



前言
在当今的Web开发中,性能优化是一个永恒的话题。而浏览器缓存作为前端性能优化的重要手段,却常常被开发者忽视或误解。正确理解和应用浏览器缓存,可以显著提升网站的加载速度,改善用户体验,同时减轻服务器的负担。
这篇文章将以通俗易懂的方式,带你深入了解浏览器缓存的工作原理、不同类型的缓存策略以及在实际开发中的应用技巧。无论你是前端新手还是有经验的开发者,都能从中获得实用的知识,让你的网站加载速度更快、用户体验更好。
一、浏览器缓存基础
1.1 什么是浏览器缓存?
浏览器缓存是指浏览器将用户请求过的静态资源(如HTML、CSS、JavaScript、图片等)存储在本地磁盘或内存中,当用户再次访问同一个网站时,浏览器可以直接从本地加载这些资源,而不必重新从服务器下载,从而提高页面加载速度,减少网络流量。
简单来说,浏览器缓存就像是你电脑里的一个"资源仓库",存放着你经常访问的网站的各种文件。当你再次访问这些网站时,浏览器会先检查这个仓库,如果有需要的文件,就直接拿出来使用,省去了重新下载的时间。
1.2 浏览器缓存的好处
- 提升网站加载速度:直接从本地加载资源,减少了网络请求时间
- 降低带宽消耗:减少了重复资源的下载,节省用户的网络流量
- 减轻服务器负担:减少了对服务器的请求次数,降低服务器压力
- 改善用户体验:页面加载更快,减少用户等待时间
- 支持离线访问:某些缓存策略可以让用户在没有网络的情况下也能访问网站的部分内容
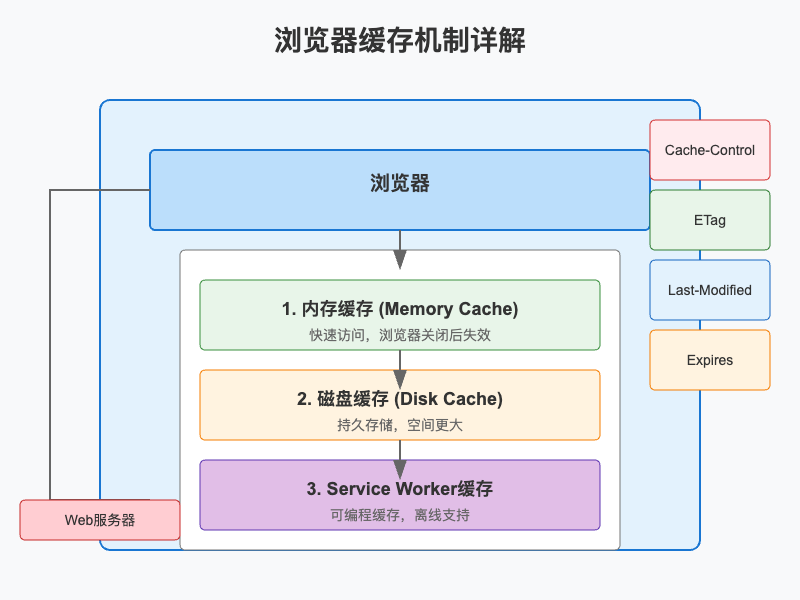
二、浏览器缓存的类型
浏览器缓存主要分为三种类型:内存缓存、磁盘缓存和Service Worker缓存。它们各自有不同的特点和应用场景。
2.1 内存缓存 (Memory Cache)
内存缓存是浏览器缓存中最快的一种,它将资源存储在浏览器的内存中。
特点:
- 读取速度最快,因为内存的访问速度远快于磁盘
- 容量有限,不能存储大量数据
- 浏览器关闭后,内存缓存会被清空
- 主要存储脚本、样式表等频繁使用的资源
应用场景:
- 同一页面内频繁使用的资源
- 临时需要但不需要持久化的资源
2.2 磁盘缓存 (Disk Cache)
磁盘缓存是浏览器将资源存储在用户的硬盘上,是最常见的缓存类型。
特点:
- 存储容量较大,可以存储更多的资源
- 读取速度比内存缓存慢,但比网络请求快得多
- 浏览器关闭后依然存在,除非手动清除
- 可以存储各种类型的资源,包括图片、视频、脚本、样式表等
应用场景:
- 不经常变化的静态资源
- 用户可能会再次访问的页面资源
- 需要长期保存的资源
2.3 Service Worker缓存
Service Worker缓存是一种可编程的缓存机制,是现代Web应用中实现离线功能的关键。
特点:
- 完全由开发者控制缓存的策略和逻辑
- 支持离线访问,可以让网站在没有网络的情况下也能工作
- 可以缓存任意类型的资源,包括HTML页面、API请求等
- 需要HTTPS环境才能使用
应用场景:
- Progressive Web Apps (PWA) 应用
- 需要离线功能的网站
- 需要自定义缓存策略的复杂应用
三、HTTP缓存策略
HTTP协议提供了多种缓存控制机制,通过在HTTP头部设置相应的字段,开发者可以精确地控制资源的缓存行为。下面是强缓存和协商缓存的详细对比:
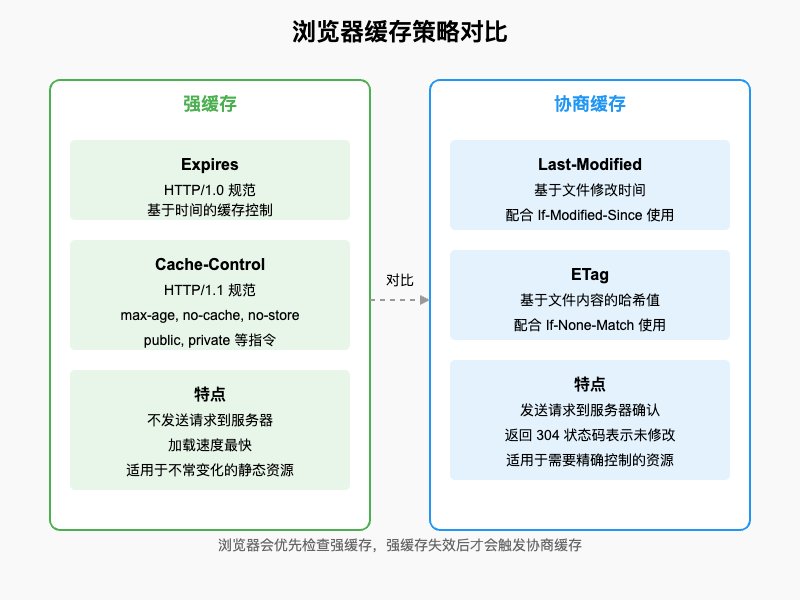
3.1 强缓存
强缓存是指浏览器直接从本地缓存中读取资源,不发送请求到服务器。强缓存可以通过两种HTTP头部字段来控制:Expires和Cache-Control。
3.1.1 Expires
Expires是HTTP/1.0的字段,表示资源的过期时间。当浏览器再次请求该资源时,如果当前时间小于Expires的值,就直接使用缓存;否则,就会发送请求到服务器获取新的资源。
示例:
Expires: Wed, 21 Oct 2025 07:28:00 GMT
缺点:
- 依赖于客户端的本地时间,如果客户端时间与服务器时间不同步,可能会导致缓存失效或缓存过期
- 属于HTTP/1.0规范,现代Web开发中已逐渐被
Cache-Control取代
3.1.2 Cache-Control
Cache-Control是HTTP/1.1的字段,提供了更精细的缓存控制能力。它可以包含多个指令,用逗号分隔。
常用指令:
-
max-age:指定资源从被请求开始可以被缓存的最长时间(单位:秒)
Cache-Control: max-age=3600 # 缓存1小时 -
no-cache:表示资源可以被缓存,但在使用之前必须向服务器确认资源是否有更新
Cache-Control: no-cache -
no-store:表示资源不应该被缓存,每次都需要从服务器获取新的资源
Cache-Control: no-store -
public:表示资源可以被任何缓存(包括浏览器、代理服务器等)缓存
Cache-Control: public, max-age=3600 -
private:表示资源只能被浏览器缓存,不能被代理服务器等中间缓存缓存
Cache-Control: private, max-age=3600
Cache-Control的优先级高于Expires,如果两者同时存在,浏览器会优先使用Cache-Control。
3.2 协商缓存
协商缓存是指浏览器在使用缓存资源之前,会先向服务器发送一个请求,询问资源是否有更新。如果资源没有更新,服务器会返回304状态码,浏览器继续使用缓存;如果资源有更新,服务器会返回新的资源和200状态码。
协商缓存主要通过两对HTTP头部字段来实现:Last-Modified/If-Modified-Since和ETag/If-None-Match。
3.2.1 Last-Modified / If-Modified-Since
- Last-Modified:服务器在响应头中设置,表示资源的最后修改时间
- If-Modified-Since:浏览器在请求头中设置,值为之前服务器返回的
Last-Modified值,用于询问服务器资源是否在该时间之后有修改
工作流程:
- 浏览器第一次请求资源,服务器返回资源,并在响应头中设置
Last-Modified: Wed, 21 Oct 2025 07:28:00 GMT - 浏览器再次请求该资源时,在请求头中设置
If-Modified-Since: Wed, 21 Oct 2025 07:28:00 GMT - 服务器比较请求头中的时间与资源的实际修改时间
- 如果资源没有修改,返回304状态码,不返回资源内容
- 如果资源已修改,返回200状态码和新的资源内容,并更新
Last-Modified值
3.2.2 ETag / If-None-Match
- ETag:服务器在响应头中设置,表示资源的唯一标识符,通常是基于资源内容生成的哈希值
- If-None-Match:浏览器在请求头中设置,值为之前服务器返回的
ETag值,用于询问服务器资源的标识符是否有变化
工作流程:
- 浏览器第一次请求资源,服务器返回资源,并在响应头中设置
ETag: "abc123" - 浏览器再次请求该资源时,在请求头中设置
If-None-Match: "abc123" - 服务器比较请求头中的ETag与资源的当前ETag
- 如果ETag相同(资源没有变化),返回304状态码,不返回资源内容
- 如果ETag不同(资源已变化),返回200状态码和新的资源内容,并更新
ETag值
ETag的优势:
- 比
Last-Modified更精确,因为它基于资源内容生成 - 可以识别
Last-Modified无法识别的变化,比如文件内容变化但修改时间不变的情况 - 可以自定义生成策略,更灵活
四、缓存策略的选择与应用
4.1 不同类型资源的缓存策略
针对不同类型的资源,我们应该选择不同的缓存策略:
4.1.1 静态资源(CSS、JavaScript、图片等)
- 策略:设置较长的缓存时间(如1年),结合文件名哈希或版本号
- 配置示例:
Cache-Control: public, max-age=31536000 - 注意事项:当资源更新时,需要修改文件名(如添加哈希值),以确保用户能获取到新的资源
4.1.2 HTML页面
- 策略:通常不设置强缓存,或设置较短的缓存时间,主要使用协商缓存
- 配置示例:
Cache-Control: no-cache - 原因:HTML页面通常包含动态内容或引用其他资源的链接,需要确保用户能获取到最新的页面结构
4.1.3 API请求和动态内容
- 策略:根据内容的更新频率设置适当的缓存时间,或使用协商缓存
- 配置示例:
Cache-Control: max-age=600(缓存10分钟)或Cache-Control: no-cache - 注意事项:对于用户特定的内容,可能需要使用
private指令,防止被共享缓存存储
4.1.4 协商缓存的选择场景与应用
协商缓存是一种灵活的缓存策略,特别适用于以下场景:
协商缓存的最佳选择场景
-
动态内容但更新不频繁
- 适用于那些内容会变化但更新频率不高的页面或资源
- 例如:博客文章、新闻详情页、产品详情页等
- 这些内容需要保证用户能看到最新版本,但又不需要每次都重新下载完整内容
-
资源体积较大
- 对于体积较大的资源(如大型JavaScript文件、高清图片等),使用协商缓存可以避免不必要的完整下载
- 即使资源有更新,也可以通过304响应节省带宽和加载时间
-
需要精确控制缓存过期
- 当需要比时间更精确的缓存控制时,ETag可以基于内容变化提供更准确的缓存判断
- 特别适用于那些内容更新但修改时间未变的情况
-
HTML页面缓存
- HTML页面通常作为应用的入口点,需要确保能获取最新的资源引用
- 对HTML页面使用协商缓存可以保证用户总能获取到最新的页面结构,同时避免不必要的完整下载
协商缓存的实际应用案例
案例一:新闻网站文章页面
新闻网站的文章页面通常内容相对稳定,但可能会有更新(如更正、更新时间戳等)。使用协商缓存可以:
// 服务端配置示例(Node.js + Express)
app.get('/articles/:id', (req, res) => {
const articleId = req.params.id;
const article = getArticleById(articleId);
const currentETag = generateETag(article.content); // 基于文章内容生成ETag
// 检查If-None-Match头部
if (req.headers['if-none-match'] === currentETag) {
return res.status(304).end(); // 资源未变化,返回304
}
// 设置ETag头部并返回文章内容
res.set('ETag', currentETag);
res.set('Cache-Control', 'no-cache'); // 强制每次请求都进行协商
res.render('article', { article });
});
案例二:电子商务产品详情页
产品详情页可能会有价格更新、库存变化等,但页面大部分内容保持不变:
// 客户端实现智能缓存策略
async function fetchProductDetails(productId) {
const url = `/api/products/${productId}`;
const headers = {};
// 检查是否有之前存储的ETag
const cachedETag = localStorage.getItem(`product_${productId}_etag`);
if (cachedETag) {
headers['If-None-Match'] = cachedETag;
}
try {
const response = await fetch(url, { headers });
if (response.status === 304) {
// 资源未变化,使用本地缓存的产品数据
const cachedProduct = JSON.parse(localStorage.getItem(`product_${productId}_data`));
return cachedProduct;
} else if (response.ok) {
// 资源已更新,获取新数据并更新缓存
const product = await response.json();
const newETag = response.headers.get('ETag');
// 存储新数据和ETag
localStorage.setItem(`product_${productId}_data`, JSON.stringify(product));
localStorage.setItem(`product_${productId}_etag`, newETag);
return product;
}
} catch (error) {
console.error('获取产品详情失败:', error);
// 发生错误时,尝试使用本地缓存
const cachedProduct = localStorage.getItem(`product_${productId}_data`);
return cachedProduct ? JSON.parse(cachedProduct) : null;
}
}
案例三:单页应用(SPA)中的API请求优化
在SPA应用中,可以为API请求实现统一的协商缓存处理机制:
// API服务封装,带协商缓存支持
class ApiService {
constructor() {
this.etagCache = new Map();
}
async fetchWithCache(url, options = {}) {
// 准备请求头,添加If-None-Match
const headers = { ...options.headers };
const cachedETag = this.etagCache.get(url);
if (cachedETag) {
headers['If-None-Match'] = cachedETag;
}
const response = await fetch(url, { ...options, headers });
// 处理304响应
if (response.status === 304) {
// 返回缓存的响应数据,这里简化处理
console.log('使用协商缓存:', url);
return { fromCache: true };
}
// 处理200响应,更新ETag缓存
if (response.ok) {
const newETag = response.headers.get('ETag');
if (newETag) {
this.etagCache.set(url, newETag);
}
const data = await response.json();
return { data, fromCache: false };
}
// 处理其他响应状态
throw new Error(`API请求失败: ${response.status}`);
}
}
// 使用示例
const apiService = new ApiService();
async function loadUserProfile() {
try {
const result = await apiService.fetchWithCache('/api/user/profile');
if (result.data) {
updateUserInterface(result.data);
} else if (result.fromCache) {
console.log('用户资料未更新,继续使用当前显示');
}
} catch (error) {
console.error('加载用户资料失败:', error);
}
}
通过这些实际案例可以看出,协商缓存特别适合那些需要平衡性能和新鲜度的场景。它既能保证用户在资源未变化时获得快速的加载体验,又能确保在资源更新时及时获取到最新版本。
- 策略:设置较长的缓存时间(如1年),结合文件名哈希或版本号
- 配置示例:
Cache-Control: public, max-age=31536000 - 注意事项:当资源更新时,需要修改文件名(如添加哈希值),以确保用户能获取到新的资源
4.1.2 HTML页面
- 策略:通常不设置强缓存,或设置较短的缓存时间,主要使用协商缓存
- 配置示例:
Cache-Control: no-cache - 原因:HTML页面通常包含动态内容或引用其他资源的链接,需要确保用户能获取到最新的页面结构
4.1.3 API请求和动态内容
- 策略:根据内容的更新频率设置适当的缓存时间,或使用协商缓存
- 配置示例:
Cache-Control: max-age=600(缓存10分钟)或Cache-Control: no-cache - 注意事项:对于用户特定的内容,可能需要使用
private指令,防止被共享缓存存储
4.2 前端框架中的缓存策略实现
现代前端框架通常提供了内置的缓存策略支持或相应的插件。下面是一些常见框架中的实现方式:
4.2.1 Webpack中的缓存配置
Webpack提供了一套完整的缓存优化方案,通过以下配置可以最大化利用浏览器缓存,实现精确的资源更新控制:
// webpack.config.js
module.exports = {
output: {
filename: '[name].[contenthash].js', // 使用内容哈希作为文件名的一部分
chunkFilename: '[name].[contenthash].chunk.js'
},
optimization: {
moduleIds: 'deterministic', // 确保模块ID的稳定性
runtimeChunk: 'single', // 将运行时代码提取为单独的文件
splitChunks: {
cacheGroups: {
vendor: {
test: /[\\/]node_modules[\\/]/,
name: 'vendors',
chunks: 'all'
}
}
}
}
};
配置详解:
-
内容哈希命名策略
output: { filename: '[name].[contenthash].js', chunkFilename: '[name].[contenthash].chunk.js' }- 这是最核心的缓存策略,为每个输出文件生成基于文件内容的唯一哈希值
- 当文件内容不变时,哈希值保持不变,浏览器会继续使用缓存的版本
- 当文件内容变化时,哈希值改变,导致文件名变化,浏览器会自动下载新文件
- 完美解决了"静态资源更新但浏览器仍使用旧缓存"的问题
-
稳定的模块ID
optimization: { moduleIds: 'deterministic' }- 确保即使在添加或删除其他模块的情况下,未修改模块的ID也保持不变
- 防止因模块ID变化导致内容未变的文件哈希值变化
- 确保只有真正修改的文件才会触发浏览器重新下载
-
运行时代码分离
optimization: { runtimeChunk: 'single' }- 将Webpack的运行时代码(负责模块加载和依赖管理的代码)提取到单独的文件中
- 防止运行时代码的变化影响其他模块的哈希值
- 允许应用代码和第三方库代码在运行时代码更新时保持缓存
-
第三方库代码分离
splitChunks: { cacheGroups: { vendor: { test: /[\\/]node_modules[\\/]/, name: 'vendors', chunks: 'all' } } }- 将所有来自node_modules的第三方库代码提取到单独的文件中
- 第三方库通常比业务代码更稳定,更新频率低
- 分离后可以让第三方库长期缓存,显著提高加载速度
- 当业务代码更新时,不需要重新下载未变化的第三方库
工作流程:
- 构建阶段:Webpack根据上述配置生成带有内容哈希的文件
- 部署阶段:更新的资源(带新哈希)和未更新资源(带旧哈希)一起部署
- 用户访问阶段:
- 浏览器请求HTML文件(通常不缓存或缓存时间短)
- HTML中引用的资源URL包含哈希值
- 对于未变化的资源,浏览器使用本地缓存
- 对于变化的资源,浏览器下载新文件并缓存
通过这种配置,网站可以实现"精确缓存" - 只重新加载真正变化的资源,最大限度地利用浏览器缓存,显著提升用户体验和网站性能。
4.2.2 Service Worker缓存实现
// service-worker.js
self.addEventListener('install', event => {
event.waitUntil(
caches.open('my-app-cache-v1')
.then(cache => {
return cache.addAll([
'/',
'/index.html',
'/styles.css',
'/app.js',
'/images/logo.png'
]);
})
);
});
self.addEventListener('fetch', event => {
event.respondWith(
caches.match(event.request)
.then(response => {
// 缓存命中,直接返回缓存的资源
if (response) {
return response;
}
// 缓存未命中,从网络获取资源
return fetch(event.request).then(fetchResponse => {
// 将新获取的资源添加到缓存中
return caches.open('my-app-cache-v1').then(cache => {
cache.put(event.request, fetchResponse.clone());
return fetchResponse;
});
});
})
);
});
// 在主JavaScript文件中注册Service Worker
if ('serviceWorker' in navigator) {
window.addEventListener('load', () => {
navigator.serviceWorker.register('/service-worker.js')
.then(registration => {
console.log('Service Worker 注册成功:', registration);
})
.catch(error => {
console.log('Service Worker 注册失败:', error);
});
});
}
五、缓存的常见问题与解决方案
5.1 缓存更新问题
问题:用户无法及时获取到更新后的资源,仍然看到旧版本的网站
解决方案:
- 使用内容哈希或版本号作为文件名的一部分
- 对于关键资源,使用
Cache-Control: no-cache指令 - 发布新版本时,可以考虑使用新的缓存命名空间
- 对于HTML页面,可以添加适当的meta标签控制缓存
<meta http-equiv="Cache-Control" content="no-cache, no-store, must-revalidate" />
<meta http-equiv="Pragma" content="no-cache" />
<meta http-equiv="Expires" content="0" />
5.2 缓存一致性问题
问题:不同资源之间的版本不一致,导致页面功能异常
解决方案:
- 使用统一的构建系统管理资源版本
- 确保相关的资源一起更新,避免部分更新
- 对于重要的资源组合,可以考虑使用缓存清单或Service Worker统一管理
5.3 调试缓存问题
问题:在开发过程中,缓存可能会干扰调试,导致无法看到最新的修改
解决方案:
- 在开发环境中禁用缓存,或设置较短的缓存时间
- 使用浏览器的开发工具进行缓存调试(如Chrome DevTools的Network面板)
- 使用浏览器的"禁用缓存"选项(通常在开发工具的Network面板中)
- 在URL中添加查询参数(如
?v=1.0)来绕过缓存
六、浏览器缓存最佳实践
6.1 合理设置缓存时间
- 对于不经常变化的资源,设置较长的缓存时间(如1年)
- 对于经常变化的资源,使用协商缓存或设置较短的缓存时间
- 对于用户特定的敏感数据,可以考虑不缓存或使用
private指令
6.2 版本控制与文件名哈希
- 使用内容哈希(如MD5、SHA)作为文件名的一部分
- 当资源内容变化时,文件名也会变化,自动触发重新下载
- 结合构建工具(如Webpack、Vite等)自动生成带哈希的文件名
6.3 合理使用不同类型的缓存
- 内存缓存:适用于频繁访问的小资源
- 磁盘缓存:适用于不经常变化的大资源
- Service Worker缓存:适用于需要离线功能或自定义缓存策略的应用
6.4 监控和优化缓存效果
- 使用浏览器开发工具分析缓存命中率
- 通过性能监控工具(如Lighthouse、WebPageTest等)评估缓存效果
- 根据实际使用情况,不断调整和优化缓存策略
七、总结
浏览器缓存是前端性能优化中最简单、最有效的手段之一。通过本文的介绍,相信你已经对浏览器缓存的工作原理、不同类型的缓存策略以及在实际开发中的应用技巧有了全面的了解。
正确应用浏览器缓存,可以显著提升网站的加载速度,改善用户体验,同时减轻服务器的负担。在实际开发中,我们应该根据不同类型的资源和应用场景,选择合适的缓存策略,并结合构建工具和现代Web技术,实现更高效、更可靠的缓存机制。
记住,缓存策略不是一成不变的,需要根据项目的实际情况和用户反馈不断优化和调整。希望本文能够帮助你更好地理解和应用浏览器缓存,让你的网站性能更上一层楼!
个人重磅上线数规规排五助手:让彩票选号变得更智能的专业工具
在数字彩票的世界里,每一注号码都承载着彩民的希望与期待。然而,面对复杂的数字组合和变幻莫测的开奖规律,许多彩民常常感到无从下手。今天,我要向大家介绍一款能够帮助您提升选号效率和准确性的专业工具——数规规排五助手。
为什么需要排五助手?
排列五彩票作为一种数字型彩票,其玩法简单但选号却并不容易。许多彩民在选号时往往依赖直觉或者简单的随机选择,这种方式虽然充满乐趣,但在长期参与中很难获得理想的回报。
排五助手正是为了解决这一痛点而诞生的。它不仅仅是一个简单的随机数生成器,更是一个集数据分析、趋势预测和智能算法于一体的综合性选号工具。
程序员也要有点娱乐生活,搞不好就中个排列五了呢?
感兴趣可以微信搜索"数规规排五助手"体验体验!
如果觉得本文有用,欢迎点个赞👍+收藏🔖+关注支持我呗!

















 2630
2630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









