 用Python库VideoFileClip读MP4视频长度代码
用Python库VideoFileClip读MP4视频长度代码





 博客主要介绍了使用Python进行音视频开发时,安装VideoFileClip库的相关内容,并给出了代码及运行效果。
博客主要介绍了使用Python进行音视频开发时,安装VideoFileClip库的相关内容,并给出了代码及运行效果。
01- 安装库VideoFileClip
pip install -i https://mirrors.aliyun.com/pypi/simple moviepy

02-代码如下:
from moviepy.editor import VideoFileClip
video_path = r"E:\My_Data\视频素材\H-264\V00099E.mp4"
# 加载视频文件
clip = VideoFileClip(video_path)
# 获取视频总时长(以秒为单位)
total_duration = clip.duration
# 打印总时长
print("视频总时长:{} 秒".format(total_duration))
# 关闭视频文件
clip.close()
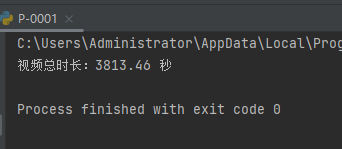
运行效果如下:


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











