




 本文详细介绍了决策树算法(ID3、C4.5和CART)的构建原理、关键方法(如信息增益、信息增益比和基尼系数的选择)、Python实现案例,以及剪枝策略。展示了如何用Python构建决策树进行分类和回归任务,以及如何避免过拟合。
本文详细介绍了决策树算法(ID3、C4.5和CART)的构建原理、关键方法(如信息增益、信息增益比和基尼系数的选择)、Python实现案例,以及剪枝策略。展示了如何用Python构建决策树进行分类和回归任务,以及如何避免过拟合。
目录
一、决策树简介
决策树是一种基于树状结构的机器学习算法,用于分类和回归任务。它通过一系列简单的问题或条件,逐步将数据集划分到不同的类别或值。每个内部节点表示一个特征/属性,每个分支代表一个可能的特征值,而每个叶节点表示一个类别或值。
决策树易于理解和解释,适用于小型到中等规模的数据集,并且能够处理具有非线性关系的数据。常见的决策树算法包括ID3、C4.5、CART等。
二、决策树构建
2.1构建方法
2.2.1 ID3算法
ID3(Iterative Dichotomiser 3)算法是由 Ross Quinlan 在 1986 年提出的,是一种基于信息增益的决策树构建算法。该算法通过选择能够产生最大信息增益的特征来进行节点的分裂,直到所有的数据点都属于同一类别或者达到了预定的停止条件,是决策树的一个经典的构造算法,内部使用:信息熵,信息增益,来进行构建:每次迭代选择信息最大的特征属性作为分割属性。
在ID3算法中:
1.节点纯度的度量用 “信息熵”
2.分裂特征的选择用的是信息增益度作为衡量指标
3.信息熵越低——确定性越高——有序——数据越纯
4.信息增益——以A特征分割后,信息熵减少的越多,那就以为和Gain越大,说明分裂后信息的信息熵更低,数据更纯。
信息熵(Entropy)计算公式:
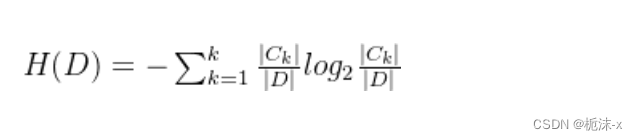
信息条件熵(Conditional Entropy)计算公式:
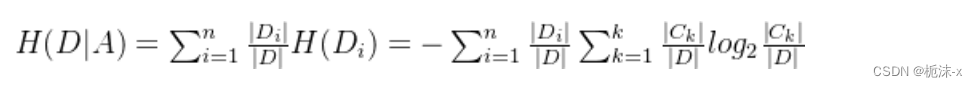
信息增益(Information Gain)计算公式:
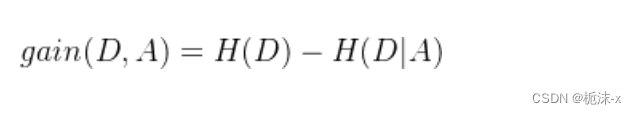
2.2.2 C4.5算法
C4.5算法是ID3算法的改进版本,由 Ross Quinlan 在 1993 年提出。相比于ID3,C4.5算法使用信息增益比来选择特征,这使得它能够更好地处理具有不同数目属性值的特征。此外,C4.5还可以处理连续特征和缺失值。
相比于ID3,C4.5算法:
1.使用信息增益率来取代ID3算法中的信息增益,
2.在树的构造过程中会进行剪枝操作进行优化
3.能够自动完成对连续属性的离散化处理(可以对连续特征进行分裂)
4.C4.5构建的是多分支的决策树;
5.C4.5算法在选中分割属性的时候选择信息增益率最大的属性
信息增益率计算公式:
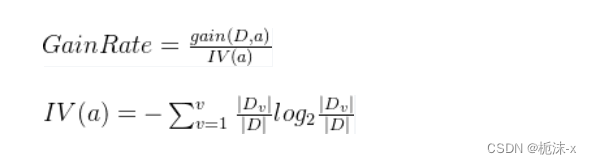
2.2.3 CART算法
CART(classification and regression tree),分类回归树,它既可以用来解决分类问题也可以用来解决回归问题。
划分标准:使用使
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 99
99

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









