






最近几乎成为了环境配置领域大神,所谓熟能生巧,之前我在windows搭配了cuda+pytorch开发环境,但是无法实现cuda c编程。后面在wsl2上面安装了cuda+pytorch+cudnn,这次成功实现了cuda c编程,感谢GNU Linux开源系统。
在此之后,我又一次挑战自我,这次是在双系统上面挑战环境配置。当初综合考虑各种原因,给装的是ubuntu24.04LTS版本,虽然版本比较新,但是更加面向未来的开发环境。
配置双系统是一件十分麻烦的事情,单单因为BIOS启动设置的问题,我当初装就失败了两次。后面还是用的是ubuntu24.04,首先不像windows,上面连英伟达驱动都没的。
因此首先要安装英伟达驱动。安装命令如下:
sudo apt-get update
sudo apt install nvidia-utils-535-server安装完成后检查一下:
nvidia-smi有正确输出就表明安装好了。
后面再去安anaconda具体安装命令如下:
wget https://repo.anaconda.com/archive/Anaconda3-2023.07-1-Linux-x86_64.sh
chmod +x Anaconda3-2023.07-1-Linux-x86_64.sh
./Anaconda3-2023.07-1-Linux-x86_64.sh
./Anaconda3-2023.07-1-Linux-x86_64.sh安装好后,要激活一下。
source ~/.bashrc
conda --version
后面新建个环境并启动
conda create --name myenv python==3.8
conda activate myenv同时还要记得在ubuntu上面安装vscode,vscode可视化程度比vim要好。
下面就是安装cuda了,这里的安装命令如下:
sudo apt-get install nvidia-cuda-toolkit我用这个命令安装的是cuda12.2,算是比较新的版本,颇为神奇装cuda的时候特别的快,居然几分钟内就全部完成了。安装好后,新建一个.cu文件在命令行里面跑下就行了。
#include <stdio.h>
#include <cuda_runtime.h>
// CUDA 核函数,用于向量加法
__global__ void vectorAdd(const float *A, const float *B, float *C, int numElements) {
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < numElements) {
C[i] = A[i] + B[i];
}
}
int main() {
// 定义向量大小
int numElements = 50000;
size_t size = numElements * sizeof(float);
// 分配主机内存
float *h_A = (float *)malloc(size);
float *h_B = (float *)malloc(size);
float *h_C = (float *)malloc(size);
// 初始化主机数据
for (int i = 0; i < numElements; ++i) {
h_A[i] = rand() / (float)RAND_MAX;
h_B[i] = rand() / (float)RAND_MAX;
}
// 分配设备内存
float *d_A, *d_B, *d_C;
cudaMalloc((void **)&d_A, size);
cudaMalloc((void **)&d_B, size);
cudaMalloc((void **)&d_C, size);
// 将数据从主机复制到设备
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
// 定义线程块和网格大小
int threadsPerBlock = 256;
int blocksPerGrid = (numElements + threadsPerBlock - 1) / threadsPerBlock;
// 启动 CUDA 核函数
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, numElements);
// 将结果从设备复制回主机
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
// 验证结果
for (int i = 0; i < numElements; ++i) {
if (fabs(h_A[i] + h_B[i] - h_C[i]) > 1e-5) {
fprintf(stderr, "Result verification failed at element %d!\n", i);
exit(EXIT_FAILURE);
}
}
printf("Test PASSED\n");
// 释放设备内存
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// 释放主机内存
free(h_A);
free(h_B);
free(h_C);
return 0;
}后面的结果如下:
显示是test passed.
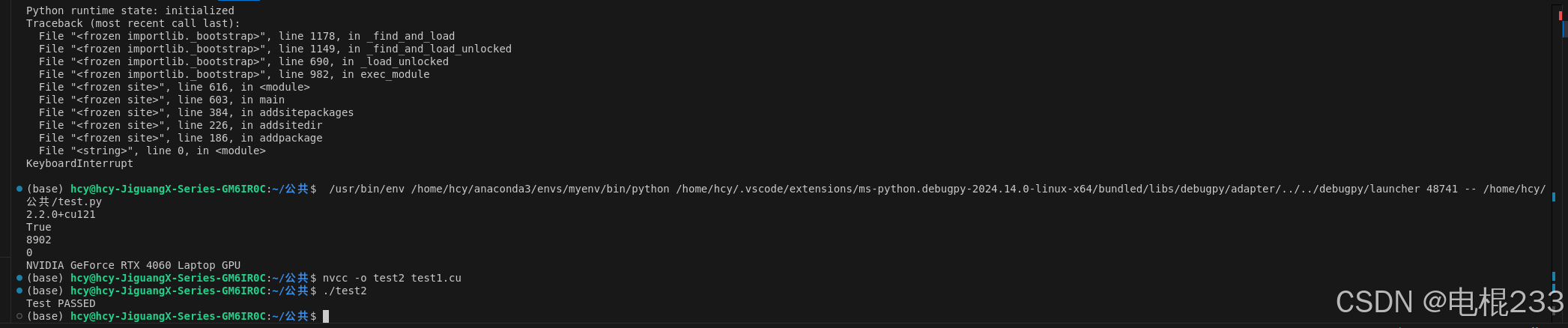
接下来,再用一个指令检查以下
nvidia-smi下面就是麻烦的pytorch安装了,建议详细查看官网的安装命令。因为cuda是向下兼容的,我安装的是cuda12.2,没有在pytorch官网找到相应的pytorch,因此就选择了cuda12.1匹配的pytorch.
Previous PyTorch Versions | PyTorch
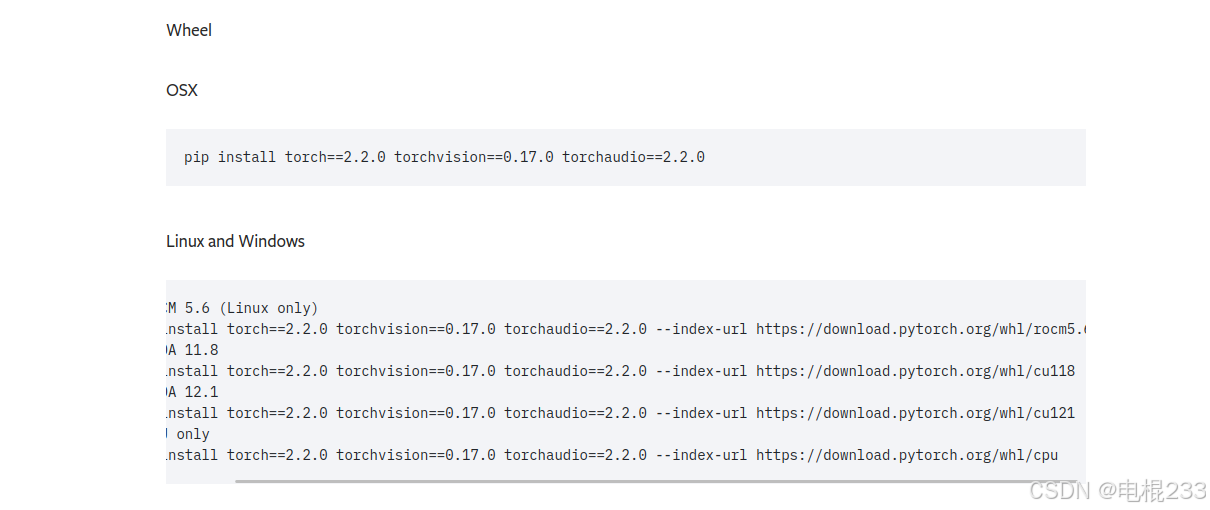
安装命令具体如下:
pip install torch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 --index-url https://download.pytorch.org/whl/cu121这个安装要下一堆东西,最终我是花了三个多小时,为什么这么慢,是因为新安的双系统还没有在linux上面装魔法,但是又懒得装了,就显得很慢。换源的话我也没有试,有些懒。
安装好后,跑一个代码就可以检查了
import torch
# 检查 PyTorch 版本
print(torch.__version__)
# 检查 CUDA 是否可用
print(torch.cuda.is_available())
# 检查 cuDNN 版本
print(torch.backends.cudnn.version())
# 检查当前 GPU 设备
print(torch.cuda.current_device())
# 检查 GPU 名称
print(torch.cuda.get_device_name(0))结果如下:
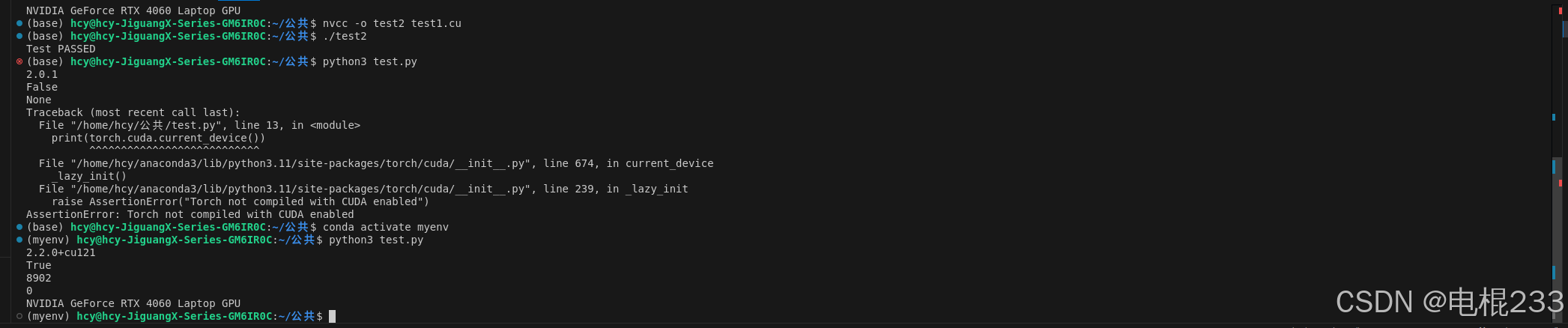
现在已经逐渐习惯用命令行来编译和跑代码了,想来我大一的时候还得去b站看视频配置vscode环境呢。

















 5949
5949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









