







目录
一.分类模型评估简介
在机器学习领域,评估分类模型的性能是至关重要的一步,它可以帮助我们了解模型的准确性和泛化能力。
在分类问题中,准确度(Accuracy)、精确率(Precision)、召回率(Recall)和F1分数是最为常用的评估指标。
二.常见的分类模型评估指标介绍
1.混淆矩阵:用于展示分类器分类结果的统计表格
(1)混淆矩阵是监督学习中的一种用于评估分类模型性能的可视化工具,主要用于模型的分类结果和实例的真实信息的比较 。
(2)使用混淆矩阵的好处在于它能够提供一种直观的方式来理解模型在各个类别上的表现,尤其是在类别不平衡的情况下。例如,如果一个模型在少数类上的召回率很低,即使整体准确率很高,这也可能意味着模型在实际应用中的效果不佳。
(3)在二分类问题中,混淆矩阵通常是一个2x2的表格,用于显示模型预测的正类(通常标记为“1”或正例)和负类(通常标记为“0”或负例)与实际的正类和负类之间的关系。下面是混淆矩阵的基本形式:
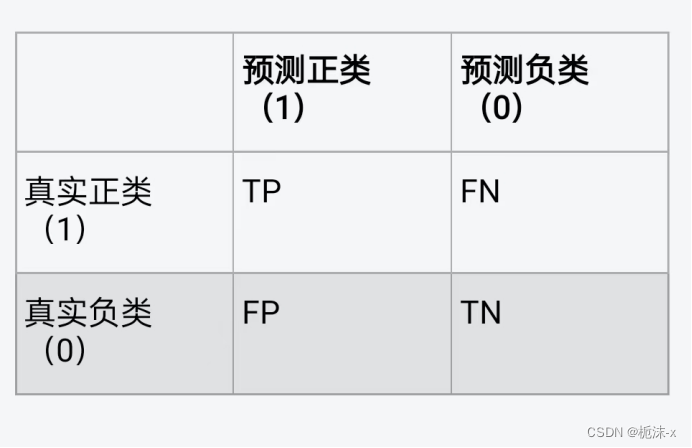
- TP(True Positives):真正例,即实际为正类且被正确预测为正类的样本数量。
- FN(False Negatives):假负例,即实际为正类但被错误预测为负类的样本数量。
- FP(False Positives):假正例,即实际为负类但被错误预测为正类的样本数量。
- TN(True Negatives):真负例,即实际为负类且被正确预测为负类的样本数量。
这些指标可以用来计算各种性能度量,如准确率(Accuracy)、精确率(Precision)、召回率(Recall)以及F1分数(F1 Score)等。
(4)混淆矩阵不仅能够帮助我们识别分类模型可能存在的问题,还能够帮助我们选择合适的模型评估指标,以便更好地优化和调整模型。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









