









在C++入门17——哈希之哈希表详解中,我们了解了哈希算法,那么哈希算法该怎么运用到实际呢?接下来就介绍哈希算法常见的两种应用:位图与布隆过滤器。
1. 位图
1.1 位图的概念
了解位图的概念之前,先来看一道面试题:
①有40亿个未排序的无符号整数,给你一个无符号整数,如何快速判断该数是否存在这40亿个数中?
对于这道题,我们常规的解法通常为:
①直接遍历这40亿个数,判断该数是否存在;该方法可能不够快,那么又有方法②:先将40亿个数排序,再进行二分查找。
似乎方法②更好一些,可是我们还应该注意到:40亿个整数就是160亿字节≈15G,用以上两种方法需要15G的内存空间,先不说有没有造成内存空间浪费,15G的内存对我们的普通电脑来说能不能运行起来都是问题呀!
那么解决上述问题的最佳算法——位图就应运而生了:
所谓位图,就是用每一位来存放某种状态,适用于海量数据,数据无重复的场景。通常是用来判断某个数据是否存在的。
1.2 具体思路
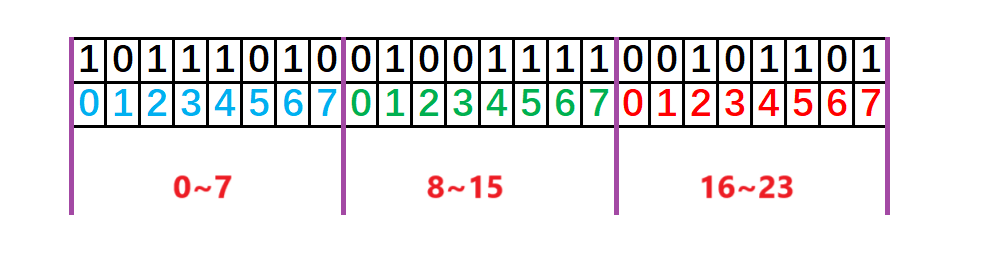
数据是否在给定的整型数据中,结果正好是在或者不在两种状态,可以使用一个二进制比特位来代表数据是否存在的信息,如果二进制比特位为1,代表存在,为0代表不存在。
按照这种思路,40亿个整型数据就需要40亿比特位≈477MB的内存即可完成,大大降低了空间使用率。
如图:
1.3 位图的实现

具体实现如下:
#include <iostream>
#include <vector>
#include <assert.h>
using namespace std;
namespace xxk
{
template <size_t N>
class bitset
{
public:
bitset()
{
//先开辟空间(N个比特位对应N/8/4个整型)
_bit.resize(N / 32 + 1, 0);//+1避免除不尽
}
//将数据映射到开辟好的空间中,映射到的位标记成1(可以理解为插入x)
void set(size_t x)
{
size_t i = x / 32;//计算x映射在第几个整型里
size_t j = x % 32;//计算x映射在第i个整型的第几个比特位里
_bit[i] |= (1 << j);//第i个整型的第j个比特位变为1(先左移再按位或)
}
//将数据映射到开辟好的空间中,映射到的位标记成0(可以理解为删除x)
void reset(size_t x)
{
size_t i = x / 32;//计算x映射在第几个整型里
size_t j = x % 32;//计算x映射在第i个整型的第几个比特位里
_bit[i] &= ~(1 << j);//第i个整型的第j个比特位变为0(先左移取反再按位与)
}
//
bool test(size_t x)
{
assert(x <= N);
size_t i = x / 32;
size_t j = x % 32;
return _bit[i] & (1 << j);//整型转bool值,0为false,非0为true
}
private:
vector<int> _bit;
};
}
测试:
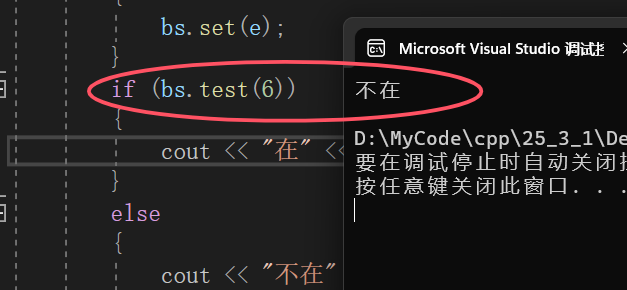
验证6是否在arr中:
void func()
{
int arr[] = { 3,21,22,17,5,18,5,2,12,12,22,5,3,2,5 };
bitset<22> bs;
for (auto e : arr)
{
bs.set(e);
}
if (bs.test(6))
{
cout << "在" << endl;
}
else
{
cout << "不在" << endl;
}
}
再看一道题:
②给定100亿个整数,设计算法找到只出现一次的整数
在第①题中,我们只需判断一个数是否存在即可,所以存在就是1,不存在就是0,一个比特位就可以表示这两种状态;
可这道题显然不止存在两种状态,它存在三种状态:0次,1次,2次及以上,所以3种状态只能用两个比特位来表示了。我们可以在第①题中修改代码,开辟空间时就需要开辟2N个空间了;
不修改以上代码,也可以用以下方法解决:
可以复用以上代码,开辟两个位图,如果x只在其中之一个位图中存在,则符合条件。
具体实现如下:
template <size_t N>
class two_bitset
{
public:
void set()
{
//00->01
if (_bs1.test(x) == false && _bs2.test(x) == false)
{
_bs2.set(x);
}
else if (_bs1.test(x) == false && _bs2.test(x) == true)
{
//01->10
_bs1.set(x);
_bs2.reset(x);
}
//再有就是2次及以上的情况了
}
bool test(size_t x)
{
if (_bs1.test(x) == false && _bs2.test(x) == true)
{
return true;//只有当_bs2中存1时才表明x只出现一次
}
return false;
}
private:
bitset<N> _bs1;
bitset<N> _bs2;
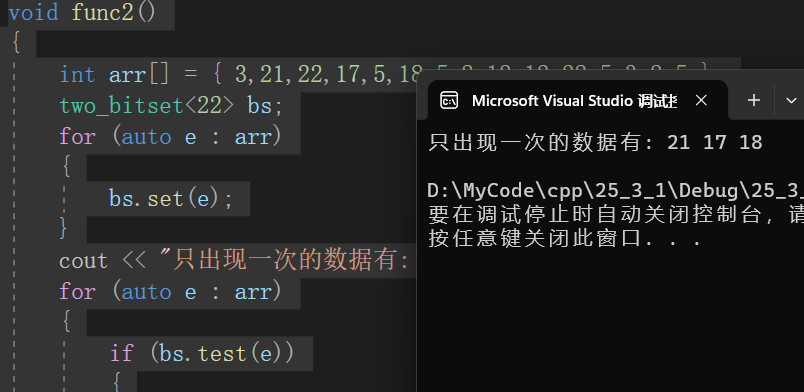
};测试:
void func2()
{
int arr[] = { 3,21,22,17,5,18,5,2,12,12,22,5,3,2,5 };
two_bitset<22> bs;
for (auto e : arr)
{
bs.set(e);
}
cout << "只出现一次的数据有: ";
for (auto e : arr)
{
if (bs.test(e))
{
cout << e << " ";
}
}
cout << endl;
}
再看一道题:
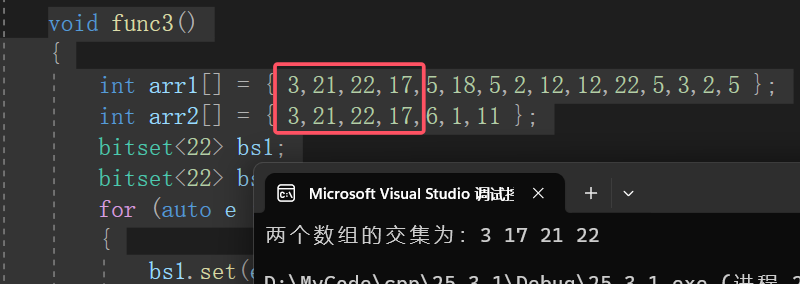
③给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
复用以上代码,很容易解决这个问题:
void func3()
{
int arr1[] = { 3,21,22,17,5,18,5,2,12,12,22,5,3,2,5 };
int arr2[] = { 3,21,22,17,6,1,11 };
bitset<22> bs1;
bitset<22> bs2;
for (auto e : arr1)
{
bs1.set(e);
}
for (auto e : arr2)
{
bs2.set(e);
}
cout << "两个数组的交集为:";
for (size_t i = 0; i < 23; i++)
{
if (bs1.test(i) && bs2.test(i))
{
cout << i << " ";
}
}
cout << endl;
}
小结:
位图的优点:快 + 节省空间;
位图的缺点:位图只能解决整型数据。
2.布隆过滤器
刚刚提到了位图的缺点,位图只能解决整型数据,可现在有这样一个问题:有一堆字符串string[] A,给你一个字符串a,设计算法求a是否在A里?
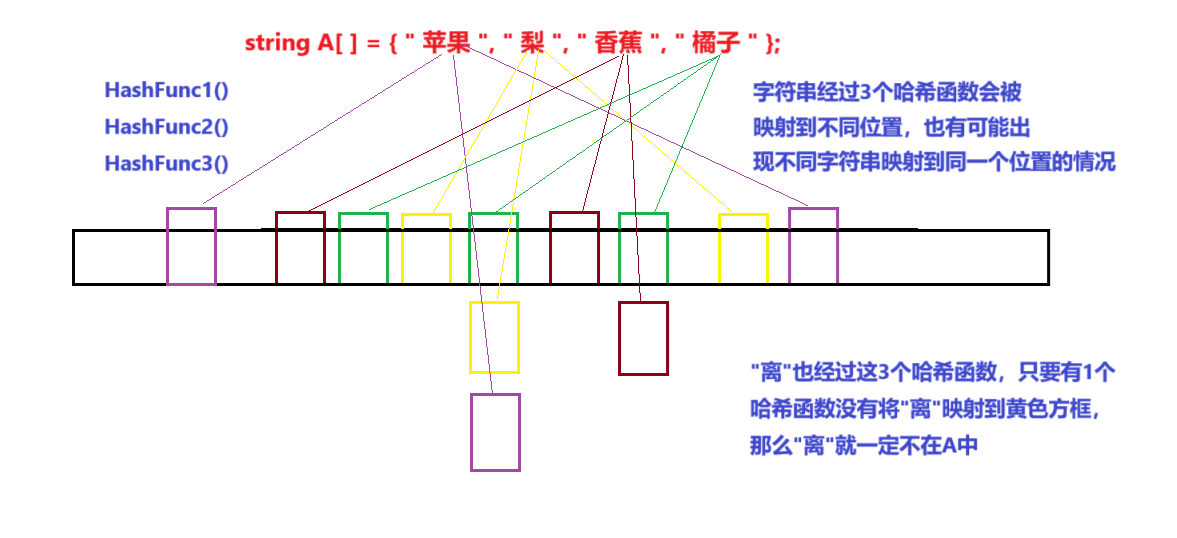
例如:string A[]={"苹果","梨","香蕉","橘子"};,判断"梨"是否在A里?
对于这个问题,其实很简单呀,我们已经学过哈希表了,在C++入门17——哈希之哈希表详解中,对于字符串类型的数据,我们特地封装了一个仿函数来专门处理字符串类型的数据,在这里也是同样的道理呀!先将字符串类型转为整型,再将整型映射到位图结构中,从而实现了查找a是否在A中。
没错,这样的思路是对的,采用哈希+位图的方法正是我们要讲的布隆过滤器。
可问题来了:承接以上的A,我问你"离"是否在A里?"梨"与"离"由字符串类型转为整型似乎并没有太大区别呀!这必然会导致一个问题:不同的字符串有可能会被映射到同一个位置上,那么此时采用上述算法有可能会返回"离"在A中的的结果!
也就是说:采用上述算法得出“不在”的结果一定为真,得出“在”的结果可能为真!
既然得出“不在”的结果一定为真,那我可以采用多个不同的哈希函数将A中的字符串映射到位图的多个不同位置,然后将a也经过这多个哈希函数映射到位图的多个不同位置,只要有1个位置匹配不上,那么a就一定不在A中。(也可以理解为,用一个哈希函数得到的布隆过滤器漏网大,用多个哈希函数得到的布隆过滤器漏网小,并且哈希函数越多漏网就越小)
如图:
经过此番了解,终于要介绍布隆过滤的概念了。
2.1布隆过滤器的概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
也就是说,得出“不存在”的结果不会误判,得出“存在”的结果会有误判,如何降低误判率也是我们需要了解的内容,具体请参考大佬的文章详解布隆过滤器的原理,使用场景和注意事项 - 知乎。
据这篇文章的公式:
如果我们的k=3,可以大致算出m和n满足这样的关系:m≈4.3n,为了方便,我们不妨直接令m=5n。
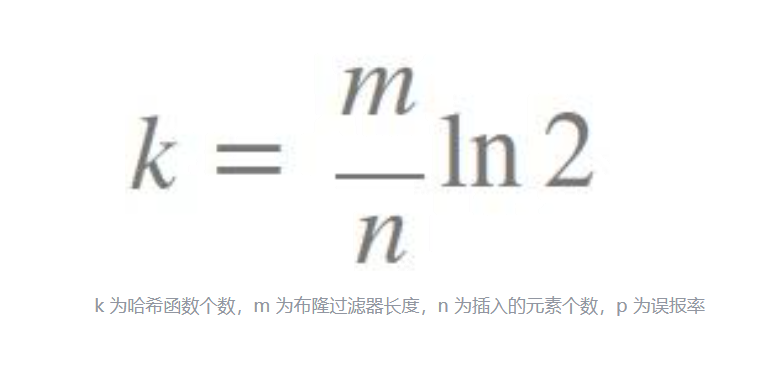
这里我们就暂且设置3个哈希函数,关于字符串的哈希算法,可以参考大佬的文章字符串哈希函数,我们从中CV三个:
struct HashFuncBKDR
{
// BKDR
size_t operator()(const string& s)
{
size_t hash = 0;
for (auto ch : s)
{
hash *= 131;
hash += ch;
}
return hash;
}
};
struct HashFuncAP
{
// AP
size_t operator()(const string& s)
{
size_t hash = 0;
for (size_t i = 0; i < s.size(); i++)
{
if ((i & 1) == 0) // 偶数位字符
{
hash ^= ((hash << 7) ^ (s[i]) ^ (hash >> 3));
}
else // 奇数位字符
{
hash ^= (~((hash << 11) ^ (s[i]) ^ (hash >> 5)));
}
}
return hash;
}
};
struct HashFuncDJB
{
// DJB
size_t operator()(const string& s)
{
size_t hash = 5381;
for (auto ch : s)
{
hash = hash * 33 ^ ch;
}
return hash;
}
};2.2 布隆过滤器的实现
那么布隆过滤器的实现为:
template <size_t N,
class K=string,
class Hash1= HashFuncBKDR,
class Hash2= HashFuncAP,
class Hash3= HashFuncDJB>
class BloomFilter
{
public:
//插入
void Set(const K& key)
{
size_t hash1 = Hash1()(key) % M;
size_t hash2 = Hash2()(key) % M;
size_t hash3 = Hash3()(key) % M;
_bs->set(hash1);
_bs->set(hash2);
_bs->set(hash3);
}
//查找
bool Test(const K& key)
{
//key经过3个函数,只要有一个不在就返回false
size_t hash1 = Hash1()(key) % M;
if (_bs->test(hash1) == false)
{
return false;
}
size_t hash2 = Hash2()(key) % M;
if (_bs->test(hash2) == false)
{
return false;
}
size_t hash3 = Hash3()(key) % M;
if (_bs->test(hash3) == false)
{
return false;
}
return true;//即使返回true也有可能误判
}
private:
static const size_t M = 5 * N;
bitset<M>* _bs = new bitset<M>;
};测试:
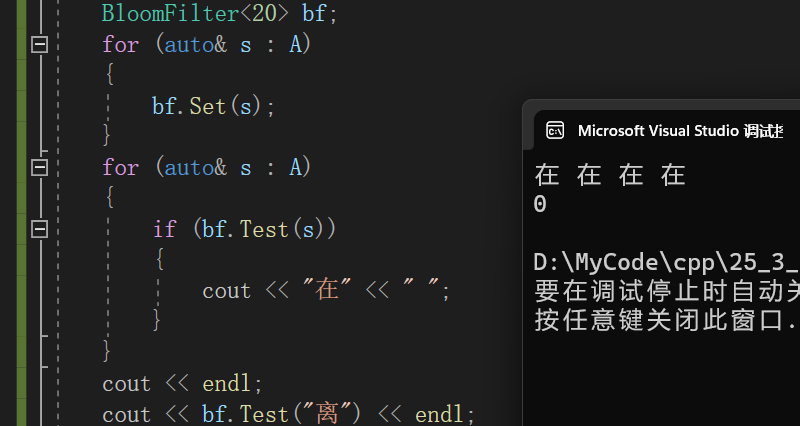
void func4()
{
string A[] = { "苹果","梨","香蕉","橘子" };
BloomFilter<20> bf;
for (auto& s : A)
{
bf.Set(s);
}
for (auto& s : A)
{
if (bf.Test(s))
{
cout << "在" << " ";
}
}
cout << endl;
cout << bf.Test("离") << endl;
}
2.3 验证误判率
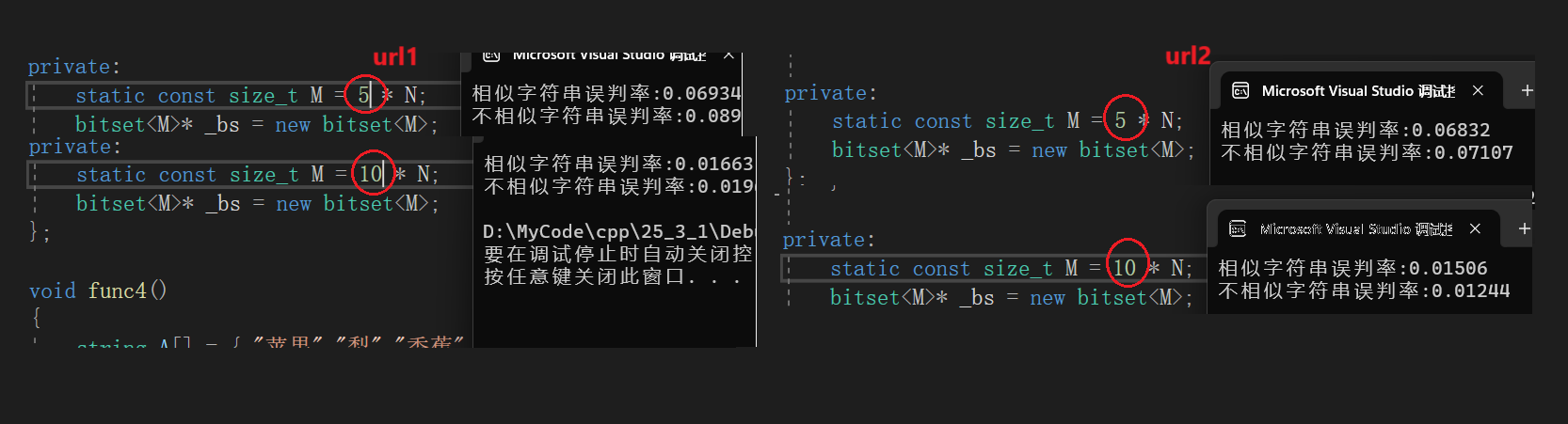
上一段代码验证m=5n与m=10n时和相似字符串与不相似字符串的误判率:
void func5()
{
srand(time(0));
const size_t N = 100000;
BloomFilter<N> bf;
std::vector<std::string> v1;
std::string url = "https://blog.youkuaiyun.com/weixin_73629886?spm=1000.2115.3001.5343";
//std::string url = "徐霞客";
for (size_t i = 0; i < N; ++i)
{
v1.push_back(url + std::to_string(i));
}
for (auto& str : v1)
{
bf.Set(str);
}
// v2跟v1是相似字符串集(前缀一样),但是后缀不一样
std::vector<std::string> v2;
for (size_t i = 0; i < N; ++i)
{
std::string urlstr = url;
urlstr += std::to_string(9999999 + i);
v2.push_back(urlstr);
}
size_t n2 = 0;
for (auto& str : v2)
{
if (bf.Test(str)) // 误判
{
++n2;
}
}
cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;
// 不相似字符串集 前缀后缀都不一样
std::vector<std::string> v3;
for (size_t i = 0; i < N; ++i)
{
//string url = "zhihu.com";
string url = "孙悟空";
url += std::to_string(i + rand());
v3.push_back(url);
}
size_t n3 = 0;
for (auto& str : v3)
{
if (bf.Test(str))
{
++n3;
}
}
cout << "不相似字符串误判率:" << (double)n3 / (double)N << endl;
}结果如图:

















 1069
1069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









