







跟学视频
1.原理
1.1LeNet-5
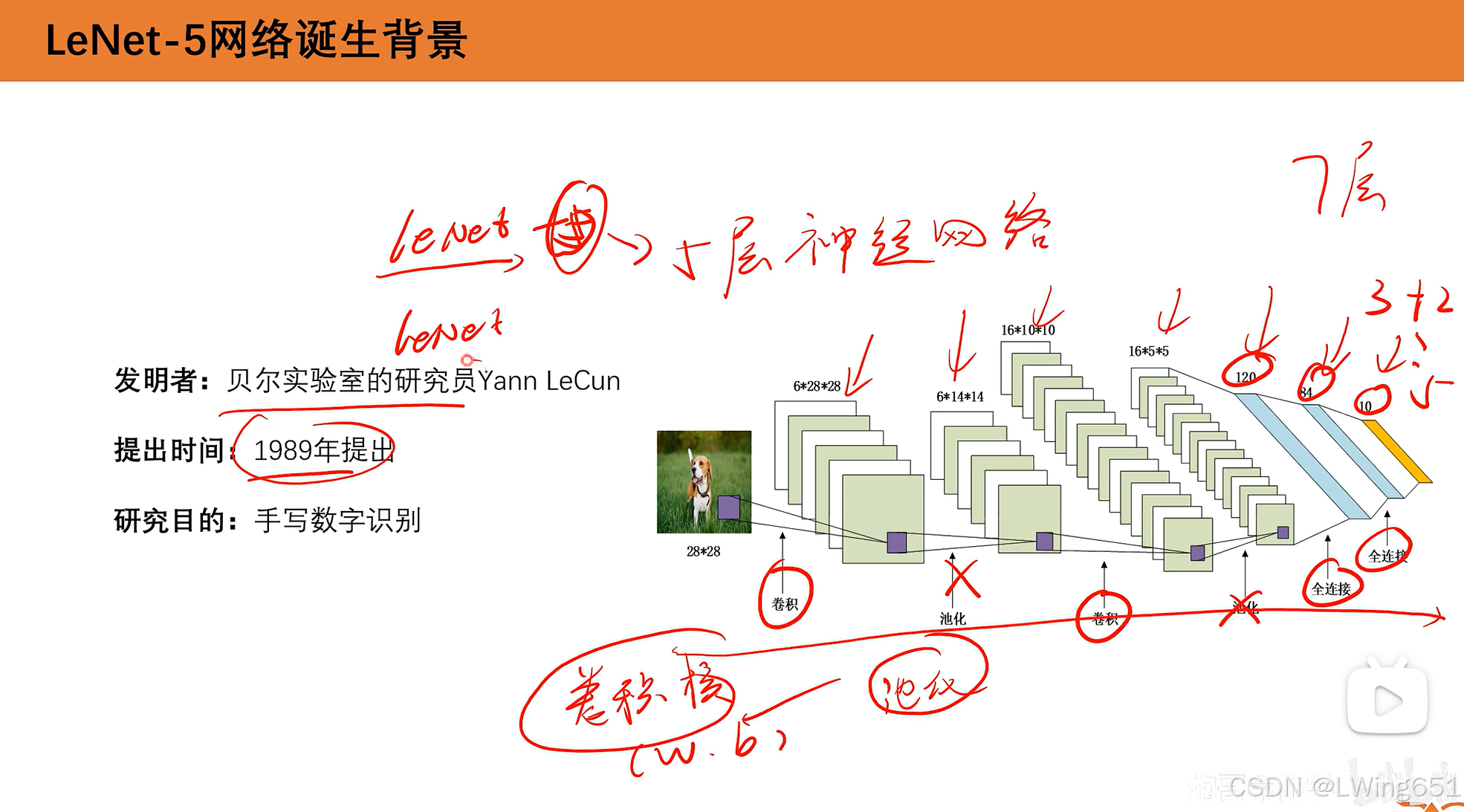
LetNet-5指的是带参数的神经网络层有5层,池化层不算一层。
LetNet-5有两个卷积层和3个全连接层。
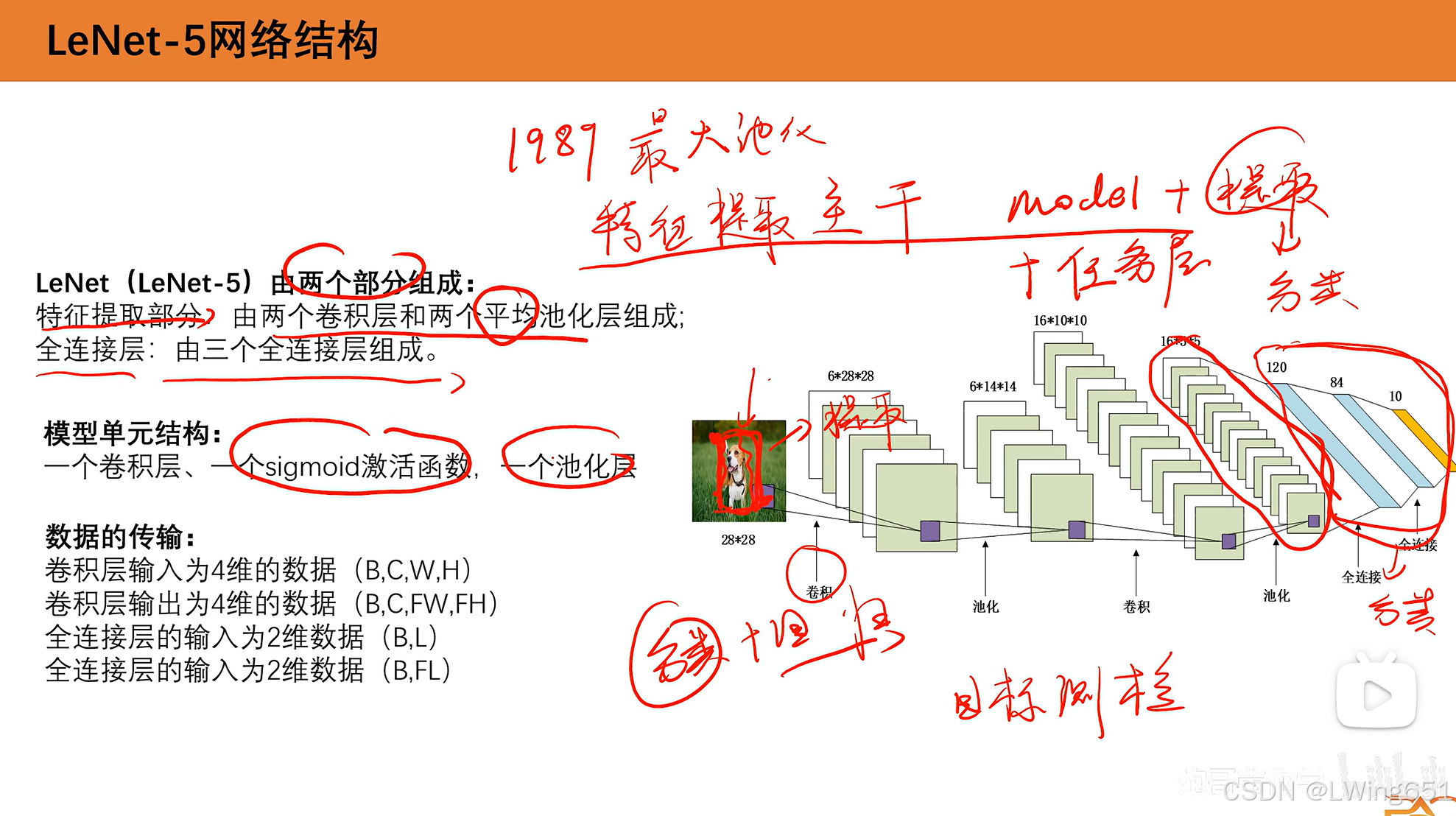
使用的是平均池化,当时还未发明最大池化。
x——>[CNN——>sigmoid——>pool]
若干个这样的过程进行特征提取,最后经过全连接层进行分类。
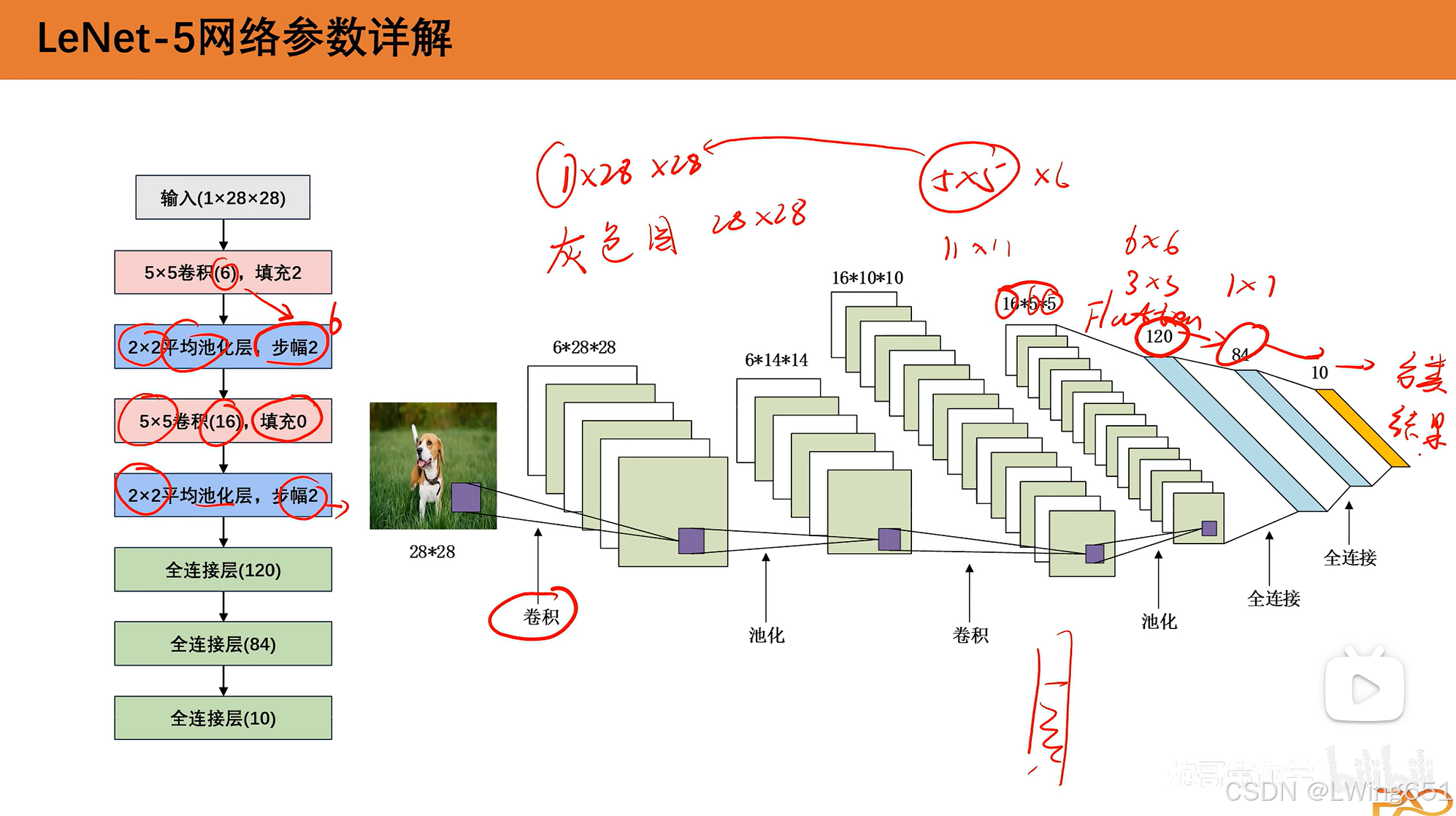
上图输出改为(B,FN,OW,OH)
L=FNXOWXOH
全连接层输出为(B,FL)
当时使用平均池化,但是最大池化用得最多,效果比平均池化好,能提取最有效的特征。
使用以下公式计算,在上篇博客上有具体介绍:


展平操作
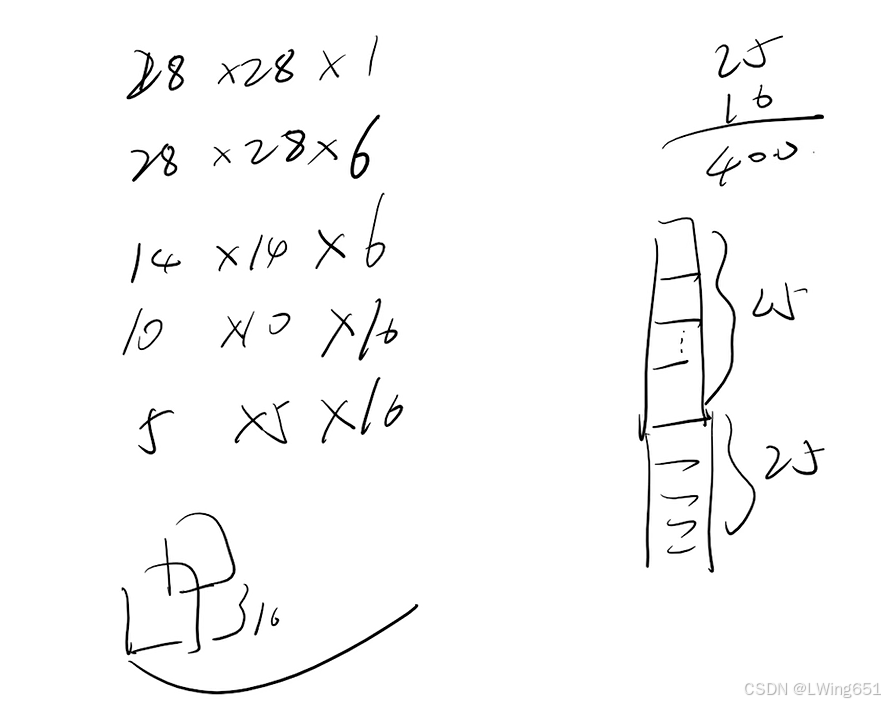

 卷积层和池化层进行特征提取,全连接层得到分类结果。
卷积层和池化层进行特征提取,全连接层得到分类结果。
1.2AlexNet
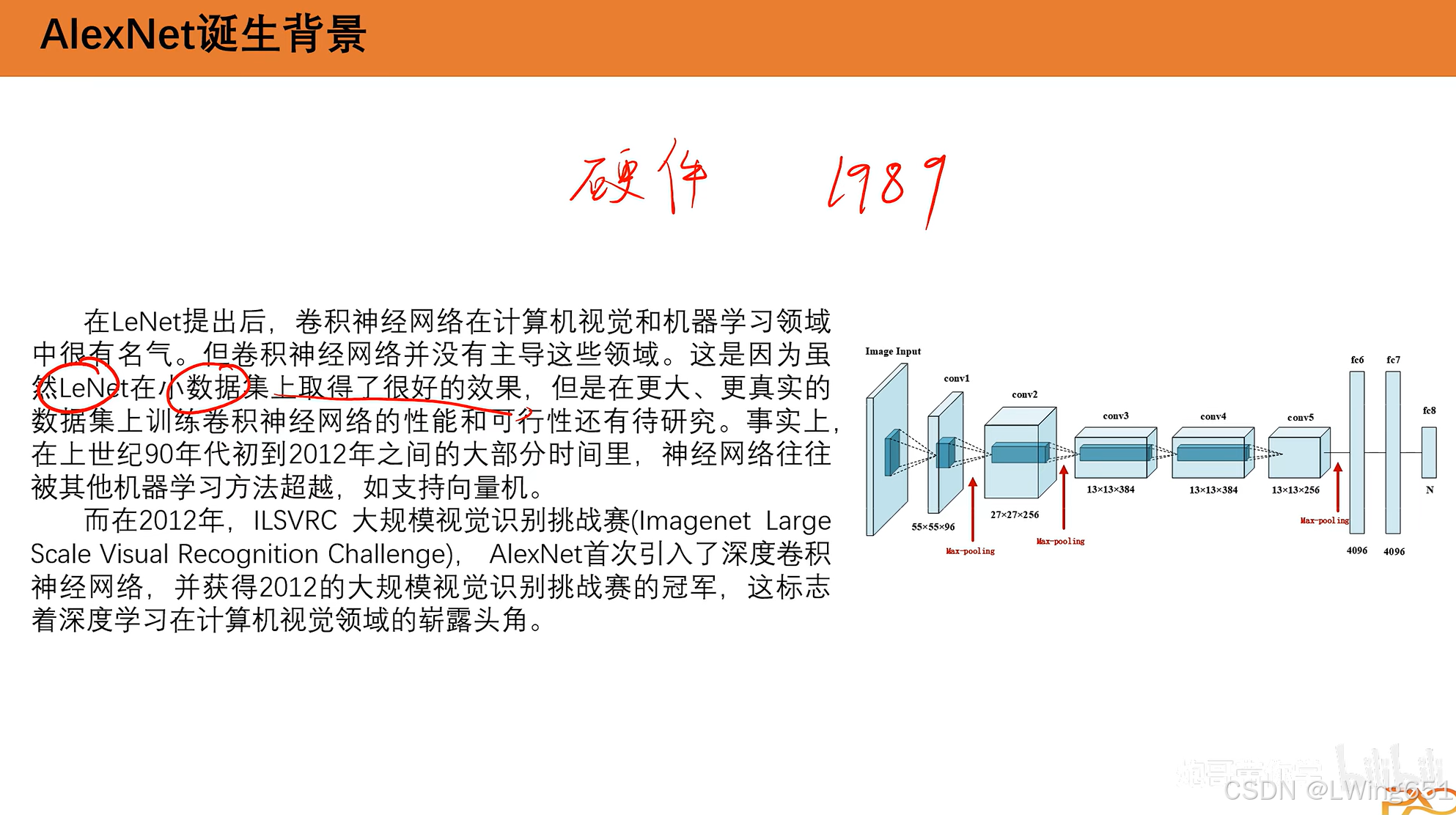 LeNet-5在小数据集上效果好,在大数据集上受到硬件限制。
LeNet-5在小数据集上效果好,在大数据集上受到硬件限制。
现有的深度学习在大规模数据集上的确效果很好,而且可移植性也比较好,泛化性也比较强。
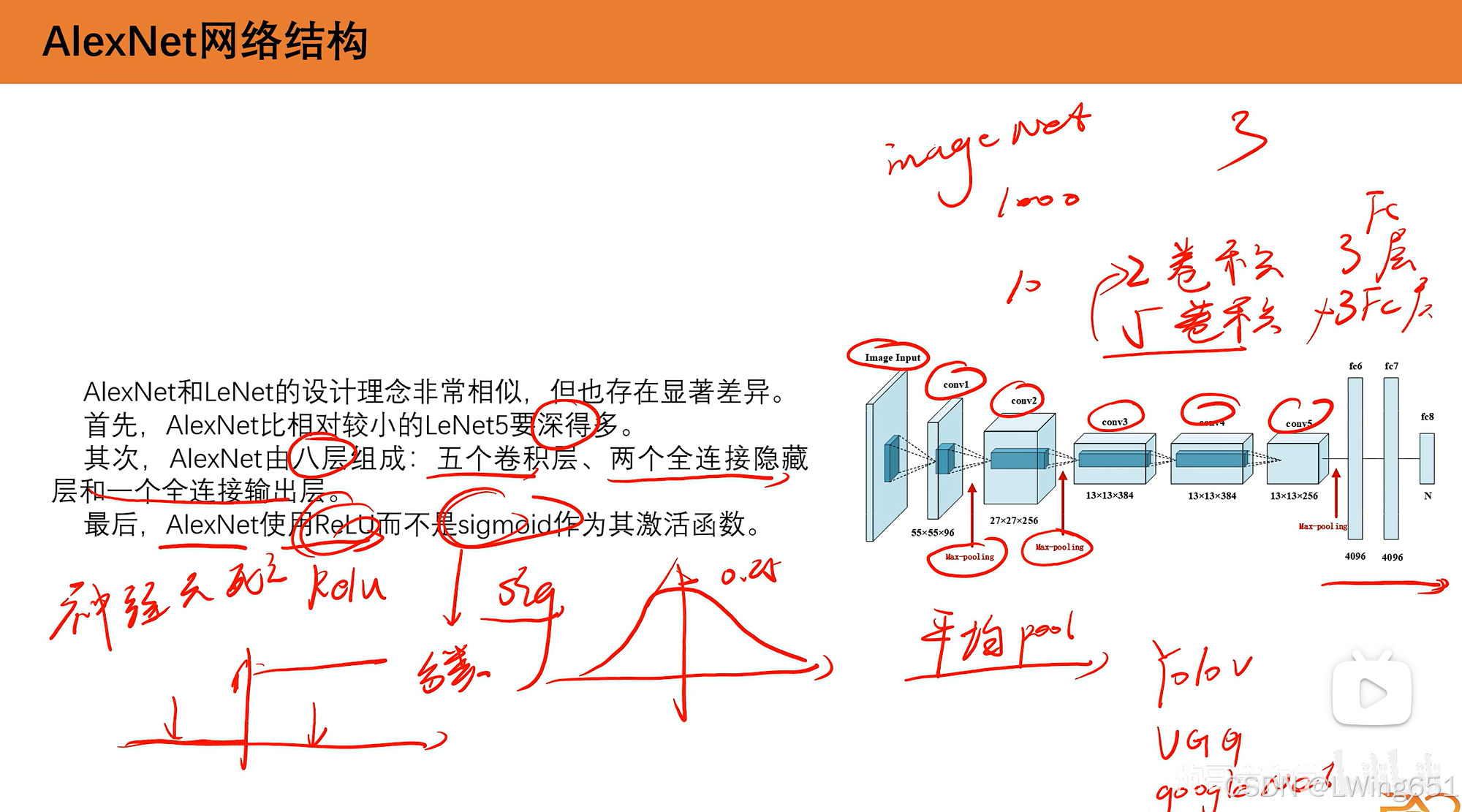
AlexNet和LeNet设计理念非常相似。
AlexNet有5层卷积层,3层全连接层,使用ReLU激活函数,会快很多。
sigmoid激活函数适合用在分类。
使用以下公式计算,在上篇博客上有具体介绍:
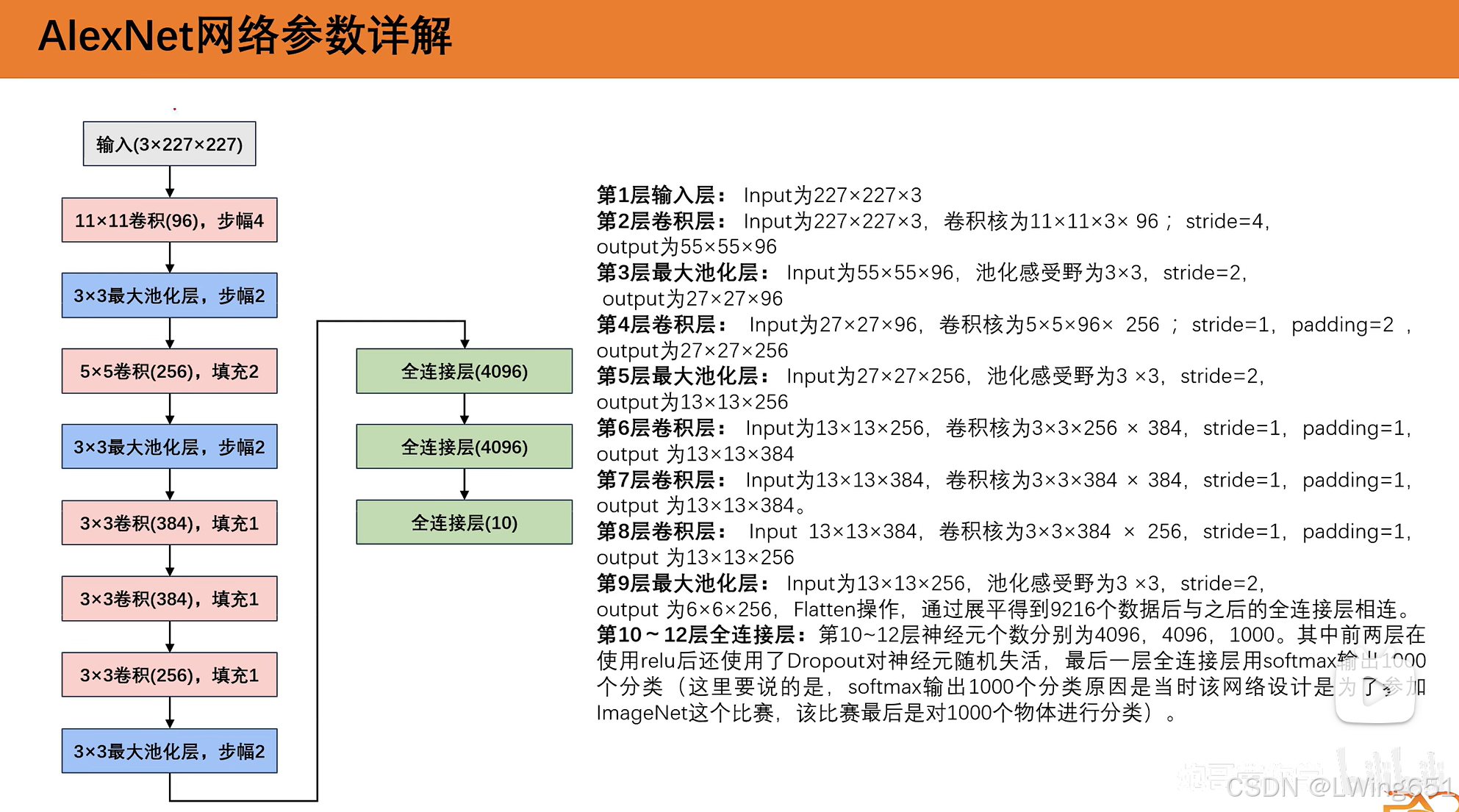 池化层使我们特征图分辨率变低,通道数不变;卷积层希望我们通道数变大。
池化层使我们特征图分辨率变低,通道数不变;卷积层希望我们通道数变大。
展平(Flatten)操作,然后接全连接层: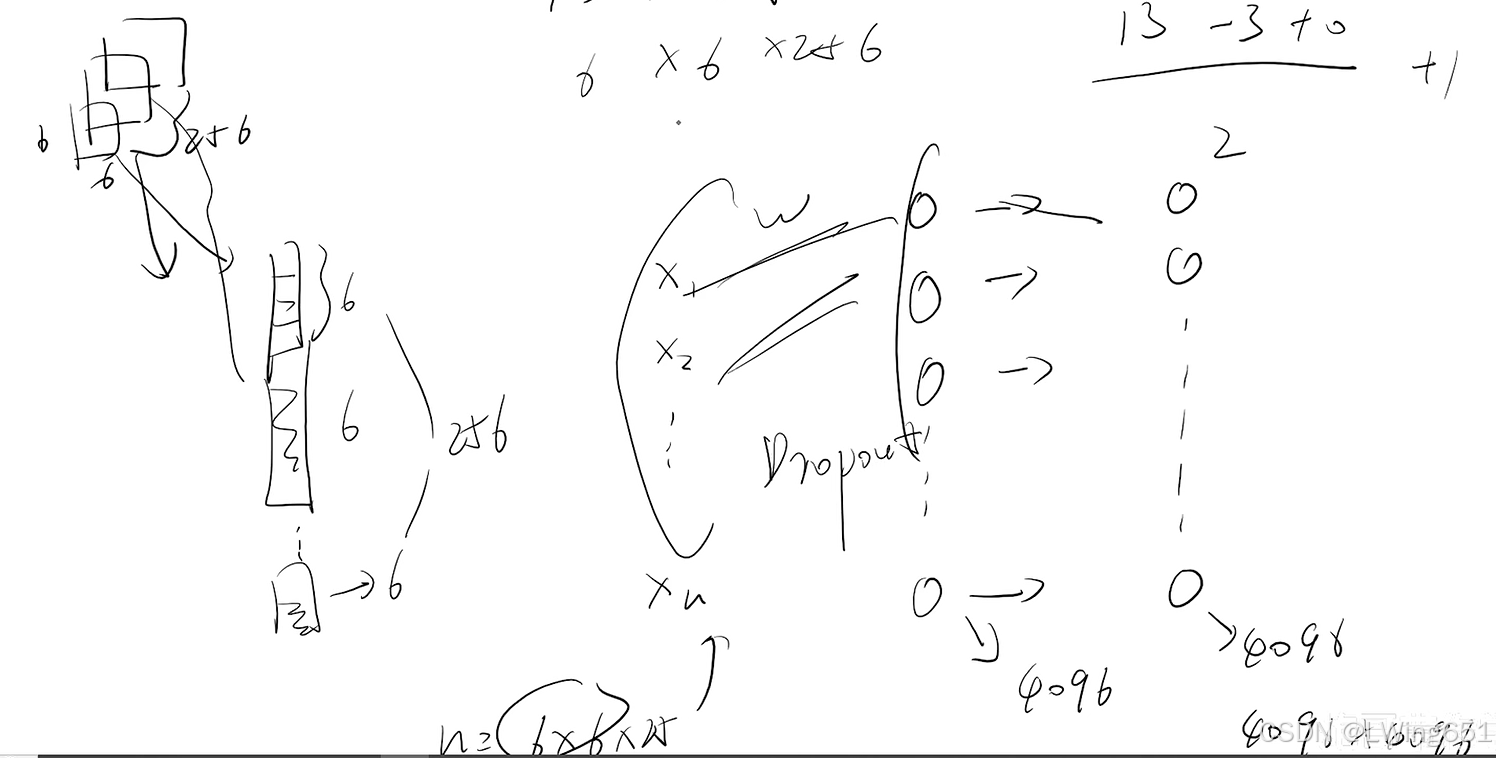
过拟合(Overfitting) 是机器学习中常见的一种现象,指的是模型在训练数据上表现得非常好,但在新的、未见过的测试数据上表现较差的情况。简而言之,过拟合是指模型过于复杂,以至于它不仅学习到了数据中的真实规律,也学习到了训练数据中的噪声和细节,导致模型的泛化能力下降。
Dropout操作防止神经网络过拟合。
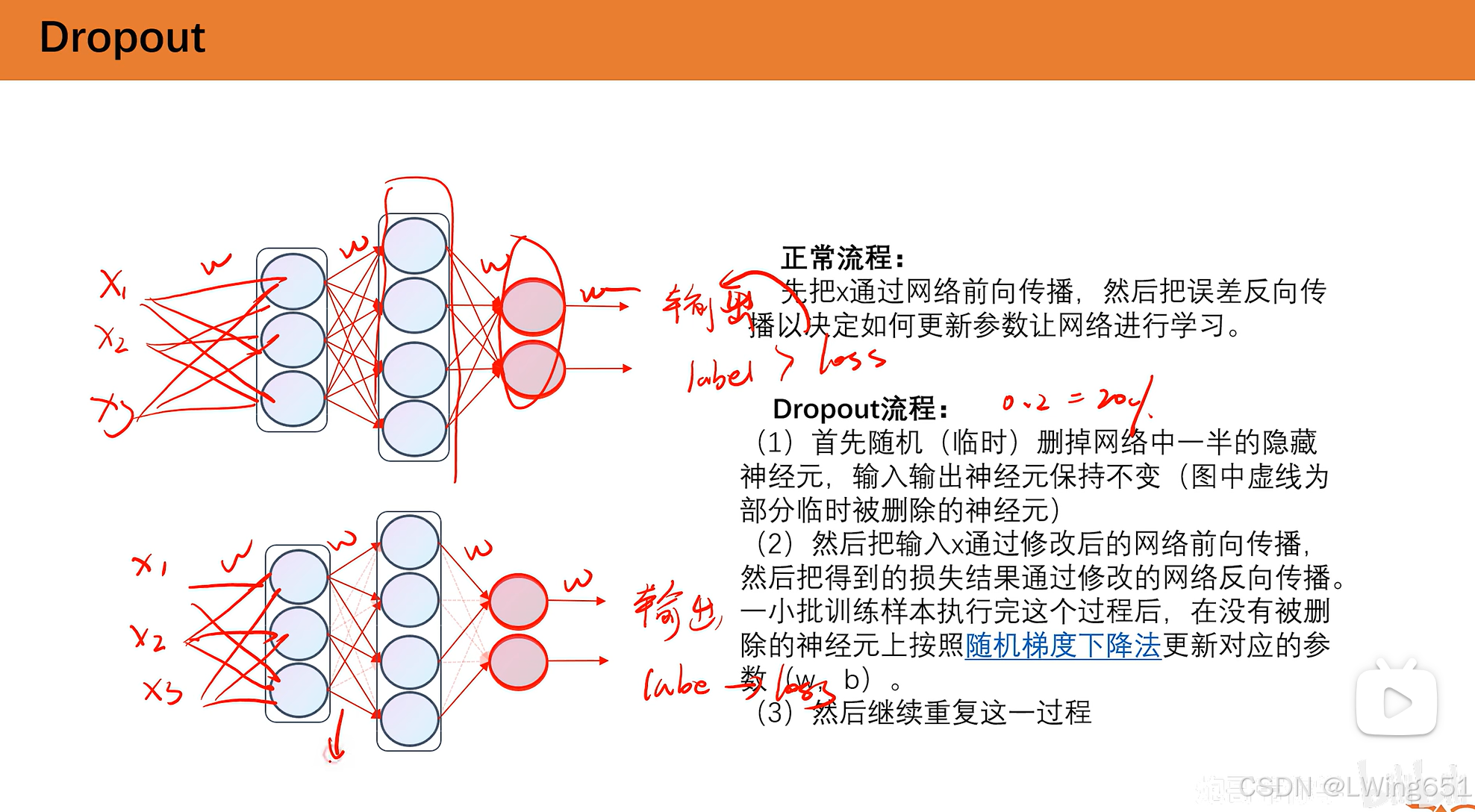
Dropout操作可以设置一个比例,是这个比例的神经元失活。
加速训练
防止过拟合
Dropout是一种常用的正则化技术,广泛应用于训练深度神经网络,目的是防止过拟合。它通过在训练过程中随机地“丢弃”神经网络中的部分神经元,使得模型不依赖于某些特定的神经元,从而提高模型的泛化能力。
图像增强
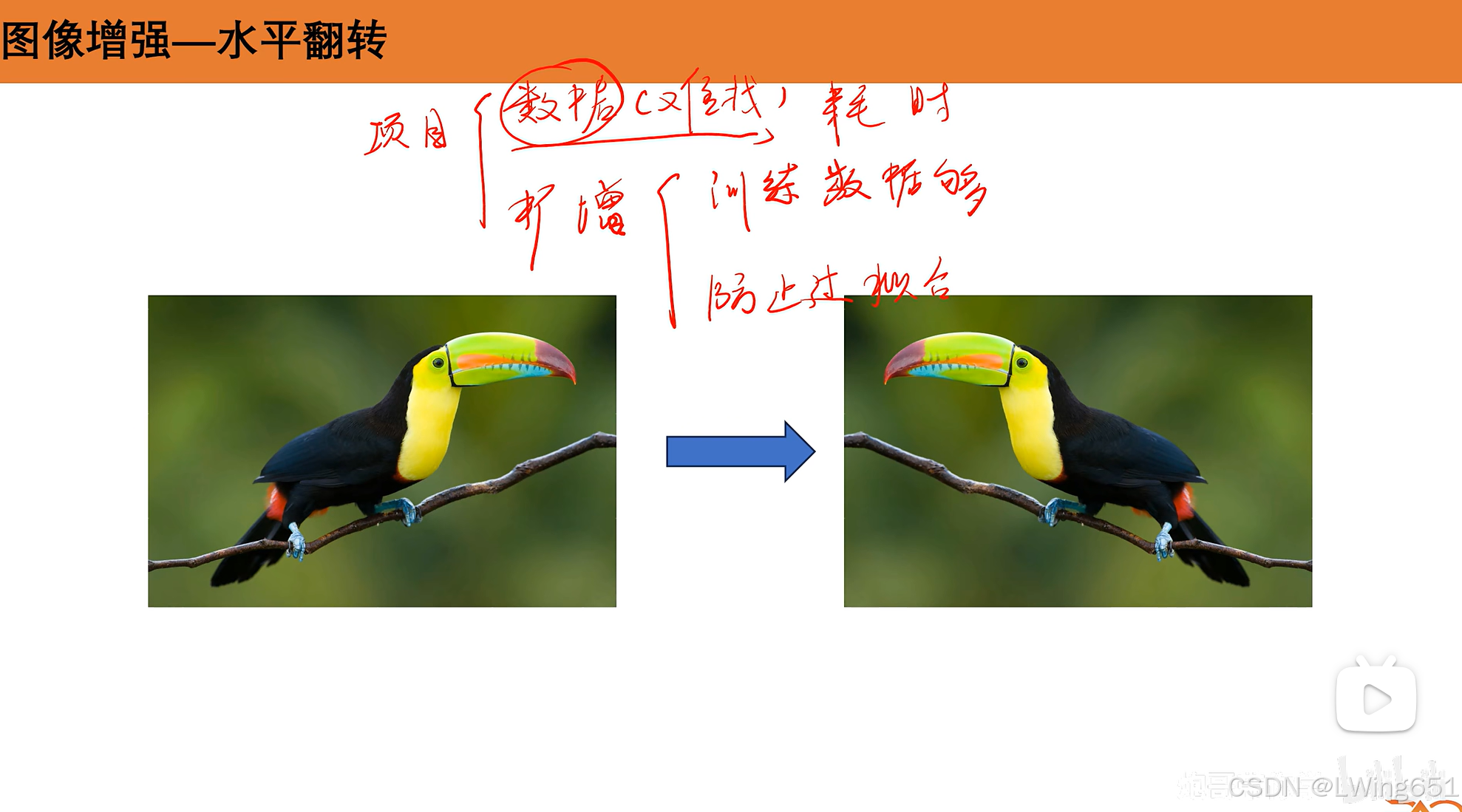
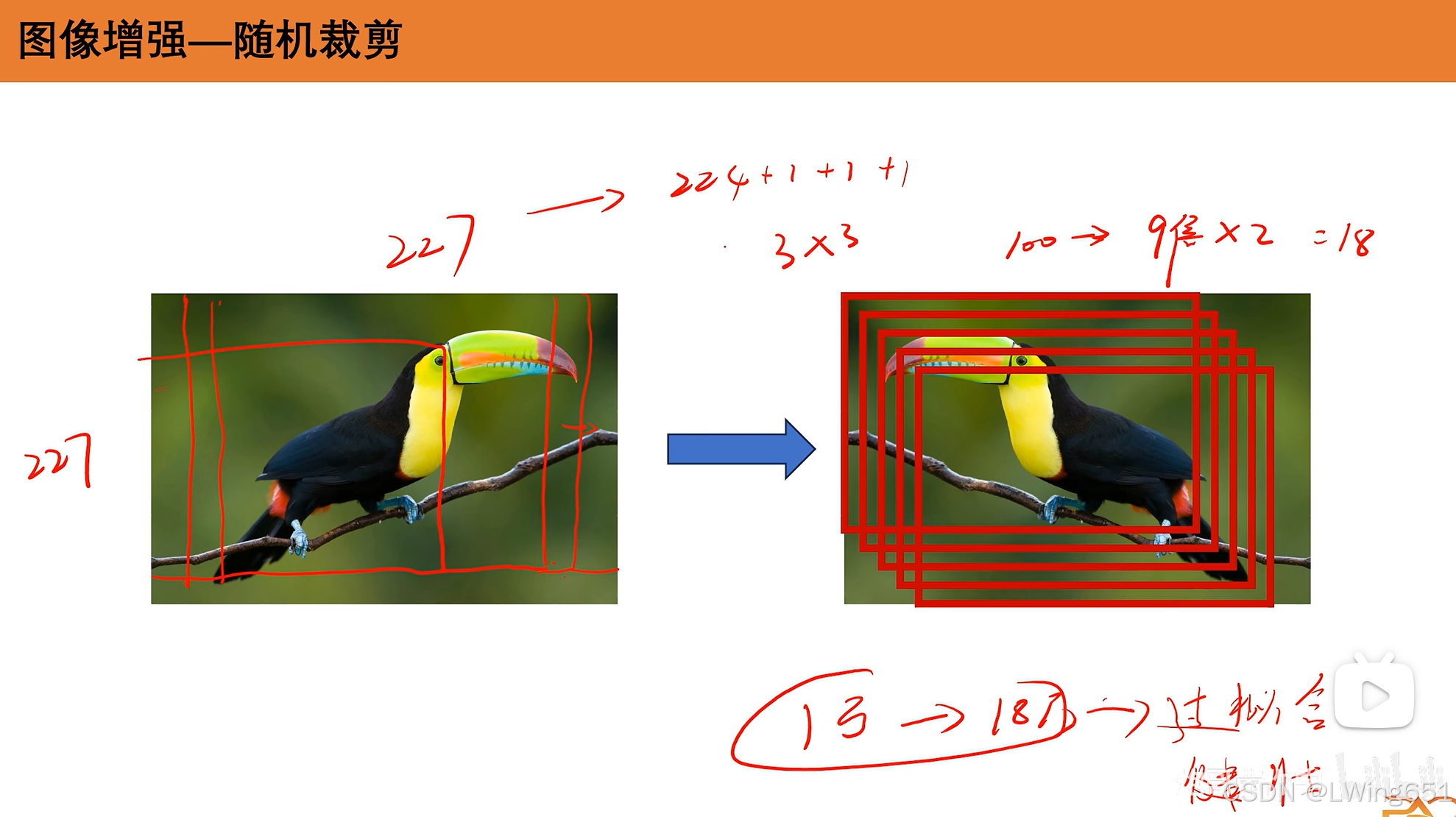
PCA(主成分分析,Principal Component Analysis)是一种常用的降维技术,主要用于数据预处理、特征提取、数据可视化等领域。PCA的目的是将数据从高维空间映射到低维空间,同时保留尽可能多的原始数据的方差和信息,减少数据的复杂度。

LRN正则化
LRN(Local Response Normalization,局部响应归一化) 是一种正则化技术,最早由 AlexNet 中引入,用于增强神经网络在训练过程中的泛化能力,尤其是在卷积神经网络(CNN)中。LRN的目的是通过归一化神经元的响应来增加网络对特定输入的敏感度,帮助网络更好地学习到有效的特征。
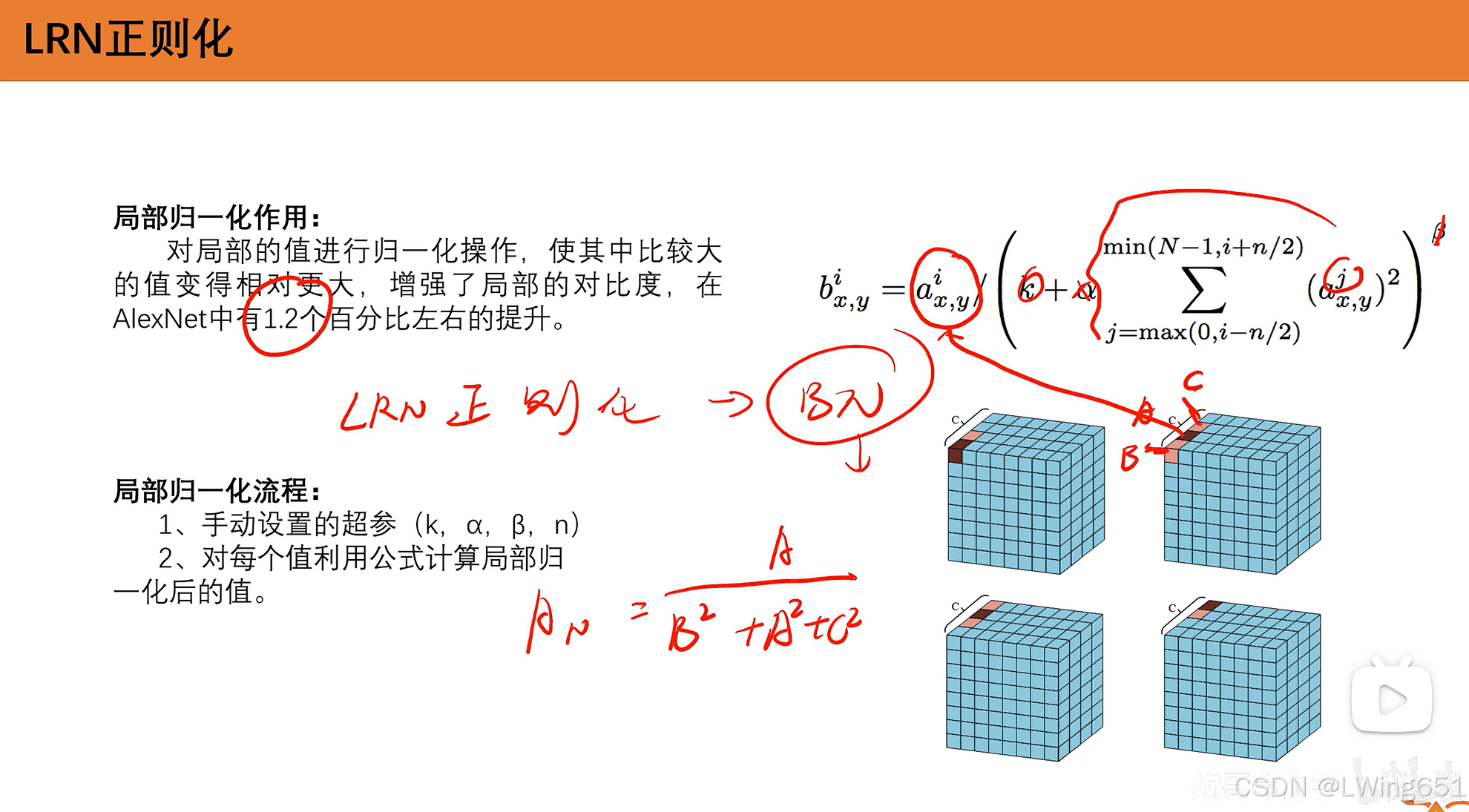

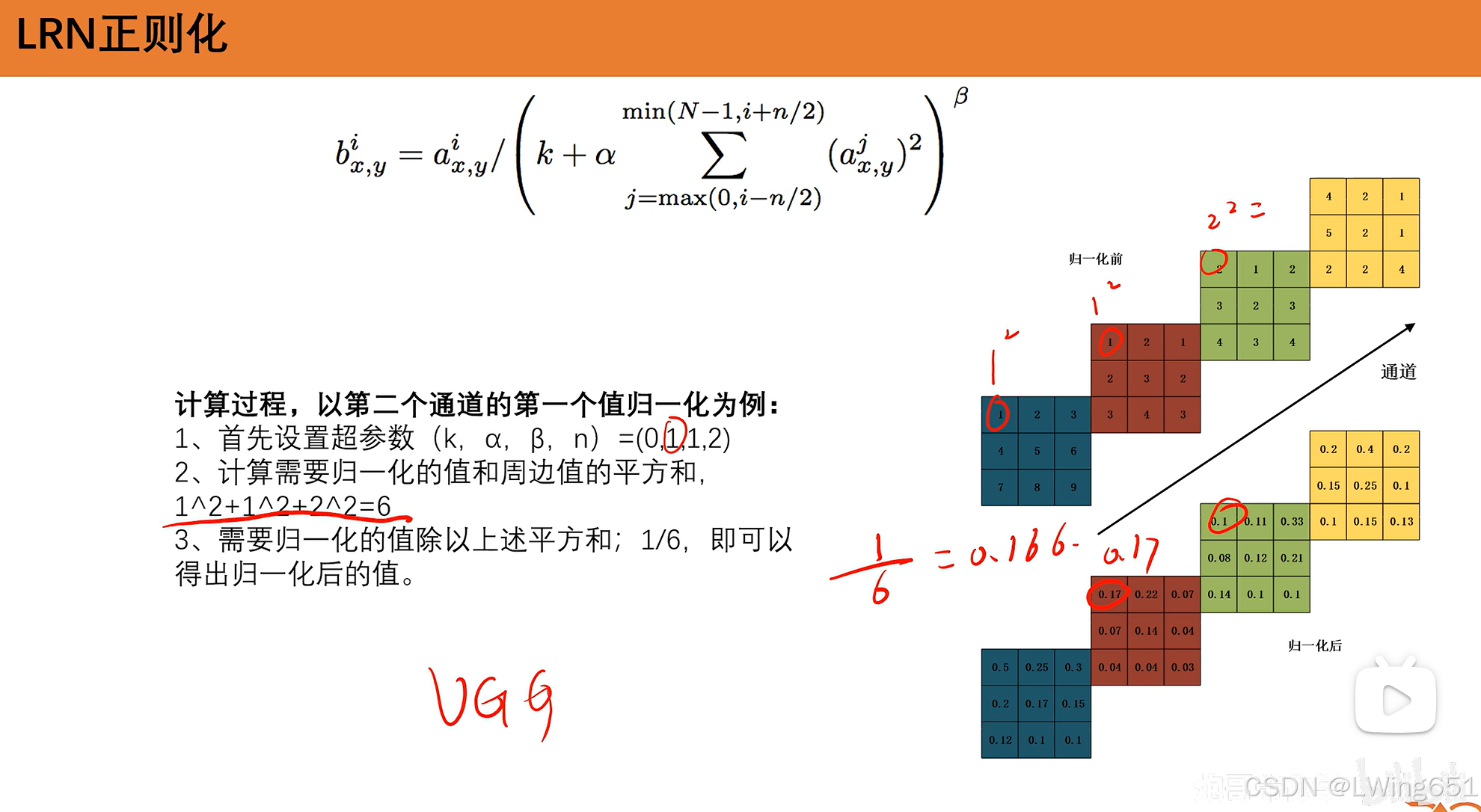
在VGG使用此方法发现没有很大提升,故不再使用。
总结

重叠池化增加了特征的丰富性。
2.实战
2.1LeNet实战
新建LeNet目录
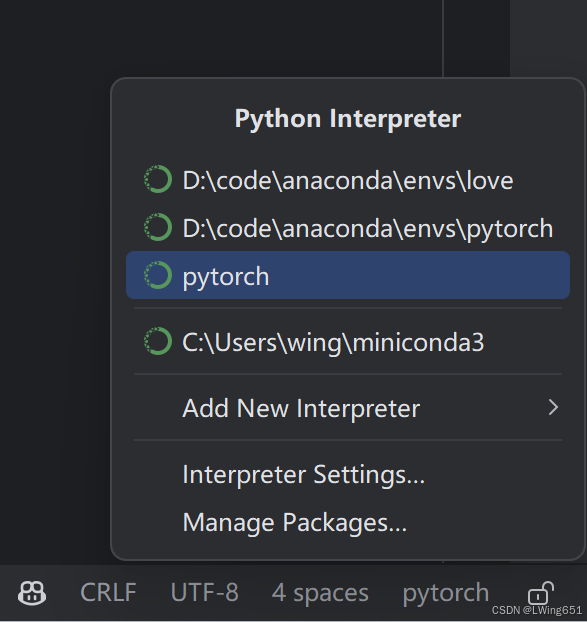
导入pytorch环境,具体环境配置可以看炮哥视频。
新建model.py文件 ,main.py文件没有用可以直接删除。

model.py
import torch
from torch import nn # nn 提供了神经网络层、损失函数、优化器、激活函数等常用操作
from torchsummary import summary # torchsummary是一个用于查看模型参数量的库
class LeNet(nn.Module): # 通过继承 nn.Module 类,用户可以创建自己的神经网络模型。
def __init__(self): # 初始化(网络层、激活函数),网络前向传播
super(LeNet, self).__init__() # 模板,对应
self.c1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2) # 步幅为1,默认,可以不写
self.sig = nn.Sigmoid() # 激活函数
self.s2 = nn.AvgPool2d(kernel_size=2, stride=2) # 池化层
self.c3 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)
self.s4 = nn.AvgPool2d(kernel_size=2,stride=2)
self.flatten = nn.Flatten()
self.f5 = nn.Linear(400,120)
self.f6 = nn.Linear(120,84)
self.f7 = nn.Linear(84,10)
def forward(self, x):
x = self.sig(self.c1(x))
x = self.s2(x)
x = self.sig(self.c3(x))
x = self.s4(x)
x = self.flatten(x)
x = self.f5(x)
x = self.f6(x)
x = self.f7(x)
return x
# 判断当前是否为主程序执行,只有当该脚本被直接运行时,才会执行下面的代码
if __name__ == "__main__" :
# 判断是否有可用的GPU,如果有则使用GPU(cuda),否则使用CPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = LeNet().to(device) # 实例化LeNet模型,并将其移动到指定的设备(GPU或CPU)
print(summary(model, (1, 28, 28))) # 使用summary函数打印模型的摘要信息,输入的张量大小为 (1, 28, 28),即单通道28x28的图像plot.py
from torchvision.datasets import FashionMNIST # torchvision.datasets提供了多种常用的数据集接口,特别是用于图像处理和计算机视觉任务的数据集。
from torchvision import transforms # torchvision.transforms提供了一般的图像转换操作类。
import torch.utils.data as Data # torch.utils.data模块提供了用于加载和处理数据的工具。
import numpy as np
import matplotlib.pyplot as plt # matplotlib.pyplot提供了类似MATLAB的绘图API。
# 使用 FashionMNIST 数据集类加载训练数据集,并进行图像预处理和转换
train_data = FashionMNIST(root='./data', # 指定数据集下载或保存的路径,这里为当前目录下的 './data'
train=True, # 加载训练集。如果设置为 False,则加载测试集
transform=transforms.Compose([ # 进行数据预处理和转换
transforms.Resize(size=224), # 将图像的大小调整为 224x224 像素
transforms.ToTensor()]), # 将图像转换为 PyTorch 张量
download=True) # 如果指定的目录下没有数据集,下载数据集
train_loader = Data.DataLoader(dataset=train_data, # 加载的数据集
batch_size=64, # 指定每个小批次包含的样本数量
shuffle=True, # 是否打乱样本的顺序
num_workers=0)
# 获取一个Batch的数据
for step, (b_x, b_y) in enumerate(train_loader): # 每次加载一个小批次的数据
if step > 0:
break
batch_x = b_x.squeeze().numpy() # 将四维张量移除第一维,并转换为 numpy 数组
batch_y = b_y.numpy() # 将张量转换为 numpy 数组
class_label = train_data.classes # 获取数据集的类别标签
# print(class_label)
# 可视化一个Batch的图像
plt.figure(figsize=(12, 5)) # 创建一个图像窗口
for ii in np.arange(len(batch_y)): # 遍历每个样本
plt.subplot(4, 16, ii + 1) # 在图像窗口中创建一个子图
plt.imshow(batch_x[ii, :, :], cmap=plt.cm.gray) # 显示图像
plt.title(class_label[batch_y[ii]], size=10) # 设置子图标题
plt.axis('off') # 关闭坐标轴
plt.subplots_adjust(wspace=0.05) # 设置子图之间的水平间距
plt.show() # 显示图像
这段代码主要完成以下几项任务:
- 从
FashionMNIST数据集加载训练数据,并对每个图像进行预处理(如调整大小、转换为张量)。- 使用
DataLoader将数据按批次加载,每个批次包含 64 张图像。- 可视化加载的第一个批次图像,通过
matplotlib显示图像,并标注每个图像所属的类别。这对于深度学习项目中的数据加载和可视化部分非常有帮助,帮助我们检查和理解数据的格式和预处理效果。
model_train.py
导入必要的库:
- 导入了 PyTorch、Torchvision、Matplotlib 等常用库,用于模型训练、数据处理和结果可视化。
train_val_data_process函数:
- 下载并加载 FashionMNIST 数据集。
- 对数据进行预处理,分割为训练集和验证集。
- 返回训练和验证数据的 DataLoader,用于批量加载数据。
train_model_process函数:
- 设置设备(GPU 或 CPU)。
- 使用 Adam 优化器和交叉熵损失函数。
- 在多个 epoch 上进行模型训练,计算训练和验证集的损失及准确率。
- 保存最优模型(准确率最高时的权重)。
matplot_acc_loss函数:
- 绘制训练过程中的损失(loss)和准确率(accuracy)变化图。
__main__部分:
- 实例化 LeNet 模型。
- 调用数据处理函数获取 DataLoader。
- 训练模型并获取训练过程中的数据。
- 可视化训练和验证的损失与准确率。
import copy
import time
import torch
from torchvision.datasets import FashionMNIST # torchvision.datasets提供了多种常用的数据集接口,特别是用于图像处理和计算机视觉任务的数据集。
from torchvision import transforms # torchvision.transforms提供了一般的图像转换操作类。
import torch.utils.data as Data # torch.utils.data模块提供了用于加载和处理数据的工具。
import numpy as np
import matplotlib.pyplot as plt # matplotlib.pyplot提供了类似MATLAB的绘图API。
from model import LeNet # 从model.py中导入LeNet模型
import torch.nn as nn
import pandas as pd
def train_val_data_process():
train_data = FashionMNIST(root='./data', # 指定数据集下载或保存的路径,这里为当前目录下的 './data'
train=True, # 加载训练集。如果设置为 False,则加载测试集
transform=transforms.Compose([ # 进行数据预处理和转换
transforms.Resize(size=28),
transforms.ToTensor()]), # 将图像转换为 PyTorch 张量
download=True) # 如果指定的目录下没有数据集,下载数据集
train_data, val_data = Data.random_split(train_data, [round(0.8*len(train_data)), round(0.2*len(train_data))])
train_dataloader = Data.DataLoader(dataset=train_data,
batch_size=32,
shuffle=True,
num_workers=2)
val_dataloader = Data.DataLoader(dataset=val_data,
batch_size=32,
shuffle=True,
num_workers=2)
return train_dataloader, val_dataloader
# 模型训练
def train_model_process(model, train_dataloader, val_dataloader, num_epochs):
# 设定训练所用到的设备,有GPU则使用GPU,否则使用CPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 使用Adam优化器,学习率为0.001
criterion = nn.CrossEntropyLoss() # 使用交叉熵损失函数(回归一般使用均方误差损失函数,分类一般使用交叉熵损失函数)
# 将模型放入到训练设备中
model = model.to(device)
# 复制当前模型的参数
best_model_wts = copy.deepcopy(model.state_dict())
# 初始化参数
# 最高准确度
best_acc = 0.0
# 训练集损失列表
train_loss_all = []
# 验证集损失列表
val_loss_all = []
# 训练集准确度列表
train_acc_all = []
# 验证集准确度列表
val_acc_all = []
# 当前时间
since = time.time()
for epoch in range(num_epochs):
print("Epoch {}/{}".format(epoch, num_epochs - 1))
print("-"*10)
# 初始化参数
# 训练集损失函数
train_loss = 0.0
# 训练集准确度
train_corrects = 0
# 验证集损失函数
val_loss = 0.0
# 验证集准确度
val_corrects = 0
# 训练集样本数量
train_num = 0
# 验证集样本数量
val_num = 0
#对每一个mini-batch训练和计算
for step, (b_x, b_y) in enumerate(train_dataloader):
# 将特征放到训练设备中
b_x = b_x.to(device)
# 将标签放到训练设备中
b_y = b_y.to(device)
# 设置模型为训练模式
model.train()
# 前向传播过程,输入为一个batch,输出为一个batch中对应的预测
output = model(b_x)
# 查找每一行中最大值对应的行标
pre_lab = torch.argmax(output, dim=1)
# 计算每一个batch的损失函数
loss = criterion(output, b_y)
# 将梯度初始化为0,每一轮都要初始化,防止梯度累积
optimizer.zero_grad()
# 反向传播,计算梯度
loss.backward()
# 根据网络反向传播的梯度信息更新网络的参数,以起到降低loss函数计算值的作用
optimizer.step()
# 对损失函数进行累加
train_loss += loss.item() * b_x.size(0)
# 如果预测正确,则准确值train_corrects加1
train_corrects += torch.sum(pre_lab == b_y.data)
# 当前用于训练的样本数量
train_num += b_x.size(0)
for step, (b_x, b_y) in enumerate(val_dataloader):
# 将特征放到验证设备中
b_x = b_x.to(device)
# 将标签放到验证设备中
b_y = b_y.to(device)
# 设置模型为评估模式
model.eval()
# 前向传播过程,输入为一个batch,输出为一个batch中对应的预测
output = model(b_x)
# 查找每一行中最大值对应的行标
pre_lab = torch.argmax(output, dim=1)
# 计算每一个batch的损失函数
loss = criterion(output, b_y)
# 对损失函数进行累加
val_loss += loss.item() * b_x.size(0)
# 如果预测正确,则准确值train_corrects加1
val_corrects += torch.sum(pre_lab == b_y.data)
# 当前用于验证的样本数量
val_num += b_x.size(0)
# 计算并保存每一次迭代的loss值和准确值
# 计算并保存训练集的loss值
train_loss_all.append(train_loss / train_num)
# 计算并保存训练集的准确率
train_acc_all.append(train_corrects.double().item() / train_num)
# 计算并保存验证集的loss值
val_loss_all.append(val_loss / val_num)
# 计算并保存验证集的准确率
val_acc_all.append(val_corrects.double().item() / val_num)
print("{} train loss:{:.4f} train acc:{:.4f}".format(epoch, train_loss_all[-1], train_acc_all[-1]))
print("{} val loss:{:.4f} val acc:{:.4f}".format(epoch, val_loss_all[-1], val_acc_all[-1]))
# 寻找最高准确度的权重
if val_acc_all[-1] > best_acc:
# 保存当前的最高准确度
best_acc = val_acc_all[-1]
# 保存当前最高准确度对应的模型参数
best_model_wts = copy.deepcopy(model.state_dict())
# 训练耗费时间
time_use = time.time() - since
print("训练和验证耗费时间:{:.0f}m {:.0f}s".format(time_use // 60, time_use % 60))
# 选择最优参数
# 加载最高准确率下的模型参数
model.load_state_dict(best_model_wts)
torch.save(model.load_state_dict(best_model_wts), 'D:/code/pych/pytorch_learning/LeNet/best_model.pth')
train_process = pd.DataFrame(data={"epoch": range(num_epochs),
"train_loss_all": train_loss_all,
"val_loss_all": val_loss_all,
"train_acc_all": train_acc_all,
"val_acc_all": val_acc_all})
return train_process
def matplot_acc_loss(train_process):
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(train_process["epoch"], train_process.train_loss_all, 'ro-', label="train_loss")
plt.plot(train_process["epoch"], train_process.val_loss_all, 'bs-', label="val_loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("loss")
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 2)
plt.plot(train_process["epoch"], train_process.train_acc_all, 'ro-', label="train_acc")
plt.plot(train_process["epoch"], train_process.val_acc_all, 'bs-', label="val_acc")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("acc")
plt.show()
if __name__ == "__main__":
# 实例化LeNet模型
LeNet = LeNet()
train_dataloader, val_dataloader = train_val_data_process()
train_process = train_model_process(LeNet, train_dataloader, val_dataloader, 20)
matplot_acc_loss(train_process)
运行结果
Epoch 0/19
----------
0 train loss:0.9587 train acc:0.6250
0 val loss:0.6695 val acc:0.7359
训练和验证耗费时间:0m 13s
Epoch 1/19
----------
1 train loss:0.5981 train acc:0.7736
1 val loss:0.5562 val acc:0.7827
训练和验证耗费时间:0m 22s
Epoch 2/19
----------
2 train loss:0.5226 train acc:0.8082
2 val loss:0.4927 val acc:0.8230
训练和验证耗费时间:0m 31s
Epoch 3/19
----------
3 train loss:0.4777 train acc:0.8265
3 val loss:0.4582 val acc:0.8347
训练和验证耗费时间:0m 40s
Epoch 4/19
----------
4 train loss:0.4452 train acc:0.8385
4 val loss:0.4375 val acc:0.8395
训练和验证耗费时间:0m 49s
Epoch 5/19
----------
5 train loss:0.4244 train acc:0.8455
5 val loss:0.4171 val acc:0.8518
训练和验证耗费时间:0m 59s
Epoch 6/19
----------
6 train loss:0.4062 train acc:0.8518
6 val loss:0.3985 val acc:0.8556
训练和验证耗费时间:1m 8s
Epoch 7/19
----------
7 train loss:0.3913 train acc:0.8564
7 val loss:0.3985 val acc:0.8546
训练和验证耗费时间:1m 17s
Epoch 8/19
----------
8 train loss:0.3784 train acc:0.8612
8 val loss:0.3931 val acc:0.8569
训练和验证耗费时间:1m 26s
Epoch 9/19
----------
9 train loss:0.3687 train acc:0.8652
9 val loss:0.4153 val acc:0.8497
训练和验证耗费时间:1m 35s
Epoch 10/19
----------
10 train loss:0.3602 train acc:0.8687
10 val loss:0.3735 val acc:0.8645
训练和验证耗费时间:1m 45s
Epoch 11/19
----------
11 train loss:0.3520 train acc:0.8712
11 val loss:0.3538 val acc:0.8736
训练和验证耗费时间:1m 54s
Epoch 12/19
----------
12 train loss:0.3466 train acc:0.8723
12 val loss:0.3571 val acc:0.8729
训练和验证耗费时间:2m 3s
Epoch 13/19
----------
13 train loss:0.3379 train acc:0.8773
13 val loss:0.3419 val acc:0.8752
训练和验证耗费时间:2m 12s
Epoch 14/19
----------
14 train loss:0.3327 train acc:0.8791
14 val loss:0.3648 val acc:0.8695
训练和验证耗费时间:2m 21s
Epoch 15/19
----------
15 train loss:0.3296 train acc:0.8790
15 val loss:0.3286 val acc:0.8809
训练和验证耗费时间:2m 31s
Epoch 16/19
----------
16 train loss:0.3252 train acc:0.8806
16 val loss:0.3345 val acc:0.8782
训练和验证耗费时间:2m 40s
Epoch 17/19
----------
17 train loss:0.3207 train acc:0.8829
17 val loss:0.3437 val acc:0.8751
训练和验证耗费时间:2m 49s
Epoch 18/19
----------
18 train loss:0.3168 train acc:0.8825
18 val loss:0.3414 val acc:0.8734
训练和验证耗费时间:2m 58s
Epoch 19/19
----------
19 train loss:0.3120 train acc:0.8848
19 val loss:0.3399 val acc:0.8781
训练和验证耗费时间:3m 8s
Process finished with exit code 0
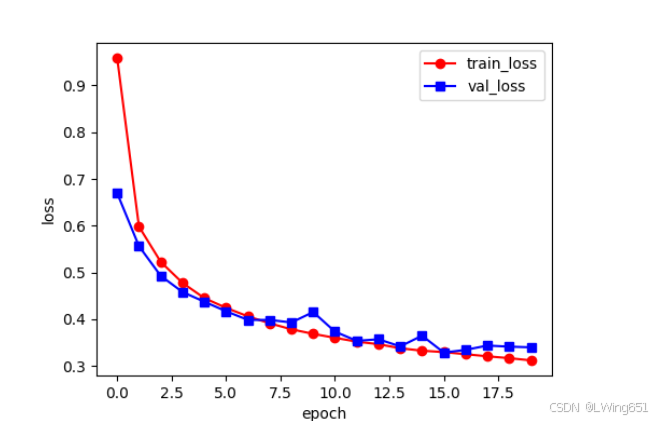
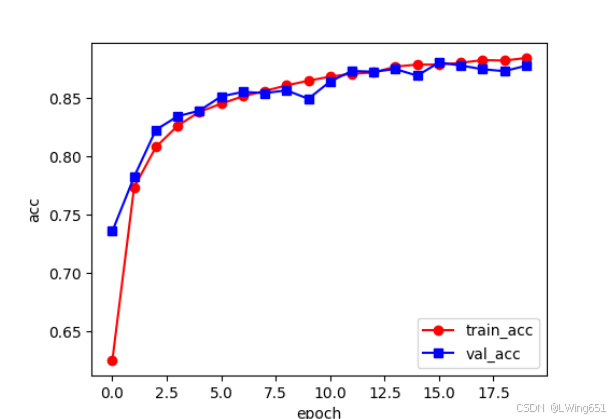
model_test.py
import torch
import torch.utils.data as Data
from torchvision import transforms
from torchvision.datasets import FashionMNIST
from model import LeNet
def test_data_process():
test_data = FashionMNIST(root='./data', # 指定数据集下载或保存的路径,这里为当前目录下的 './data'
train=False, # 加载测试集。如果设置为 False,则加载测试集
transform=transforms.Compose([ # 进行数据预处理和转换
transforms.Resize(size=28),
transforms.ToTensor()]), # 将图像转换为 PyTorch 张量
download=True)
test_dataloader = Data.DataLoader(dataset=test_data,
batch_size=1,
shuffle=True,
num_workers=0)
return test_dataloader
def test_model_process(model, test_dataloader):
# 设定训练所用到的设备,有GPU则使用GPU,否则使用CPU
device = "cuda" if torch.cuda.is_available() else "cpu"
# 将模型放入到测试设备中
model = model.to(device)
# 初始化参数
test_correct = 0.0
test_num = 0
# 只进行前向传播,不进行梯度计算,从而节省内存,加快运行速度
with torch.no_grad():
for test_data_x, test_data_y in test_dataloader:
# 将数据放入到测试设备中
test_data_x = test_data_x.to(device)
# 将标签放入到测试设备中
test_data_y = test_data_y.to(device)
# 将模型设置为评估模式
model.eval()
# 前向传播过程,输入为测试数据集,输出每个样本的预测值
output = model(test_data_x)
# 查找每一行中最大值对应的行标
pre_lab = torch.argmax(output, dim=1)
# 如果预测正确,则精确度test_correct加1
test_correct += torch.sum(pre_lab == test_data_y.data)
# 将所有的测试样本累加
test_num += test_data_x.size(0)
# 计算测试集的准确度
test_acc = test_correct.double().item() / test_num
print("测试的准确率为:", test_acc)
if __name__ == "__main__":
# 加载模型
model = LeNet()
model.load_state_dict(torch.load("best_model.pth"))
# 加载测试数据
test_dataloader = test_data_process()
# 加载模型测试的函数
#test_model_process(model, test_dataloader)
# 设定测试所用到的设备,有GPU则使用GPU,否则使用CPU
device = "cuda" if torch.cuda.is_available() else "cpu"
model = model.to(device)
classes = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
with torch.no_grad():
for b_x, b_y in test_dataloader:
b_x = b_x.to(device)
b_y = b_y.to(device)
model.eval()
output = model(b_x)
pre_lab = torch.argmax(output, dim=1)
result = pre_lab.item()
label = b_y.item()
print("预测值:", classes[result], "-------", "真实值:", classes[label])2.2AlexNet实战
model.py
import torch
from torch import nn
from torchsummary import summary
import torch.nn.functional as F
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.ReLU = nn.ReLU()
self.c1 = nn.Conv2d(in_channels=1, out_channels=96, kernel_size=11, stride=4)
self.s2 = nn.MaxPool2d(kernel_size=3, stride=2)
self.c3 = nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, padding=2)
self.s4 = nn.MaxPool2d(kernel_size=3, stride=2)
self.c5 = nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, padding=1)
self.c6 = nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, padding=1)
self.c7 = nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, padding=1)
self.s8 = nn.MaxPool2d(kernel_size=3, stride=2)
self.flatten = nn.Flatten()
self.f1 = nn.Linear(6*6*256, 4096)
self.f2 = nn.Linear(4096, 4096)
self.f3 = nn.Linear(4096, 10)
def forward(self, x):
x = self.ReLU(self.c1(x))
x = self.s2(x)
x = self.ReLU(self.c3(x))
x = self.s4(x)
x = self.ReLU(self.c5(x))
x = self.ReLU(self.c6(x))
x = self.ReLU(self.c7(x))
x = self.s8(x)
x = self.flatten(x)
x = self.ReLU(self.f1(x))
x = F.dropout(x, p=0.5)
x = self.ReLU(self.f2(x))
x = F.dropout(x, p=0.5)
x = self.f3(x)
return x
if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = AlexNet().to(device)
print(summary(model, (1, 227, 227)))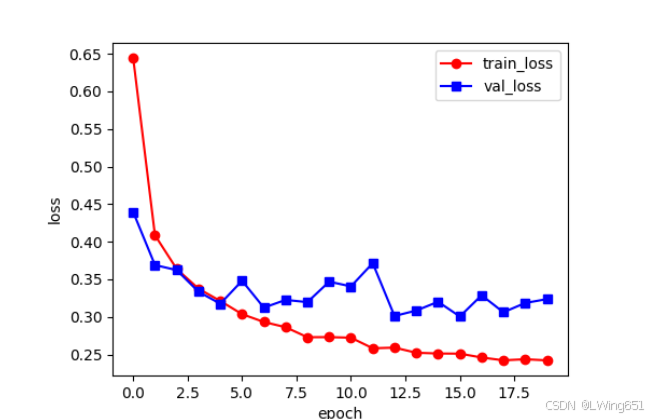
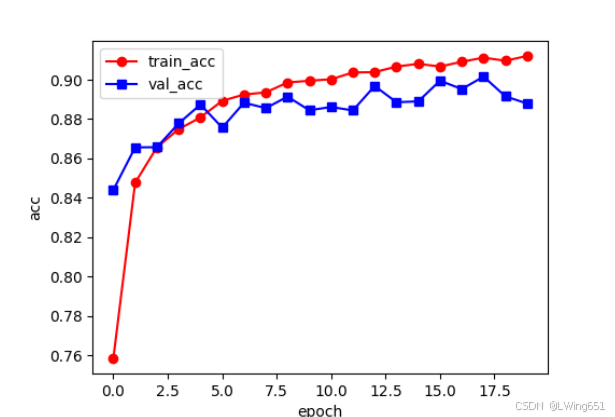
model_train.py
import copy
import time
import torch
from torchvision.datasets import FashionMNIST # torchvision.datasets提供了多种常用的数据集接口,特别是用于图像处理和计算机视觉任务的数据集。
from torchvision import transforms # torchvision.transforms提供了一般的图像转换操作类。
import torch.utils.data as Data # torch.utils.data模块提供了用于加载和处理数据的工具。
import numpy as np
import matplotlib.pyplot as plt # matplotlib.pyplot提供了类似MATLAB的绘图API。
from model import AlexNet # 从model.py中导入AlexNet模型
import torch.nn as nn
import pandas as pd
def train_val_data_process():
train_data = FashionMNIST(root='./data', # 指定数据集下载或保存的路径,这里为当前目录下的 './data'
train=True, # 加载训练集。如果设置为 False,则加载测试集
transform=transforms.Compose([ # 进行数据预处理和转换
transforms.Resize(size=227),
transforms.ToTensor()]), # 将图像转换为 PyTorch 张量
download=True) # 如果指定的目录下没有数据集,下载数据集
train_data, val_data = Data.random_split(train_data, [round(0.8*len(train_data)), round(0.2*len(train_data))])
train_dataloader = Data.DataLoader(dataset=train_data,
batch_size=32,
shuffle=True,
num_workers=2)
val_dataloader = Data.DataLoader(dataset=val_data,
batch_size=32,
shuffle=True,
num_workers=2)
return train_dataloader, val_dataloader
# 模型训练
def train_model_process(model, train_dataloader, val_dataloader, num_epochs):
# 设定训练所用到的设备,有GPU则使用GPU,否则使用CPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 使用Adam优化器,学习率为0.001
criterion = nn.CrossEntropyLoss() # 使用交叉熵损失函数(回归一般使用均方误差损失函数,分类一般使用交叉熵损失函数)
# 将模型放入到训练设备中
model = model.to(device)
# 复制当前模型的参数
best_model_wts = copy.deepcopy(model.state_dict())
# 初始化参数
# 最高准确度
best_acc = 0.0
# 训练集损失列表
train_loss_all = []
# 验证集损失列表
val_loss_all = []
# 训练集准确度列表
train_acc_all = []
# 验证集准确度列表
val_acc_all = []
# 当前时间
since = time.time()
for epoch in range(num_epochs):
print("Epoch {}/{}".format(epoch, num_epochs - 1))
print("-"*10)
# 初始化参数
# 训练集损失函数
train_loss = 0.0
# 训练集准确度
train_corrects = 0
# 验证集损失函数
val_loss = 0.0
# 验证集准确度
val_corrects = 0
# 训练集样本数量
train_num = 0
# 验证集样本数量
val_num = 0
#对每一个mini-batch训练和计算
for step, (b_x, b_y) in enumerate(train_dataloader):
# 将特征放到训练设备中
b_x = b_x.to(device)
# 将标签放到训练设备中
b_y = b_y.to(device)
# 设置模型为训练模式
model.train()
# 前向传播过程,输入为一个batch,输出为一个batch中对应的预测
output = model(b_x)
# 查找每一行中最大值对应的行标
pre_lab = torch.argmax(output, dim=1)
# 计算每一个batch的损失函数
loss = criterion(output, b_y)
# 将梯度初始化为0,每一轮都要初始化,防止梯度累积
optimizer.zero_grad()
# 反向传播,计算梯度
loss.backward()
# 根据网络反向传播的梯度信息更新网络的参数,以起到降低loss函数计算值的作用
optimizer.step()
# 对损失函数进行累加
train_loss += loss.item() * b_x.size(0)
# 如果预测正确,则准确值train_corrects加1
train_corrects += torch.sum(pre_lab == b_y.data)
# 当前用于训练的样本数量
train_num += b_x.size(0)
for step, (b_x, b_y) in enumerate(val_dataloader):
# 将特征放到验证设备中
b_x = b_x.to(device)
# 将标签放到验证设备中
b_y = b_y.to(device)
# 设置模型为评估模式
model.eval()
# 前向传播过程,输入为一个batch,输出为一个batch中对应的预测
output = model(b_x)
# 查找每一行中最大值对应的行标
pre_lab = torch.argmax(output, dim=1)
# 计算每一个batch的损失函数
loss = criterion(output, b_y)
# 对损失函数进行累加
val_loss += loss.item() * b_x.size(0)
# 如果预测正确,则准确值train_corrects加1
val_corrects += torch.sum(pre_lab == b_y.data)
# 当前用于验证的样本数量
val_num += b_x.size(0)
# 计算并保存每一次迭代的loss值和准确值
# 计算并保存训练集的loss值
train_loss_all.append(train_loss / train_num)
# 计算并保存训练集的准确率
train_acc_all.append(train_corrects.double().item() / train_num)
# 计算并保存验证集的loss值
val_loss_all.append(val_loss / val_num)
# 计算并保存验证集的准确率
val_acc_all.append(val_corrects.double().item() / val_num)
print("{} train loss:{:.4f} train acc:{:.4f}".format(epoch, train_loss_all[-1], train_acc_all[-1]))
print("{} val loss:{:.4f} val acc:{:.4f}".format(epoch, val_loss_all[-1], val_acc_all[-1]))
# 寻找最高准确度的权重
if val_acc_all[-1] > best_acc:
# 保存当前的最高准确度
best_acc = val_acc_all[-1]
# 保存当前最高准确度对应的模型参数
best_model_wts = copy.deepcopy(model.state_dict())
# 训练耗费时间
time_use = time.time() - since
print("训练和验证耗费时间:{:.0f}m {:.0f}s".format(time_use // 60, time_use % 60))
# 选择最优参数
# 加载最高准确率下的模型参数
torch.save(best_model_wts, 'D:/code/pych/pytorch_learning/AlexNet/best_model.pth')
train_process = pd.DataFrame(data={"epoch": range(num_epochs),
"train_loss_all": train_loss_all,
"val_loss_all": val_loss_all,
"train_acc_all": train_acc_all,
"val_acc_all": val_acc_all})
return train_process
def matplot_acc_loss(train_process):
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(train_process["epoch"], train_process.train_loss_all, 'ro-', label="train_loss")
plt.plot(train_process["epoch"], train_process.val_loss_all, 'bs-', label="val_loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("loss")
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 2)
plt.plot(train_process["epoch"], train_process.train_acc_all, 'ro-', label="train_acc")
plt.plot(train_process["epoch"], train_process.val_acc_all, 'bs-', label="val_acc")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("acc")
plt.show()
if __name__ == "__main__":
# 实例化LeNet模型
AlexNet = AlexNet()
train_dataloader, val_dataloader = train_val_data_process()
train_process = train_model_process(AlexNet, train_dataloader, val_dataloader, 20)
matplot_acc_loss(train_process)model_test.py
import torch
import torch.utils.data as Data
from torchvision import transforms
from torchvision.datasets import FashionMNIST
from model import AlexNet
def test_data_process():
test_data = FashionMNIST(root='./data', # 指定数据集下载或保存的路径,这里为当前目录下的 './data'
train=False, # 加载测试集。如果设置为 False,则加载测试集
transform=transforms.Compose([ # 进行数据预处理和转换
transforms.Resize(size=227),
transforms.ToTensor()]), # 将图像转换为 PyTorch 张量
download=True)
test_dataloader = Data.DataLoader(dataset=test_data,
batch_size=1,
shuffle=True,
num_workers=0)
return test_dataloader
def test_model_process(model, test_dataloader):
# 设定训练所用到的设备,有GPU则使用GPU,否则使用CPU
device = "cuda" if torch.cuda.is_available() else "cpu"
# 将模型放入到测试设备中
model = model.to(device)
# 初始化参数
test_correct = 0.0
test_num = 0
# 只进行前向传播,不进行梯度计算,从而节省内存,加快运行速度
with torch.no_grad():
for test_data_x, test_data_y in test_dataloader:
# 将数据放入到测试设备中
test_data_x = test_data_x.to(device)
# 将标签放入到测试设备中
test_data_y = test_data_y.to(device)
# 将模型设置为评估模式
model.eval()
# 前向传播过程,输入为测试数据集,输出每个样本的预测值
output = model(test_data_x)
# 查找每一行中最大值对应的行标
pre_lab = torch.argmax(output, dim=1)
# 如果预测正确,则精确度test_correct加1
test_correct += torch.sum(pre_lab == test_data_y.data)
# 将所有的测试样本累加
test_num += test_data_x.size(0)
# 计算测试集的准确度
test_acc = test_correct.double().item() / test_num
print("测试的准确率为:", test_acc)
if __name__ == "__main__":
# 加载模型
model = AlexNet()
model.load_state_dict(torch.load("best_model.pth"))
# 加载测试数据
test_dataloader = test_data_process()
# 加载模型测试的函数
#test_model_process(model, test_dataloader)
# 设定测试所用到的设备,有GPU则使用GPU,否则使用CPU
device = "cuda" if torch.cuda.is_available() else "cpu"
model = model.to(device)
classes = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
with torch.no_grad():
for b_x, b_y in test_dataloader:
b_x = b_x.to(device)
b_y = b_y.to(device)
model.eval()
output = model(b_x)
pre_lab = torch.argmax(output, dim=1)
result = pre_lab.item()
label = b_y.item()
print("预测值:", classes[result], "-------", "真实值:", classes[label])model_train.py和model_test.py可以移植使用,只需更改部分,model.py需要我们每次去构建。

















 1940
1940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









