







将自己写过的一些代码和功能整理一下,数据科学这块首先想做的就是关于数据的预处理,通过类的方式可以比较轻松地整合诸多数据预处理的方法,以下为源码。
import numpy as np
import pandas as pd
"""This file is used to do data pre-processing.
The class DataPreProcessingForNumpyArray contains functions ad shown below:
standarlize:标准化(Z-score)
noemalization:0-1化
equalization:均值化
min_max_negation:min-max负值化"""
class DataProcessingForNumpyArray:
def __init__(self,data):
"""To store data for being processed"""
self.data = data
(self.r, self.c) = self.data.shape
"""Standardlize the data"""
def standarlization(self, r_or_c = 0, selected = None):
"""Arguments:
r_or_c: int determines whether the function processes data by rows or columns,
0 refers to rows and 1 refers to columns, 0 is the default value
selected: list determines which rows or columns to be processed
if not defiend, the function will process all data
"""
def Z_Score(data):
mean = np.mean(data)
std_dev = np.std(data)
norm_data = (data - mean) / std_dev
return norm_data
if selected == None:
selected = [i for i in range(0,self.data.shape[r_or_c])]
if r_or_c == 0:
for i in selected:
data = self.data[i,:]
self.data[i,:] = Z_Score(data)
elif r_or_c == 1:
for j in selected:
data = self.data[:,j]
self.data[:,j] = Z_Score(data)
"""Normalize the data"""
def normalization(self, r_or_c = 0, selected = None):
"""Arguments:
r_or_c: int determines whether the function processes data by rows or columns,
0 refers to rows and 1 refers to columns, 0 is the default value
selected: list determines which rows or columns to be processed
if not defiend, the function will process all data
"""
def unil(data):
data = (data - np.min(data)) / (np.max(data) - np.min(data))
return data
if selected == None:
selected = [i for i in range(0,self.data.shape[r_or_c])]
if r_or_c == 0:
for i in selected:
data = self.data[i,:]
self.data[i,:] = unil(data)
elif r_or_c == 1:
for j in selected:
data = self.data[:,j]
self.data[:,j] = unil(data)
"""Equalize the data"""
def equalization(self, r_or_c = 0, selected = None):
"""Arguments:
r_or_c: int determines whether the function processes data by rows or columns,
0 refers to rows and 1 refers to columns, 0 is the default value
selected: list determines which rows or columns to be processed
if not defiend, the function will process all data
"""
if selected == None:
selected = [i for i in range(0,self.data.shape[r_or_c])]
if r_or_c == 0:
for i in selected:
data = self.data[i,:]
self.data[i,:] = self.data[i,:]/np.mean(data)
elif r_or_c == 1:
for j in selected:
data = self.data[:,j]
self.data[:,j] = self.data[:,j]/np.mean(data)
"""Negatize """
def min_max_negation(self,r_or_c =0,selected = None):
"""Arguments:
r_or_c: int determines whether the function processes data by rows or columns,
0 refers to rows and 1 refers to columns, 0 is the default value
selected: list determines which rows or columns to be processed
if not defiend, the function will process all data
"""
if selected == None:
selected = [i for i in range(0, self.data.shape[r_or_c])]
if r_or_c == 0:
for i in selected:
data = self.data[i,:]
ma = np.max(data)
mi = np.min(data)
self.data[i,:] = ma - data + mi
elif r_or_c == 1:
for j in selected:
data = self.data[:,j]
self.data[:,j] = self.data[:,j]/np.mean(data)
"""Save data as an excel file"""
def save_data(self,filename,savepath = None):
"""filename: a string end with ".xlsx"
savepath: an availible system path"""
df = pd.DataFrame(self.data)
if not savepath:
df.to_excel(filename)
else:
df.to_excel(savepath + filename)该类一共有五个方法——四个是数据预处理的方法,一个是用于保存数据,四种预处理方法的具体功能根据其名字就能看出,具体使用方法是先实例化该类,然后调用方法,如果需要的话可以保存。
第一步,实例化该类需要传入type为numpy array且元素类型均为int或float的对象。
第二步,调用该实例下的四种预处理方法,它们有一致的参数:r_or_c为0或1的整型数据,指代是以行或列处理数据,0代表将一行视为一个指标进行处理,1代表将一列视为一个指标进行处理;selected应当是list,是选填选项,指代需要处理的行或列,若不指定则默认处理所有行或列。
第三步,保存数据必填参数为以".xlsx"为结尾的文件名,选填保存路径,若不填保存路径则默认保存在程序所在的文件夹下。
使用例,其中,”data.xlsx“为如下图所示的数据表格:
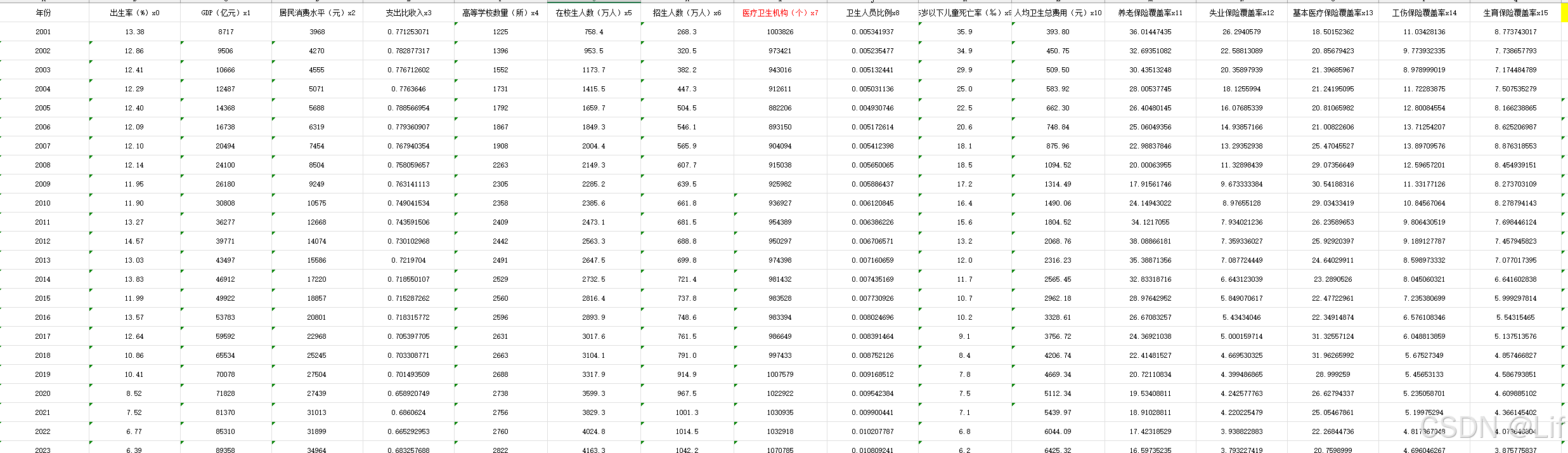
save_path = 'C:\\Users\\Technicolor\\Desktop\\pythonProject\\test\\datas\\'
Data = pd.read_excel("data.xlsx")
data = Data.values[:,1:]
dt = DataProcessingForNumpyArray(data)
dt.equalization(r_or_c=1)
dt.save_data(filename="test.xlsx",savepath=save_path)
















 316
316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









