







目录
前言
在C++官网经常能看到这样的标注:
学习C++之前,我有这样的疑惑:C++98和C++11是什么意思呢?98比11大呀,那么C++98应该比C++11更牛呀,为什么看C++招聘信息的时候大多又都要求了解C++11特性呢?这个后缀11和98到底是什么意思呢?
原来,C++98是1998年发布的C++标准,C++11是2011年发布的C++标准。相比于C++98,C++11带来了数量可观的变化,其中包含了约140个新特性,以及对C++98标准中约600个缺陷的修正,C++11能更好地用于系统开发和库开发、语法更加泛化和简单化、更加稳定和安全,功能更强大,所以C++11应该重点学习。
1. 统一的列表初始化
1.1 {} 初始化
C++98标准允许使用花括号{}对数组或者结构体元素进行统一的列表初始化,例如:
struct S
{
int n;
int id;
};
int main()
{
// {}初始化
//
// C++98
int a1[] = { 1,2,3,4 };
int a2[] = { 9,8,7,6,5 };
S s = { 1,2 };
return 0;
}C++11扩大了用大括号括起的列表(初始化列表)的使用范围,使其可用于所有的内置类型和自定义的类型,使用初始化列表时,可添加等号(=),也可不添加,例如:
struct S
{
int n;
int id;
};
int main()
{
// {}初始化
//
// C++98
int a1[] = { 1,2,3,4 };
int a2[] = { 9,8,7,6,5 };
S s1 = { 1,2 };
// C++11
int x = 5;//C++98
int y{ 5 };//C++11
int a3[] = { 1,2,3,4 };//C++98
int a4[]{ 1,2,3,4 };//C++11
S s2 = { 1,2 };//C++98
S s3{ 1,2 };//C++11
// C++11中列表初始化也适用于new表达式中
int* pa = new int[3]{ 1,2,3 };
return 0;
}创建对象时也可以使用列表初始化方式调用构造函数初始化。
class Date
{
public:
Date(int year, int month, int day)
:_year(year)
,_month(month)
,_day(day)
{}
private:
int _year;
int _month;
int _day;
};
int main()
{
Date d1(2025, 3, 4);//C++98
// C++11支持列表初始化,这里的原理为:构造+拷贝构造-->优化为直接构造
Date d2{ 2025,3,4 };
Date d3 = { 2025,3,4 };
// C++11创建对象也适用new表达式
Date* da1 = new Date[3]{ d1,d2,d3 };// 拷贝构造
Date* da2 = new Date[3]{ {2025,3,1},{2025,3,2},{2025,3,3} };// 构造+拷贝构造-->优化为直接构造
Date* da3 = new Date(2025, 3, 4);// C++98
Date* da4 = new Date{ 2025,3,3 };// C++11
return 0;
}1.2 std::initializer_list
1.了解initializer_list
了解了上面介绍的{}初始化,我们也可以认为:C++11令一切皆可用 {} 初始化。
既然C++11支持一切皆可用{}初始化,那么STL的容器是否也支持呢?用vector试一下:
std::vector<int> a1 = { 1,2,3,4,5 };
很完美,编译器没有报错(事实上在我们之前的文章里已经经常这样用了)
既然可以这样用,我还记得在C++番外篇——vector的实现里,我们自己完成过vector的实现呀!那我也拿我自己的vector用{}初始化一下:
xxk::vector<int> a2 = { 1,2,3,4 };
遗憾的是,编译器报错了,Oi!为什么std的vector就可以这样,我自己的vector就不能这样用呢?
没错,从报错提示可以看出:我们自己的vector其实并没有封装initializer list,那这又是个什么东西呢?
官网有这样的介绍:
此类型用于访问C++初始化列表中的值,该列表是Const T类型的元素列表。
此类型的对象由编译器根据初始化列表声明自动构造,初始化列表声明是以逗号分隔的列表
用大括号括起来的元素。
看一下输出结果:
int main()
{ auto il = { 10, 20, 30 };
cout << typeid(il).name() << endl;
auto il2 = { "苹果","香蕉"};
cout << typeid(il2).name() << endl;
return 0;
}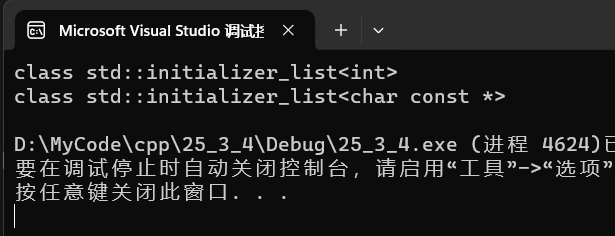
可见std::initializer_list<T> 是一个模板类,其中 T 表示列表中元素的类型。
(std::initializer_list内部只包含两个指针(指向列表的起始和结束位置),因此它的拷贝操作非常高效,只是复制这两个指针,而不会复制列表中的元素。)
2.改造vector
因此,std::initializer_list一般是作为构造函数的参数,这就是为什么vector支持{}初始化,事实上,不仅vector,C++11对STL中的很多容器都增加 std::initializer_list作为参数的构造函数,这样初始化容器对象就更方便了。
下面就改造我们的vector,使我们自己的vector也支持{}初始化:
vector(initializer_list<T> il)
{
reserve(il.size());
for (auto& e : il)
{
push_back(e);
}
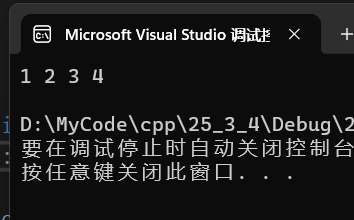
}int main()
{
xxk::vector<int> a2 = { 1,2,3,4 };
for (auto e : a2)
{
cout << e << " ";
}
cout << endl;
return 0;
}
2.声明
2.1 auto关键字
在C++98中auto是一个存储类型的说明符,表明变量是局部自动存储类型,但是局部域中定义局 部的变量默认就是自动存储类型,所以auto就没什么价值了。
C++11中废弃auto原来的用法,将其用于实现自动类型推断,这样要求必须进行显示初始化,让编译器将定义对象的类型设置为初始化值的类型。
例如:
int main()
{
int a = 0;
auto p = &a;
cout << typeid(p).name() << endl;
return 0;
}
比如每个容器的迭代器类型比较复杂,我们直接用auto替代:
vector<int> v1 = { 1,2,3,4 };
//vector<int>::iterator it1 = v1.begin();
auto it1 = v1.begin();
map<string, string> dict = { {"apple", "苹果"}, {"pear", "梨"} };
//map<string, string>::iterator it2 = dict.begin();
auto it2 = dict.begin();2.2 decltype关键字
decltype关键字将变量的类型声明为表达式指定的类型,注意与auto区别开来。
① auto主要用于变量的类型推导;
decltype用于在编译时推导表达式的类型,通常用于获取函数返回值类型、模板编程等场景。
auto add(int a, int b)
{
return a + b;
}
int main()
{
auto x = 1;// auto推导x为int类型
std::vector<int> v = { 1,2,3 };
auto it = v.begin();// auto推导it为std::vector<int>::iterator 类型
int a = 1, b = 2;
decltype(add(a, b)) c;//decltype推导出add(a, b)表达式的值为int
c = add(a, b);
return 0;
}② auto推导时会忽略引用和const限定符,除非显示指定;
decltype会保留表达式的引用和const限定符。
int main()
{
const int num1 = 10;
auto a = num1;// auto 推导a为 int 类型,忽略 const 限定符
const auto b = num1;// 显式指定 const,推导a为 const int 类型
int num2 = 10;
int& ref = num2;
decltype(ref) pref = num2;// decltype 推导pref为 int& 类型,保留引用
return 0;
}2.3 nullptr
由于C++中NULL被定义成字面量0,这样就可能会带来一些问题,因为0既能指针常量,又能表示整形常量。所以出于清晰和安全的角度考虑,C++11中新增了nullptr,用于表示空指针。
2.4 STL中的新容器
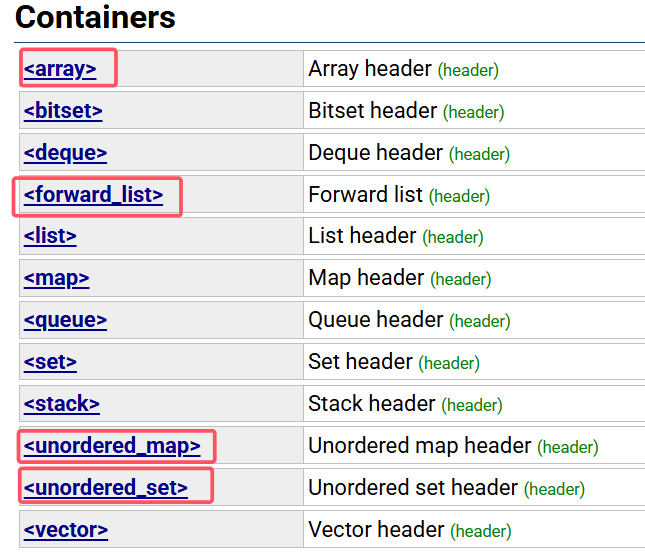
array、forword_list、unordered_map、unordered_set都是C++11才加进来的新容器,这里着重讲一下 unordered_map和unordered_set:
问题①:unordered_map、unordered_set与map、set的区别?
map与set是基于红黑树实现的,红黑树会对元素进行排序,二者使元素在树中按照键的顺序排列;
unordered_map与unordered_set是基于哈希表实现的,哈希表通过哈希函数将键映射到哈希表的特定位置,以此来存储和查找元素,二者使元素在内存中是无序存储的;
unordered_map 和 unordered_set适用于对插入、查找和删除操作的性能要求较高,且不关心元素顺序的场景,map和set适用于需要对元素进行排序,或者需要按照键的顺序进行遍历的场景。
问题②: unordered_map和unordered_set有什么区别?
unordered_map用于存储键值对(Key,Value),每个键必须是唯一的,通过键可以快速查找对应的值,键和值可以是不同的数据类型,适用于需要根据某个键快速查找对应值的场景(如字典);
unordered_set只存储唯一的元素,不存储键值对。适用于检查元素是否存在,或者去除重复元素的场景。
3. 右值引用和移动语义
3.1 左值引用与右值引用
①左值?右值?
左值是一个表示数据的表达式(如变量名或解引用的指针),我们可以获取它的地址并且一般情况下可以对它赋值,左值可以出现赋值符号的左边,右值不能出现在赋值符号左边。定义时用const修饰后的左值,不能给他赋值,但是可以取它的地址;
右值也是一个表示数据的表达式,如:字面常量、表达式返回值,函数返回值(这个不能是左值引用返回)等等,右值可以出现在赋值符号的右边,但是不能出现出现在赋值符号的左边,右值不能取地址。
举例:

②引用?左值引用?右值引用?
在本专栏的第一篇文章C++入门1——从C语言到C++的过渡中我们介绍了引用的概念和用法,所以在C++11之前就有了引用的语法,那时所讲的引用都是左值引用,而C++11中新增了的右值引用语法特性。但是我们应该明确:无论左值引用还是右值引用,都是给对象取别名。因此:
左值引用就是对左值的引用,给左值取别名;
右值引用就是对右值的引用,给右值取别名。
举例:

那么现在就对初学C语言时出现低级报错的原因理解地更为透彻了:

总结:
在语法上,引用都是给对象取别名,不开空间,左值引用是给左值取别名,右值引用是给右值取别名;
在底层,引用是用指针实现的。左值引用是存当前左值地地址。右值引用是把当前右值拷贝到栈上地一个临时空间,存储这个临时空间地地址。
③左引右?右引左?
我们已经了解了左值引用和右值引用,并且也略微了解了二者的底层原理,那么我能不能倒反天罡,用左值引用给右值取别名,用右值引用给左值取别名呢?
答:
左值引用不能给右值取别名,但是const左值引用可以给右值取别名;
右值引用也不能给左值取别名,但是右值引用可以给move以后的左值取别名。

按照语法,右值引用只能引用右值,但某些场景下,可能真的需要用右值去引用左值实现移动语义。当需要用右值引用引用一个左值时,可以通过move函数将左值转化为右值。C++11中,std::move()函数位于头文件中,该函数名字具有迷惑性, 它并不搬移任何东西,唯一的功能就是将一个左值强制转化为右值引用,然后实现移动语义。
3.2 右值引用的意义
1.左值引用的使用场景与短板
上面我们已经说过了:左值引用既可以给左值取别名,又可以加const给右值取别名,既然左值引用既可以给左值取别名,又可以给右值取别名,那C++11为什么又要新增一个右值引用呢?
这样做是不是有些鸡肋呢?解答这个问题之前,我们先来回顾一下左值引用的使用场景:
文章C++入门1——从C语言到C++的过渡里我们提到:(左值)引用①可以做参数②可以做返回值
左值引用做参数和返回值都可以提高效率,可是在这篇文章里,我们还提到了一个问题:
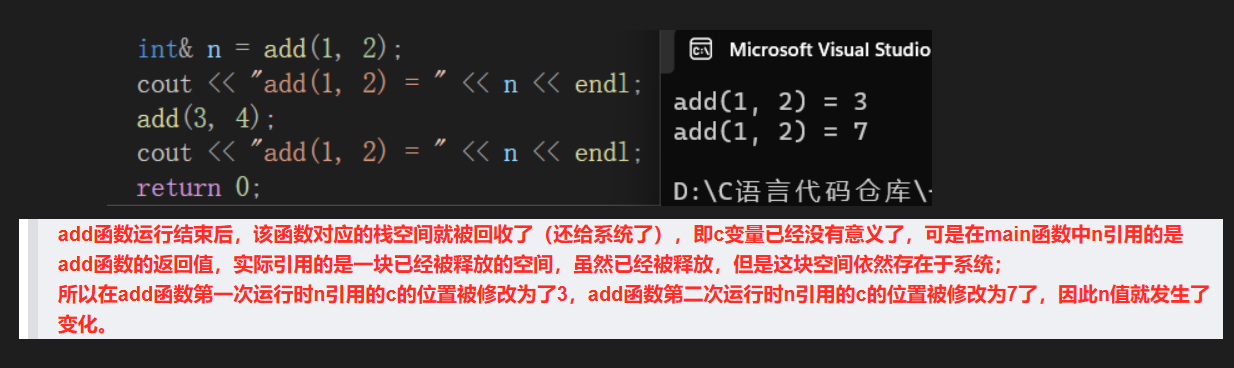
所以当左值引用做参数时是没问题的,可左值引用做返回值时,当函数返回对象是一个局部变量,出了函数作用域就不存在了,就不能使用左值引用返回, 只能使用传值返回。
接下来调用我们自己实现的string,然后分别设计传值返回和传左值引用返回的两个函数:
(关于string的实现,欢迎查看往期文章C++番外篇——string类的实现)
void func1(xxk_string::string s)//传值引用
{}
void func2(xxk_string::string& s)//传左值引用
{}
int main()
{
xxk_string::string s("12345");
func1(s);
func2(s);
return 0;
}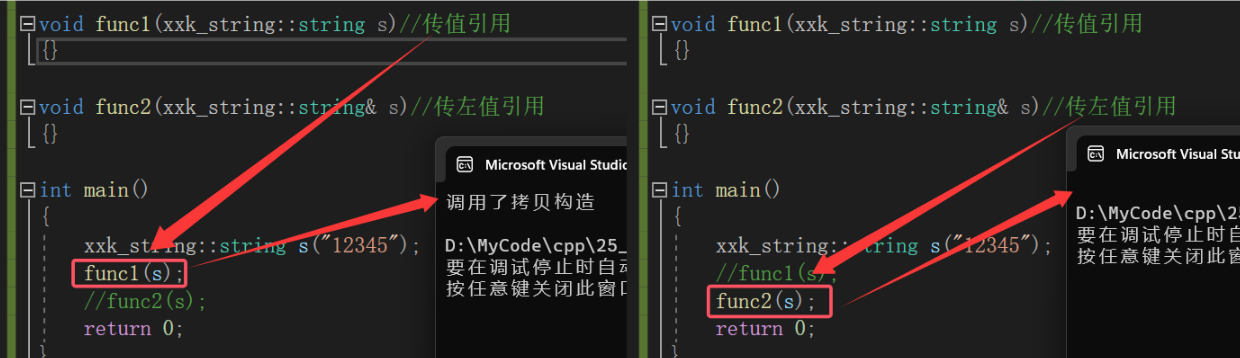
由运行结果可知:
传值返回存在拷贝,传左值引用返回没有拷贝进而提高了效率,所以传左值引用的优点是可以提高效率。但是!!!我们通过以上的add函数已经分析过了,当函数返回对象是一个局部变量,出了函数作用域就不存在了,就不能使用左值引用返回, 只能使用传值返回!!!,所以就算你传左值返回效率再高,对我没有卵用呀!
2.浅析传值返回
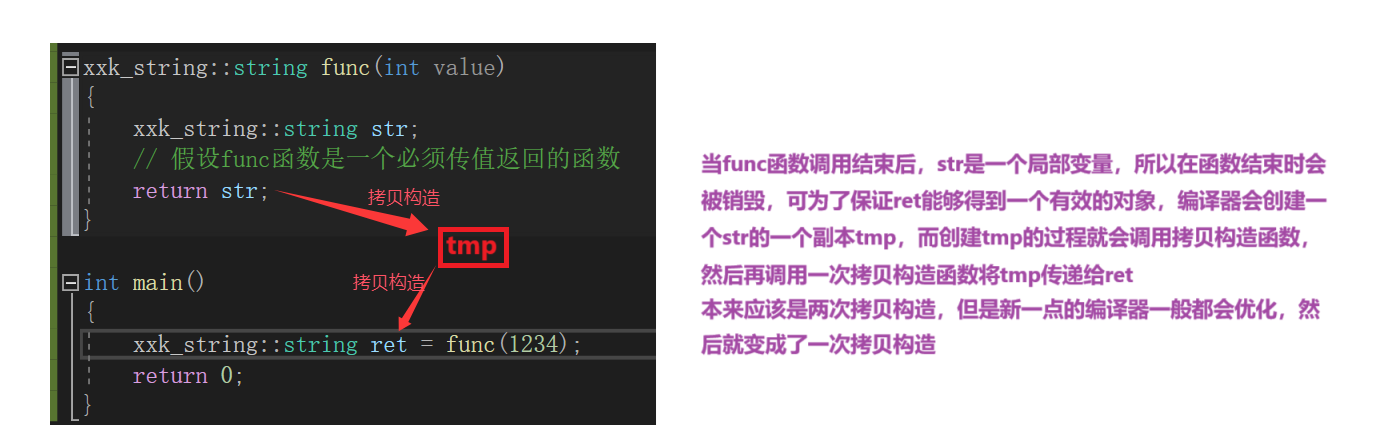
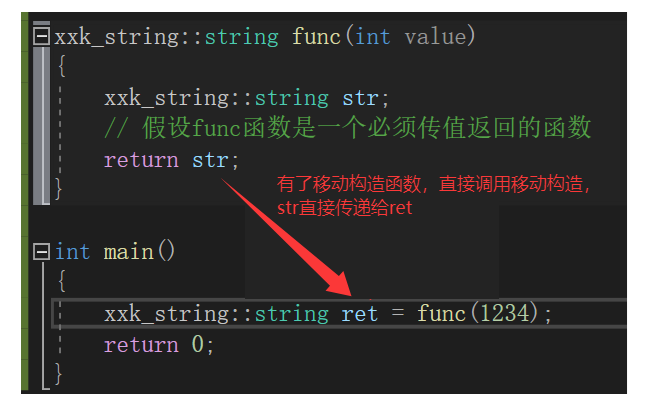
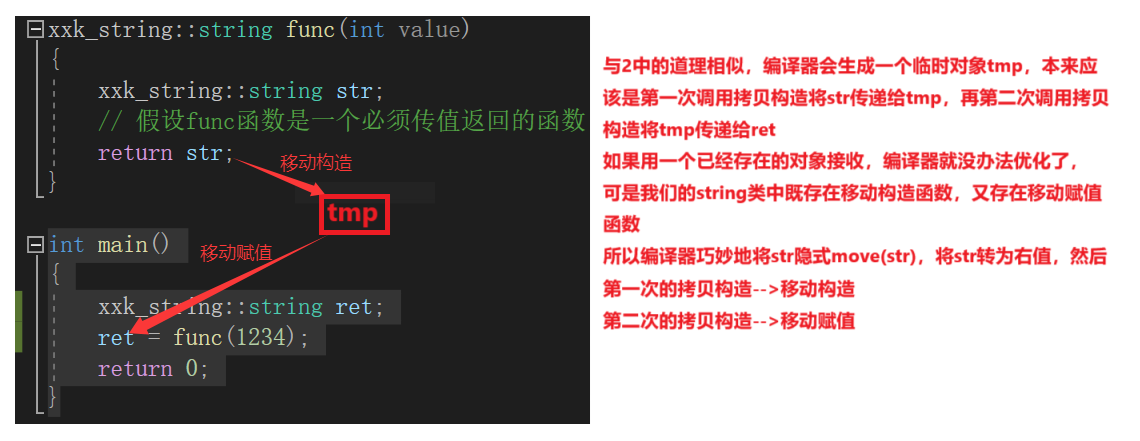
假设func函数的功能是一个必须要传值返回才能实现的函数。
xxk_string::string func(int value)
{
xxk_string::string str;
// 假设func函数是一个必须传值返回的函数
return str;
}
int main()
{
xxk_string::string ret = func(1234);
return 0;
}
3.移动构造函数与移动语义
也许在我们举的示例中并不会觉得调用两次拷贝构造有什么影响,可是如果有些对象对空间消耗巨大,又必须使用传值返回,使用传值返回又必须存在拷贝,这是一种极度浪费资源又效率低下的做法,所以在C++11之前,编译器做了很多努力,将本该的两次拷贝优化为一次拷贝;
可是如果对象足够大,这种努力可以说是微乎其微的,所以在C++11之后引入了右值引用,在此基础上进一步努力减少拷贝,令传值引用时没有拷贝
现在,我们在string类里封装一个移动构造函数:
// 移动构造
string(string&& s)
:_str(nullptr)
,_size(0)
,_capacity(0)
{
cout << "调用了移动构造" << endl;
swap(s);
}运行结果:
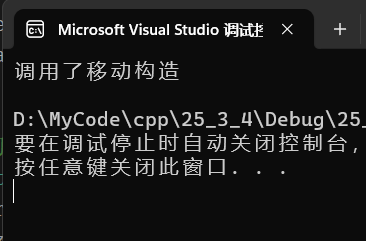
移动构造本质是将参数右值的资源窃取过来,占为已有,那么就不用再调用拷贝构造进行深拷贝了,所以它叫做移动构造,就是窃取别人的资源来构造自己,移动构造中没有新开空间,拷贝数据,所以效率提高了。

4. 移动赋值函数
其实,不仅存在移动构造函数,还存在移动赋值函数,给我们的string添加移动赋值函数:
// 移动赋值
string& operator=(string&& s)
{
cout << "调用了移动赋值函数" << endl;
swap(s);
return *this;
}int main()
{
xxk_string::string ret;
ret = func(1234);
return 0;
}此时运行结果:
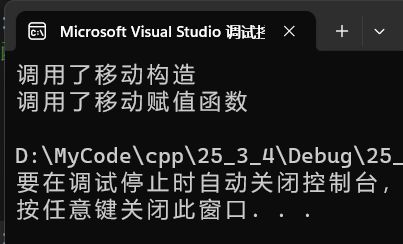

所以,C++学到现在,我们就应该知道:类的默认成员函数不是6个,而是8个,即在C++入门3——类与对象2(类的6个默认成员函数)的基础上新增了移动构造函数和移动赋值函数,在C++11之后,STL的容器中都新增了移动构造函数和移动赋值函数。
3.3 完美转发
在实现某个功能时,我有时需要传左值,有时又需要传右值,我也只希望设计一个函数就能既接收左值又能接收右值,有没有办法呢?或者换句话说,有没有一种方法能帮我直接推断传过来的参数是左值还是右值呢?
既然模板可以自动判断类型,相同的道理,我们使用模板也可以实现自动判断左值和右值,例如:
template<typename T>
void Perfect(T&& t)
{
//
}
int main()
{
Perfect(10);// 右值
int a;
Perfect(a);// 左值
Perfect(std::move(a)); // 右值
const int b = 8;
Perfect(b);// const 左值
Perfect(std::move(b)); // const 右值
return 0;
}注意:
不能单纯地把模板中的&&理解为右值引用,在这里&&是万能引用,其既能接收左值又能接收右值,它能自动判断传来的参数是左值还是右值,传来的是左值,&&就是左值引用;传来的是右值,&&就是右值引用。模板的万能引用只是提供了能够同时接收左值引用和右值引用的能力。
接下来我们添加fun()函数,观察现象:
void fun(int& x)
{
cout << "左值引用" << endl;
}
void fun(const int& x)
{
cout << "const左值引用" << endl;
}
void fun(int&& x)
{
cout << "右值引用" << endl;
}
void fun(const int&& x)
{
cout << "const右值引用" << endl;
}
template<typename T>
void Perfect(T&& t)
{
fun(t);
}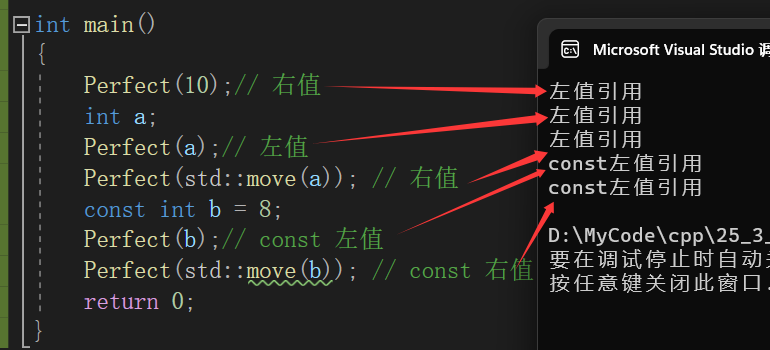
运行结果显示,尽管为左值、const左值、右值、const右值都分别添加了对应的函数,可结果显示都只调用了左值引用,我明明传的是右值,我全指望这个右值给我实现一些功能呢,好家伙,这函数模板左右不分啊,全都给我干成左值了!
这是为什么呢?原因是:
&&引用类型的唯一作用就是限制了接收的类型,虽然它已经自动推断了传来的值是左值还是右值,但在后续使用过程中不管左值右值又都退化成了左值,所以才会造成以上的运行结果。
那怎么解决呢?我希望值在传递过程中能始终保持着它的左值或右值属性不被改变,如何解决呢?
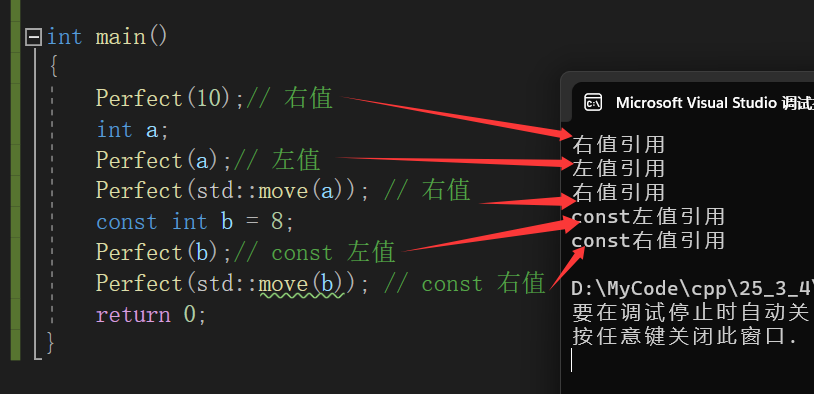
是的,用Prefect,你的回答非常Prefect!
C++11中的std::forward在传参过程中保留对象原生类型的属性。
template<typename T>
void Perfect(T&& t)
{
fun(std::forward<T>(t));
}
运行结果如图:
4. 类中新的默认成员函数
在3.2(4)中我们已经提到,在C++11之后,类的默认成员函数从6个变成了8个,即:
①构造函数②析构函数③拷贝构造函数④拷贝赋值重载⑤取地址重载⑥const 取地址重载
和新增的
⑦移动构造函数⑧移动赋值运算符重载函数
对于默认成员函数,我们已经知道:默认成员函数就是我们不写编译器也会默认生成的。
可对于新增的移动构造和移动赋值,应该注意:
①如果我们没有自己实现移动构造函数,并且也没有实现析构函数、拷贝构造、拷贝赋值重载中的任意一个,这时编译器才会自动生成一个默认的移动构造。默认生成的移动构造函数,对于内置类型会执行逐成员按字节拷贝,对于自定义类型成员,则需要看这个成员是否实现了移动构造,如果这个成员实现了就调用移动构造,没有实现就调用拷贝构造;
②移动赋值重载函数与移动构造类似,如果没有自己实现移动赋值重载函数,并且也没有实现析构函数、拷贝构造、拷贝赋值重载的任意一个,这时编译器才会自动生成一个默认的移动赋值重载函数。默认生成的移动赋值重载函数,对于内置类型会执行逐成员按字节拷贝,对于自定义类型成员,则需要看这个成员是否实现了移动赋值,如果这个成员实现了就调用移动赋值重载函数,没有实现就调用拷贝赋值;
③如果我们自己实现了移动构造或移动赋值,编译器就不会自动生成。
5. lambda表达式
5.1 问题探究
当对数组排序时,我们使用sort函数默认是对数组进行升序排列,若想实现降序排列,添加一个仿函数即可:
int main()
{
vector<int> v = { 3,6,1,9,2,7,5,10,4,8 };
// 默认进行升序排列
sort(v.begin(), v.end());
// 添加仿函数,自定义为降序排列
sort(v.begin(), v.end(), greater<int>());
return 0;
}可当我们有自定义类型的数据时,想根据自定义类型不同的数据来设计不同的比较规则,比如:
class fruits
{
public:
fruits(const char* name, double price, int evaluate)
:_name(name)
,_price(price)
,_evaluate(evaluate)
{}
private:
string _name;//名称
double _price;//价格
int _evaluate;//评分
};我想根据水果的价格和评分,分别实现升序和降序排列,那么我就要实现4个仿函数类了:
int main()
{
vector<Fruits> v1 = { {"苹果",2.5,5},{"梨",3.0,7},{"菠萝",5.5,8},{"榴莲",20.4,10},{"石榴",15.8,9} };
vector<Fruits> v2 = { {"苹果",2.5,5},{"梨",3.0,7},{"菠萝",5.5,8},{"榴莲",20.4,10},{"石榴",15.8,9} };
vector<Fruits> v3 = { {"苹果",2.5,5},{"梨",3.0,7},{"菠萝",5.5,8},{"榴莲",20.4,10},{"石榴",15.8,9} };
vector<Fruits> v4 = { {"苹果",2.5,5},{"梨",3.0,7},{"菠萝",5.5,8},{"榴莲",20.4,10},{"石榴",15.8,9} };
sort(v1.begin(), v1.end(), ComparePriceLess());
sort(v2.begin(), v2.end(), ComparePriceGreater());
sort(v3.begin(), v3.end(), CompareEvaluateLess());
sort(v4.begin(), v4.end(), CompareEvaluateGreater());
return 0;
}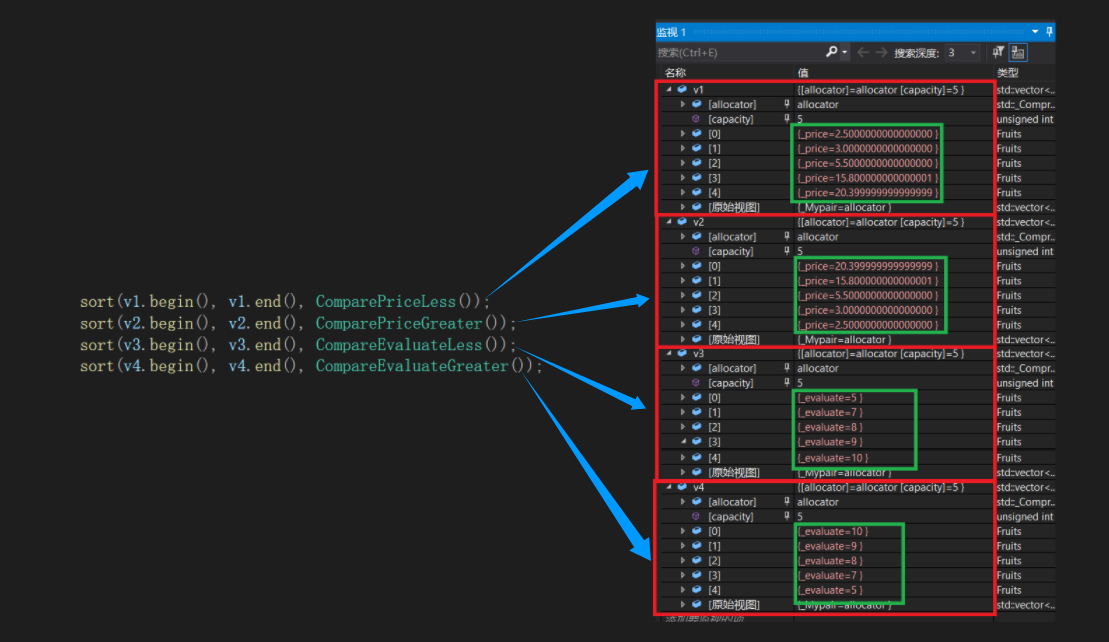
可这样做是不是有些太麻烦了,我想实现四种不同的比较规则就要实现四种不同的仿函数,那我现在还想实现用水果名称的首字母来排序的比较规则,那我还得实现一个仿函数。
5.2 lambda表达式语法
为了解决上述问题,实现更便捷的编程方法,C++11引入了lambda表达式。
lambda表达式书写格式:

说明:
[capture-list] : 捕捉列表。该列表总是出现在lambda函数的开始位置,编译器根据[]来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda 函数使用;
(parameters):参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同()一起省略;
mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。使用该修饰符时,参数列表不可省略(即使参数为空);
->returntype:返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分可省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推导;
{statement}:函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量。
(在lambda函数定义中,参数列表和返回值类型都是可选部分,而捕捉列表和函数体可以为 空。因此C++11中最简单的lambda函数为:[]{}; 该lambda函数不能做任何事情。)
根据语法规则,那我们的代码就可以修改为:
int main()
{
vector<Fruits> v = { {"苹果",2.5,5},{"梨",3.0,7},{"菠萝",5.5,8},{"榴莲",20.4,10},{"石榴",15.8,9} };
sort(v.begin(), v.end(), [](const Fruits& f1, const Fruits& f2) {
return f1._price < f2._price; });
sort(v.begin(), v.end(), [](const Fruits& f1, const Fruits& f2) {
return f1._price > f2._price; });
sort(v.begin(), v.end(), [](const Fruits& f1, const Fruits& f2) {
return f1._evaluate < f2._evaluate; });
sort(v.begin(), v.end(), [](const Fruits& f1, const Fruits& f2) {
return f1._evaluate > f2._evaluate; });
return 0;
}5.3 捕捉列表的说明
捕捉列表描述了上下文中那些数据可以被lambda使用,以及使用的方式是传值使用还是传引用使用。
| [ ] | 说明 |
| [var] | 表示值传递方式捕捉变量var |
| [=] | 表示值传递方式捕获所有父作用域中的变量(包括this) |
| [&var] | 表示引用传递捕捉变量var |
| [&] | 表示引用传递捕捉所有父作用域中的变量(包括this) |
| [this] | 表示值传递方式捕捉当前的this指针 |
解释:
①父作用域指包含lambda函数的语句块;
②语法上捕捉列表可由多个捕捉项组成,并以逗号分割。 比如:[=, &a, &b]:以引用传递的方式捕捉变量a和b,值传递方式捕捉其他所有变量 [&,a, this]:值传递方式捕捉变量a和this,引用方式捕捉其他变量;
③捕捉列表不允许变量重复传递,否则就会导致编译错误。 比如:[=, a]:=已经以值传递方式捕捉了所有变量,捕捉a重复;
④在块作用域以外的lambda函数捕捉列表必须为空;
⑤在块作用域中的lambda函数仅能捕捉父作用域中局部变量,捕捉任何非此作用域或者 非局部变量都会导致编译报错;
⑥lambda表达式之间不能相互赋值。
代码举例:
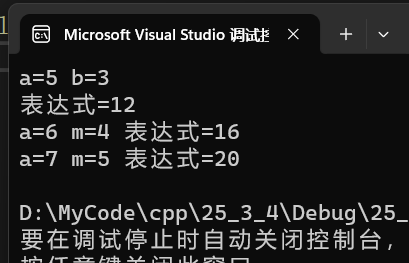
int main()
{
// ①
int a = 3, b = 5;
//传引用捕捉
auto x1 = [&a, &b] {int tmp = a; a = b; b = tmp; };
x1();
cout << "a=" << a << " " << "b=" << b << endl;
// ②
// 传值捕捉当前域所有对象
int m = 3, n = 2;
auto x2 = [=] {return a + b * m - n; };
cout << "表达式=" << x2() << endl;
// ③
// 传引用捕捉当前域所有对象
auto x3 = [&] {a++; m++; return a + b * m - n; };
cout << "a=" << a << " " << "m=" << m << " " << "表达式=" << x3() << endl;
// ④
// 传引用捕捉当前域所有对象,某些对象采用传值捕捉
auto x4 = [&, n] {a++; m++;
// n++; n使用了传值捕捉,不能++
return a + b * m - n;
};
cout << "a=" << a << " " << "m=" << m << " " << "表达式=" << x4() << endl;
return 0;
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









