




第一部分:下载Ollama中的deepseek R1模型
点击下载:
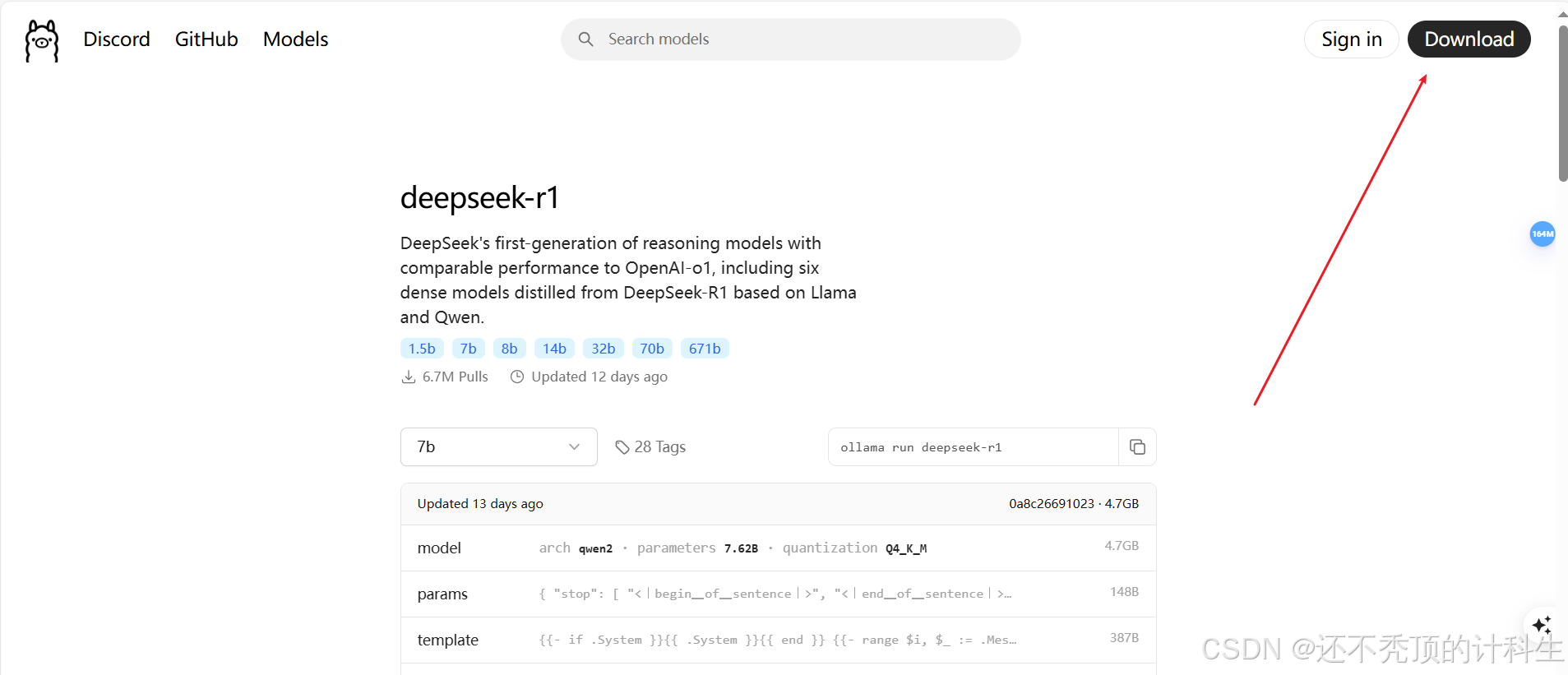
第二部分:安装Ollama
(1)点击安装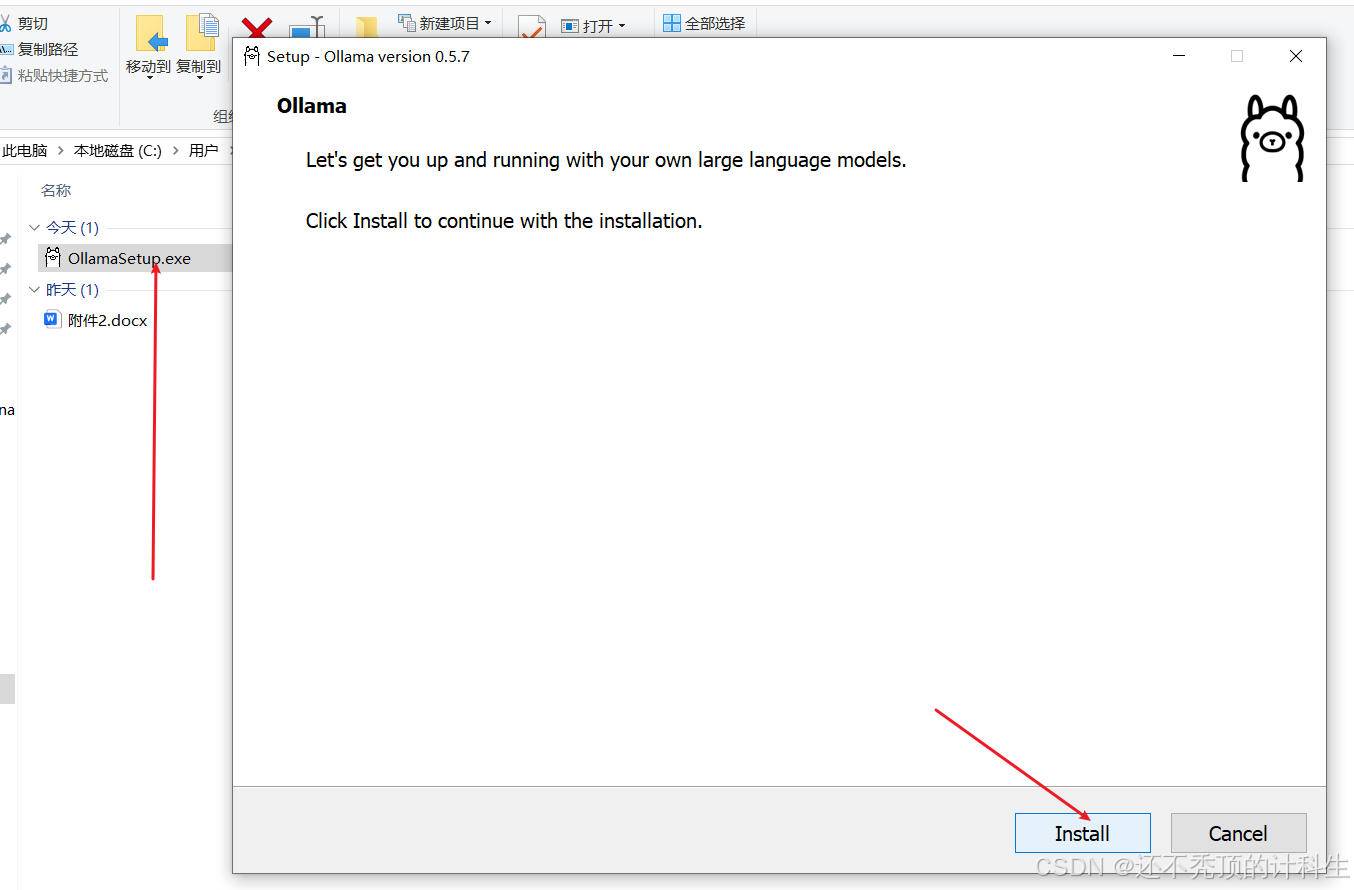
(2)安装之后的效果
(3)安装默认是c盘
C:\Users\wwwju\AppData\Local\Programs\Ollama
第三部分:选择模型
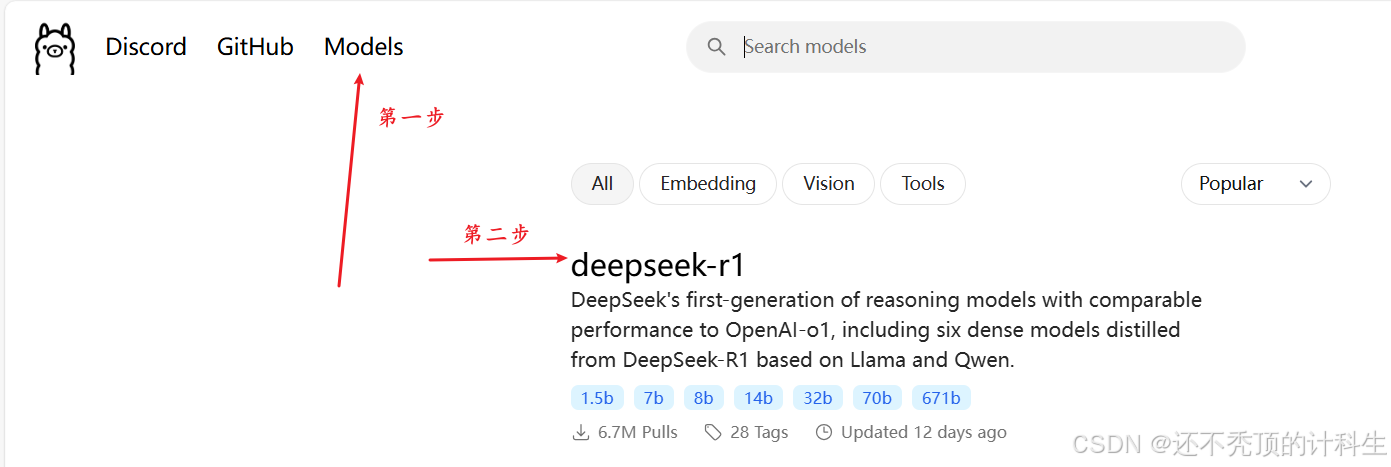
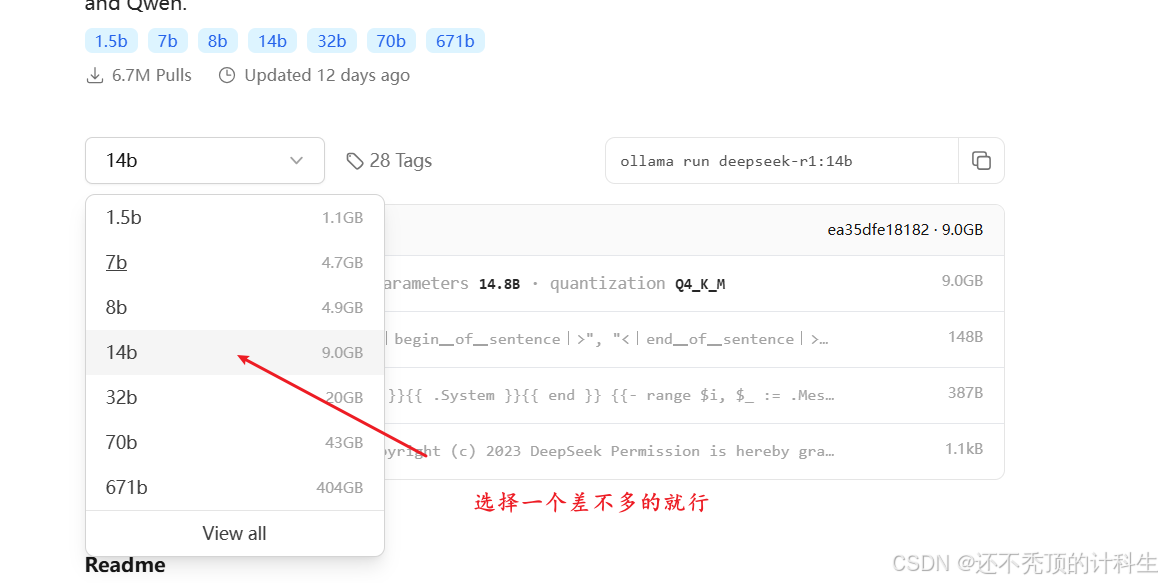
当然可以,以下是表格中的内容:
模型大小 Windows 配置要求 Mac 配置要求 适用场景 1.5B - RAM: 4GB<br>- GPU: 集成显卡(如GTX 1050)或现代CPU<br>- 存储: 5GB - 内存: 8GB(统一内存)<br>- 芯片: M1/M2/M3<br>- 存储: 5GB 简单文本生成/基础代码补全 7B - RAM: 8-10GB<br>- GPU: GTX 1660(4-bit量化)<br>- 存储: 8GB - 内存: 16GB<br>- 芯片: M2 Pro/M3<br>- 存储: 8GB 中等复杂度问答/代码调试 8B - RAM: 12GB<br>- GPU: RTX 3060(8GB VRAM)<br>- 存储: 10GB - 内存: 24GB<br>- 芯片: M2 Max<br>- 存储: 10GB 多轮对话/文档分析 14B - RAM: 24GB<br>- GPU: RTX 3090(24GB VRAM)<br>- 存储: 20GB - 内存: 32GB<br>- 芯片: M3 Max<br>- 存储: 20GB 复杂推理/技术文档生成 32B - RAM: 48GB<br>- GPU: RTX 4090(4-bit量化)<br>- 存储: 40GB - 内存: 64GB<br>- 芯片: M3 Ultra<br>- 存储: 40GB 科研计算/大规模数据处理 70B - RAM: 64GB<br>- GPU: 双RTX 4090(NVLink)<br>- 存储: 80GB - 内存: 128GB(需外接显卡坞)<br>- 存储: 80GB 企业级AI服务/多模态处理 67B - RAM: 256GB+<br>- GPU: 8xH100(通过NVLINK连接)<br>- 存储: 1TB+ 暂不支持 超大规模云端推理
然后复制右侧的这些字母:
ollama run deepseek-r1:14b将这段内容复制到命令行中: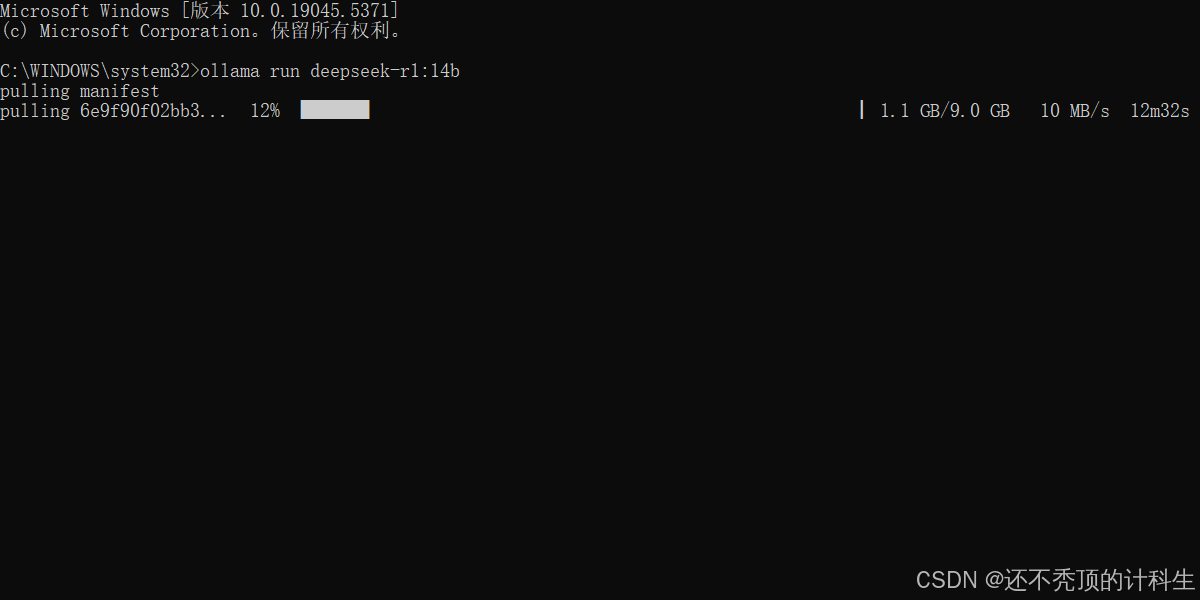
就可以开始下载了。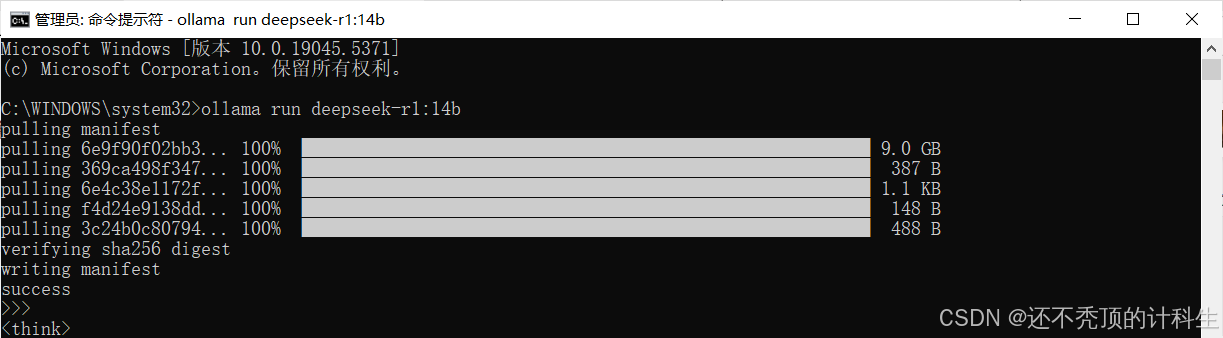
这就代表安装成功啦!
然后我们可以输入相关的问题,它会自动给我们输出回答:
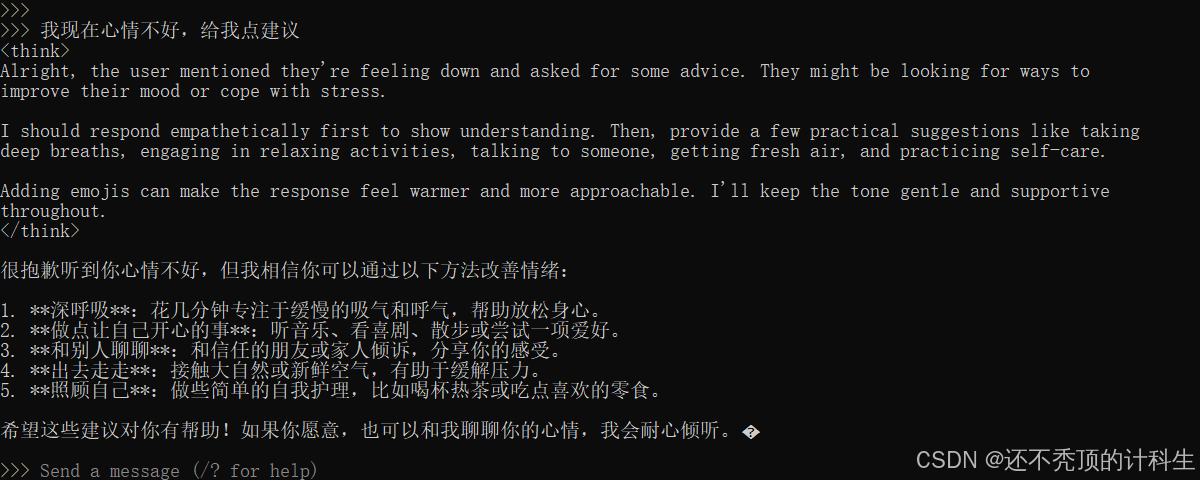
但是这有一个问题就是,可视化效果不佳,界面不美观。
第四部分:安装可视化工具
(1)下载chatbox ai
Chatbox AI官网:办公学习的AI好助手,全平台AI客户端,官方免费下载
(2)开始安装chatbox ai
①选择只为我安装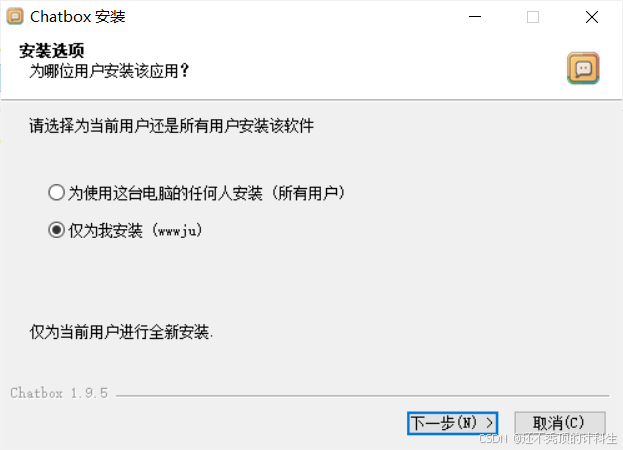
②默认安装在c盘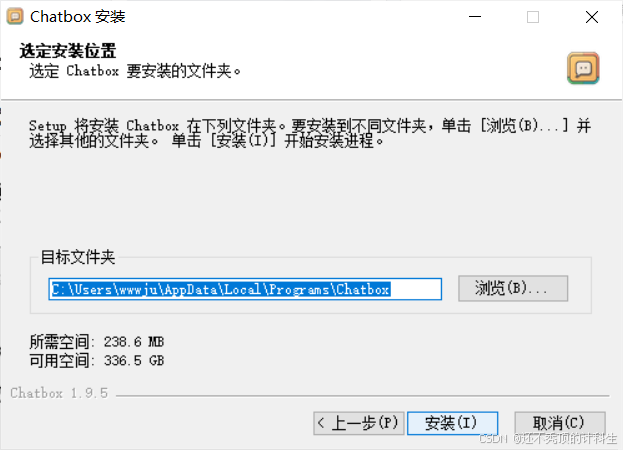
C:\Users\wwwju\AppData\Local\Programs\Chatbox
点击安装就可以了。
(3)开始使用 chatbox ai
打开chatbox ai之后:
①选择第二个选项“本地模型”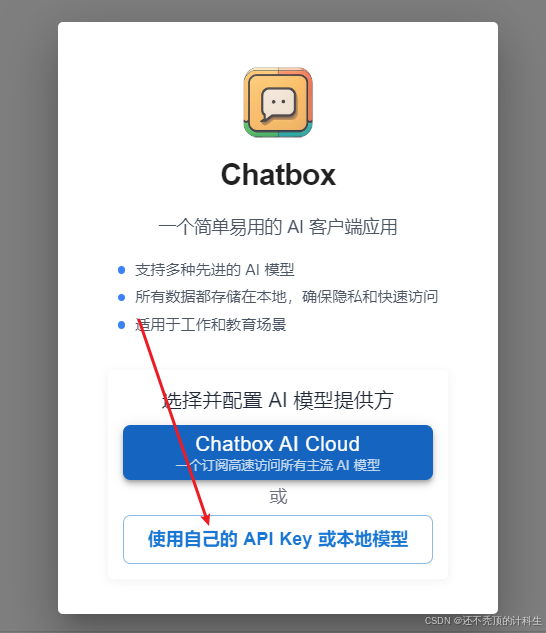
②然后选择ollama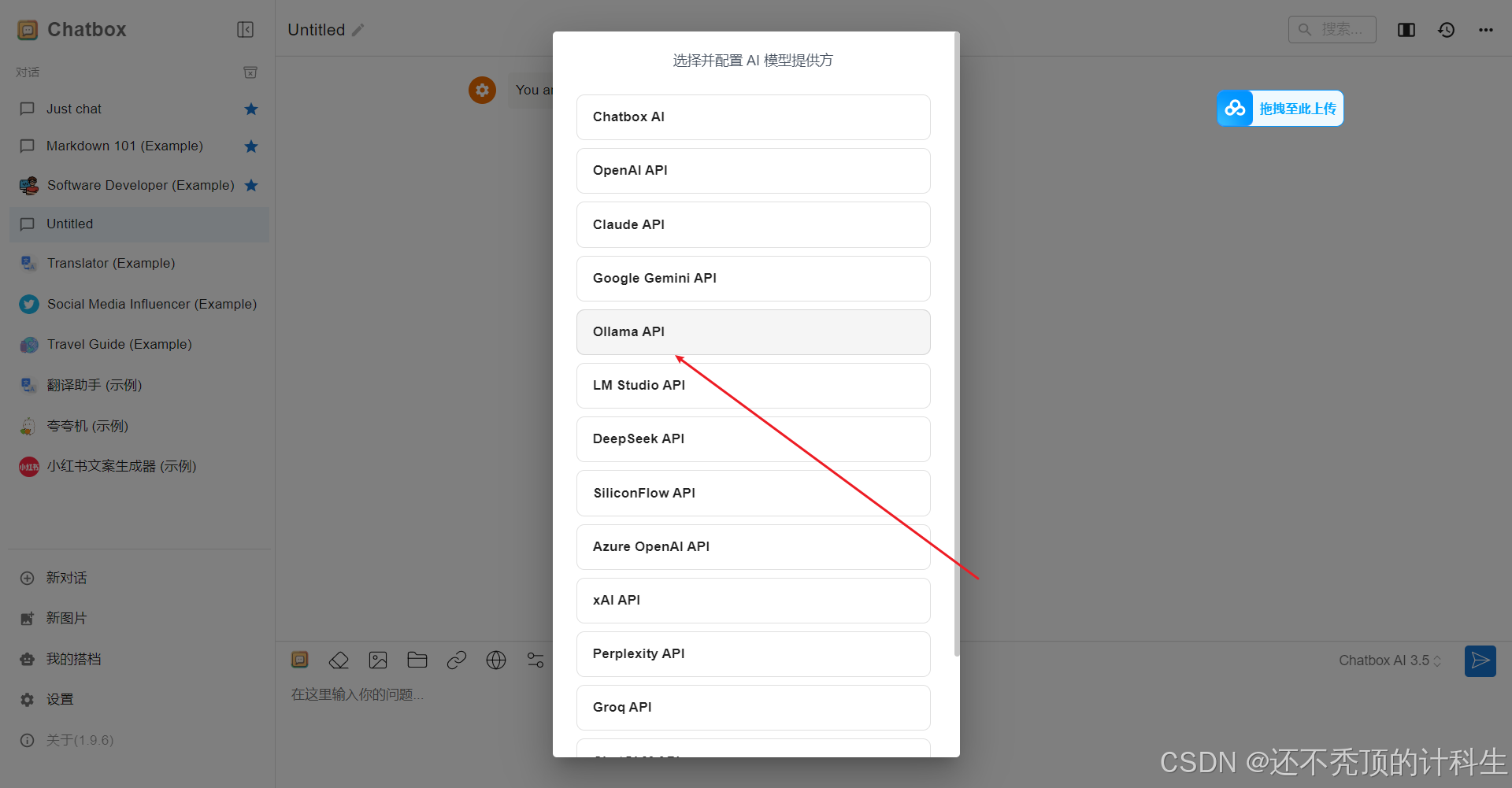
③这里会自动出现本地大模型的选项,我们进行勾选,然后点击保存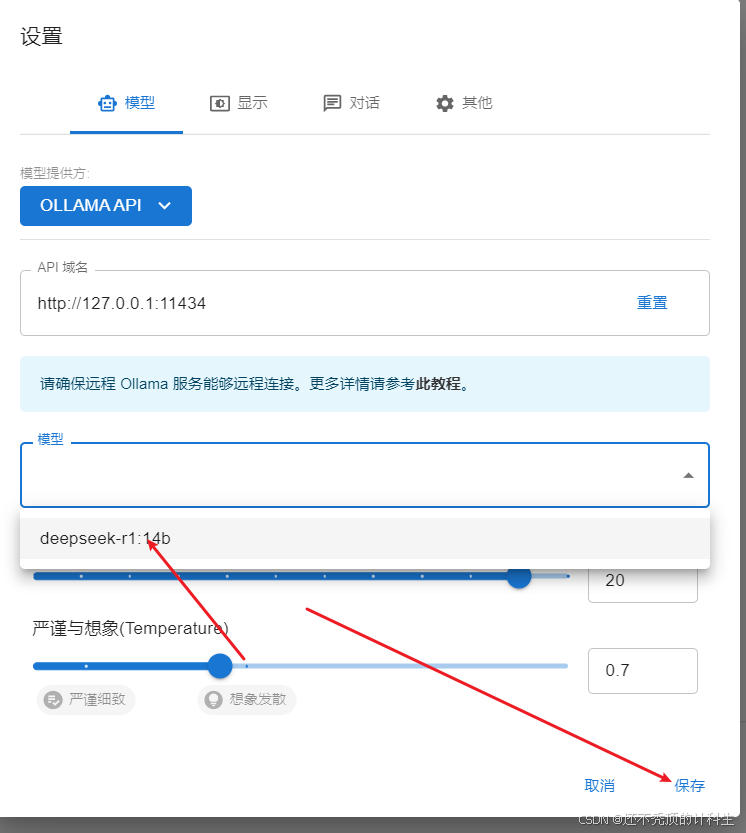
④接着我们就可以直接在这里使用deepseek了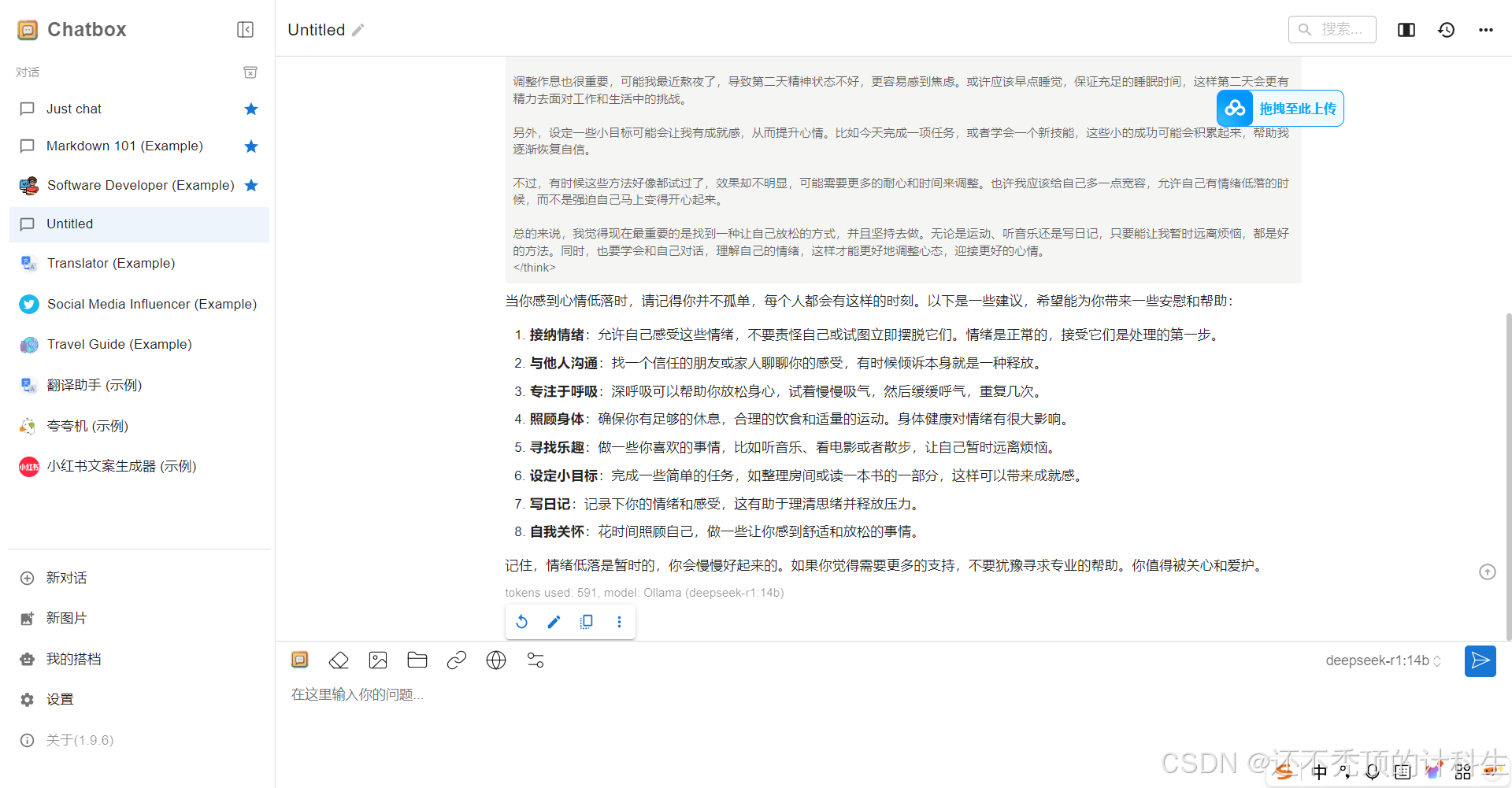
第五部分:优点
本地部署的deepseek不受网络限制,而且完全免费
第六部分:参考文献
超详细❗️2步把DeepSeek装进电脑,还能可视化 - 小红书
第七部分:资源获取
通过网盘分享的文件:deepseek本地部署.zip
链接: https://pan.baidu.com/s/1gQoARDACzxFnCMhhAqjvHw?pwd=uftb 提取码: uftb
--来自百度网盘超级会员v5的分享



















 1771
1771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











