
- 数据的预处理
- 特征构造
- 特征选择
- 训练模型
- 模型选择
- 模型优化
- 模型融合
- 预测提交
1 赛题背景
引用datawhale学习文档给出的“我们只有理解业务逻辑,才能避免做出 “准确但没用” 的AI”,先分析和理解一下赛题的背景,官方给出的赛题背景如下:

总结一下即是:电商直播及短视频的发展带来了丰富的带货视频和用户互动数据,这些用户互动数据代表者消费者对商品体验的直接反馈,用户的反馈信息是驱动商业决策的重要考量。
从商业逻辑上理解,带货视频和交互信息是既有的数据,通过数据分析我们可以了解用户真实的态度和反馈、也可以反向评估带货视频的质量,生成用户画像,驱动营销决策。感觉在实际应用中,贴近于消费品市场做营销投入决策或者收集用户反馈来改进产品。
回到这个赛题,数据的来源、应用场景和目标简单来说如下:
数据来源:短视频平台的海量带货视频及用户互动数据
数据应用:商品体验反馈 -> 驱动商业决策的价值
核心目标:将电商直播带货视频的碎片化用户评论转化为可量化的商业洞察信息
对于这个赛题,按逻辑拆分,需要先找到每个视频识别的产品是什么,每个用户评价的内容情感是什么、最后聚类形成用户对产品的评价。即首先基于视频内容建立商品关联关系,进而从非结构化评论中提取情感倾向,最终通过聚类总结形成结构化洞察。
这个逻辑链将这个task分成了三阶段任务:
1)(文本编码)视频内容 -》识别推广商品
2)(文本分类)情感分析 -》评论文本多维度情感分析
3)(文本聚类)评论聚类 -》对归属指定维度的评论进行聚类
2 数据解读及官方例子的baseline学习
了解数据
比赛提供了两个csv文件,是两类文本数据,origin_videos_data.csv (带货视频数据,85条) 和 origin_comments_data.csv (评论文本数据,6477条)。
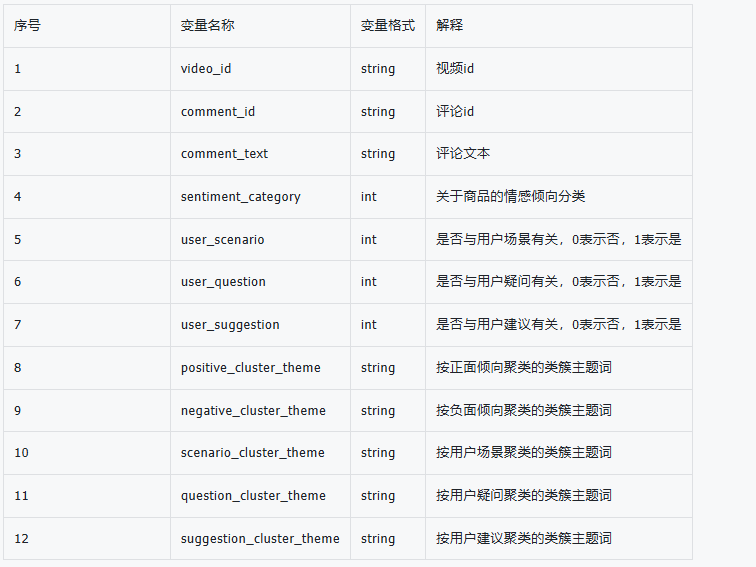
带货视频的数据格式:

评论区文本信息的数据格式:1-3是原始信息,4-7需要进行情感分析得出,8-12需要进行聚类分析
赛事要求的输出,是提交submit.zip压缩包文件,内含submit文件夹,文件内为submit_videos.csv(内含字段video_id, product_name)和submit_comments.csv。也就是说,对于输入的两个csv文件,需要把origin_videos_data.csv的product_name和origin_comments_data.csv的4-12的数据经算法分析后填上去。
baseline的开始是读取数据和了解具体的数据内容:
读取数据:

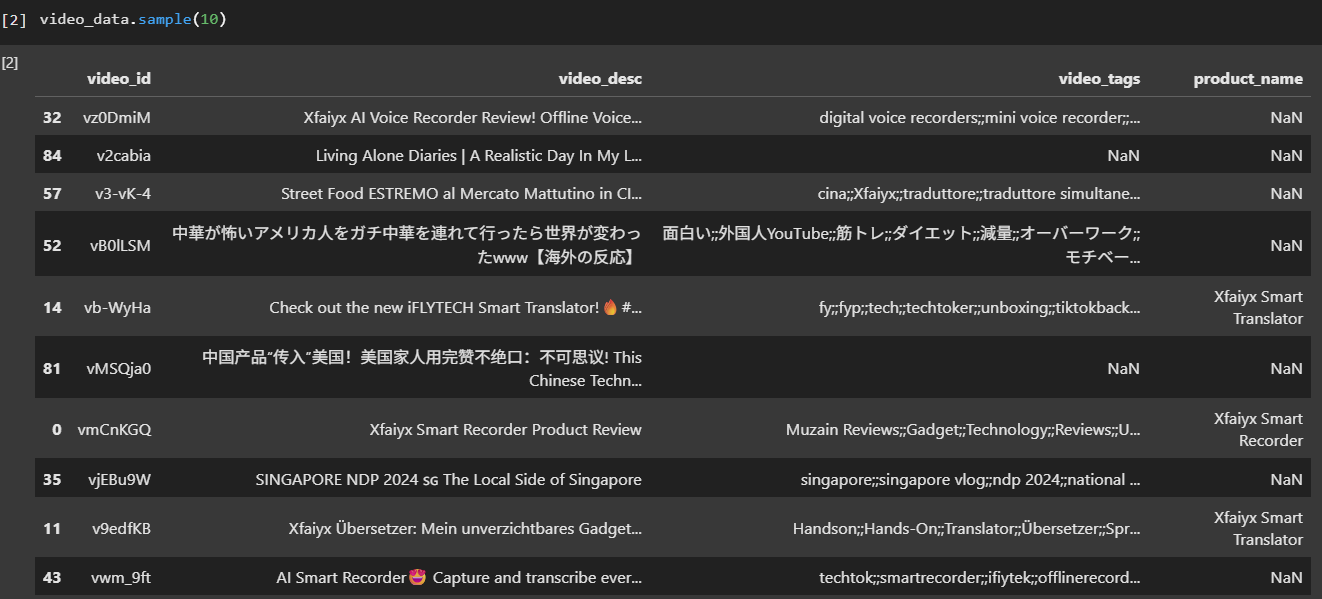
video数据,可以看到video文本数据是多语言的,tags也有空值的情况
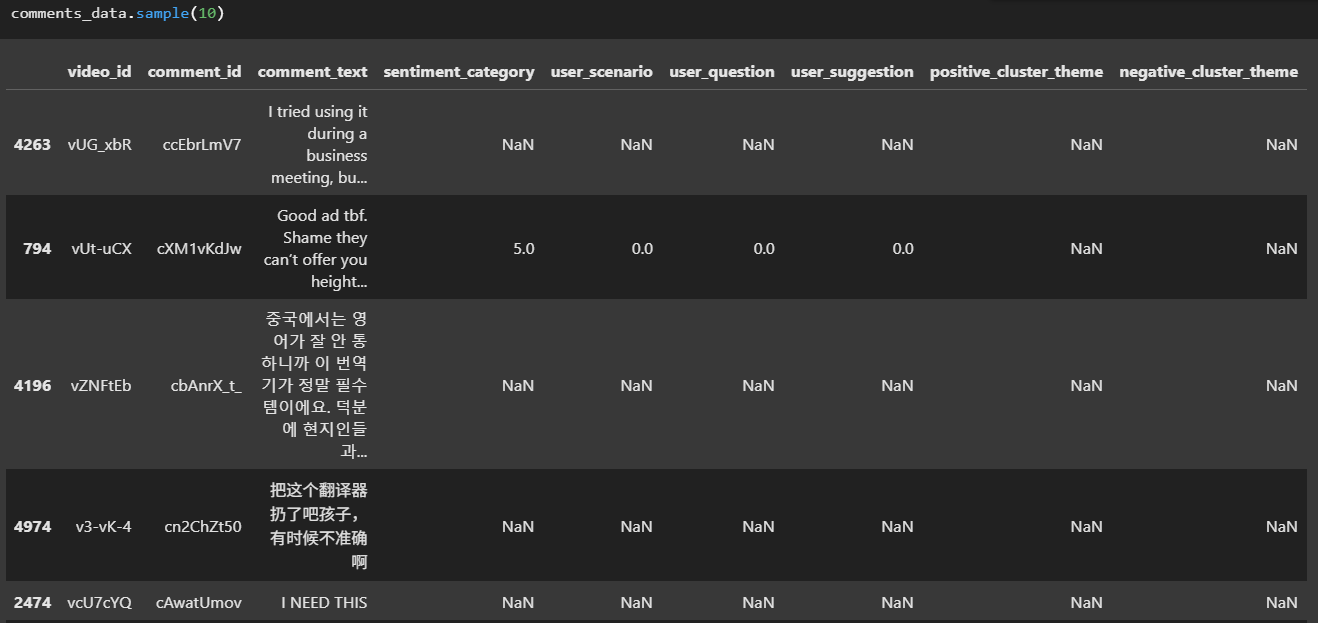
comments数据:
task1识别商品(文本编码)
将描述和标签文本合并成"text"变量:
video_data["text"] = video_data["video_desc"].fillna("") + " " + video_data["video_tags"].fillna("")
创建pipeline:pipeline是scikit-learn提供的,可以将数据处理、特征训练、模型训练等组合成一个流程
product_name_predictor = make_pipeline(
TfidfVectorizer(tokenizer=jieba.lcut, max_features=50), SGDClassifier()
)
这里的TfidfVectorizer的作用在于将文本转化为TF-IDF特征矩阵。
TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文件频率),用于资讯检索的常用加权技术。它是一种统计方法,评估一个字词对于它所在文本的重要程度。如果一个词在一篇文章中出现次数越多,同时在所有文档中出现次数越少,越能够代表该文章。
tokenizer=jieba.lcut 这个表明使用jieba进行分词,jieba.lcut用于将中文句子切分成词语列表。
TfidfVectorizer将按照TF-IDF的算法算出分词后的词语列表的代表性情况,词语列表和对应的TF-IDF值构成了TF-IDF特征矩阵。max_features=50设置了最多只保留最重要的50个特征(词)。
SGDClassifier表示使用随机梯度下降(SGD)的分类器,它默认使用线性SVM作为损失函数。
product_name_predictor.fit(
video_data[~video_data["product_name"].isnull()]["text"],
video_data[~video_data["product_name"].isnull()]["product_name"],
)
video_data["product_name"] = product_name_predictor.predict(video_data["text"])
product_name_predictor.fit 模型训练。~video_data["product_name"].isnull()表明使用product_name不为空的数据进行训练(也就是标注好的数据),text是特征,product_name是标签。
product_name_predictor.predict(video_data[“text”]) 预测。使用训练好的product_name_predictor对整个数据集进行预测,预测结果更新到profuct_name。
task2 用户评论情感分析(文本分类)
文本分类是根据文本内容将其自动归类到预定义类别的任务。
在这个task中,我们需要通过用户评论comment_text这个数据,去分类。sentiment_category情感倾向类别,‘user_scenario’, ‘user_question’, 'user_suggestion’则分别表示是否与用户场景、疑惑、建议有关。
for col in ['sentiment_category',
'user_scenario', 'user_question', 'user_suggestion']:
predictor = make_pipeline(
TfidfVectorizer(tokenizer=jieba.lcut), SGDClassifier()
)
predictor.fit(
comments_data[~comments_data[col].isnull()]["comment_text"],
comments_data[~comments_data[col].isnull()][col],
)
comments_data[col] = predictor.predict(comments_data["comment_text"])
这一步的处理和task1相似,从comments文本中进行分词,按照TF-IDF进行统计加权,形成TF-IDF特征矩阵。然后对于每项使用标注好的数据进行训练,训练好后在整个数据集上进行预测结果更新。
task3 评论聚类(文本聚类)
文本聚类是根据文本内容的相似性,将文本自动分组,而无需预先定义类别。
对于该task需进行聚类的字段包括:
positive_cluster_theme:基于训练集和测试集中正面倾向(sentiment_category=1 或 sentiment_category=3)的评论进行聚类并提炼主题词,聚类数范围为 5~8。negative_cluster_theme:基于训练集和测试集中负面倾向(sentiment_category=2 或 sentiment_category=3)的评论进行聚类并提炼主题词,聚类数范围为 5~8。scenario_cluster_theme:基于训练集和测试集中用户场景相关评论(user_scenario=1)进行聚类并提炼主题词,聚类数范围为 5~8。question_cluster_theme:基于训练集和测试集中用户疑问相关评论(user_question=1)进行聚类并提炼主题词,聚类数范围为 5~8。suggestion_cluster_theme:基于训练集和测试集中用户建议相关评论(user_suggestion=1)进行聚类并提炼主题词,聚类数范围为 5~8。
我们先来看第一个聚类任务,对positive_cluster_theme进行聚类:
# 1.管道构建,训练与预测
kmeans_predictor = make_pipeline(
TfidfVectorizer(tokenizer=jieba.lcut), KMeans(n_clusters=2)
)
kmeans_predictor.fit(comments_data[comments_data["sentiment_category"].isin([1, 3])]["comment_text"])
kmeans_cluster_label = kmeans_predictor.predict(comments_data[comments_data["sentiment_category"].isin([1, 3])]["comment_text"])
# 2.提取聚类主题词
kmeans_top_word = []
tfidf_vectorizer = kmeans_predictor.named_steps['tfidfvectorizer']
kmeans_model = kmeans_predictor.named_steps['kmeans']
feature_names = tfidf_vectorizer.get_feature_names_out()
cluster_centers = kmeans_model.cluster_centers_
for i in range(kmeans_model.n_clusters):
top_feature_indices = cluster_centers[i].argsort()[::-1]
top_word = ' '.join([feature_names[idx] for idx in top_feature_indices[:top_n_words]])
kmeans_top_word.append(top_word)
# 3.保存主题标签
comments_data.loc[comments_data["sentiment_category"].isin([1, 3]), "positive_cluster_theme"] = [kmeans_top_word[x] for x in kmeans_cluster_label]
(1)kmeans_predictor =>构造pipeline,和前两个不一样的是这里使用KMeans聚类分析方法。n_clusters=2表明将文本聚类为 2 个主题,在这里表示正负情感。
(2)kmeans_predictor.fit 和 kmeans_predictor.predict=>训练和预测,仅对 sentiment_category=1或3 的评论聚类,fit是训练步骤,kmeans_cluster_label是拿到聚类的结果。
(3)tfidf_vectorizer = kmeans_predictor.named_steps['tfidfvectorizer']和kmeans_model = kmeans_predictor.named_steps['kmeans'] 中的named_steps 通过步骤名访问管道中的各个组件。feature_names是获取的TF-IDF向量的所有特征名称(即分词后的词汇表),cluster_centers是K-Means模型的属性,形状为(n_clusters, n_features)的数组。每一行代表一个簇的中心点,数值表示该簇中每个特征的权重(TF-IDF值的均值)
(4)cluster_centers[i] 是第i个簇的中心点向量,argsort()[::-1]表明按照从大到小的排序,也就是中心点权重高的排在前面,top_word = ' '.join([feature_names[idx] for idx in top_feature_indices[:top_n_words]])取出排名前top_n_words(上文的自定义值,为10)的这些关键词组合形成字符串作为top_word。
我们可以加一个print打印看看,最后的kmeans_top_word值:
print(kmeans_top_word)
# 测试输出:[' . it the , i for ! a is', ' ! ? i ! love , 요 我 的']
(5)最后是回填聚类后提炼的高权重关键词,也就是主题词。
后面几个聚类其实是类似的算法,区别在于kmeans_predictor fit和predict 根据实际要聚类的字段进行修改。
3 小白的学习总结和回顾
官方给的baseline写得很清晰简洁,很好地划分了几个task。代码和模型上在查资料和问AI的基础上慢慢理解,整体流程上,拆分下来还是数据预处理、特征选择构造、预训练和预测提交,虽然在实际的代码里,有很多封装起来的东西,乍一看没那么好理解。

















 1007
1007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









