







前言
这篇文章是ICLR2022的作品,where2act的续作,通讯作者是斯坦福大牛Leonidas Guibas与北大的董豪老师,目前引用数89。关于前作where2act,请参考我之前的论文精读,和本工作息息相关。
- 论文地址:https://arxiv.org/abs/2106.14440
- 项目主页:https://hyperplane-lab.github.io/vat-mart/
- 代码地址:https://github.com/warshallrho/VAT-Mart
上一篇文章where2act中指出无法生成动作执行轨迹的问题,在这篇文章得到了解决,同期的UMPNet也是着手解决这一问题。同时本工作使用强化学习进行了更高效率的数据采样。
核心方法
where2act的核心贡献是利用可操作视觉表征(actionable representation)来给定末端执行器的作用点与初始的位姿。但是没有给定动作轨迹。关于where2act的部分本文不再详细赘述。
生成轨迹,关键在于如何将动作参数化,本文采取了一种简单的方式,把where2act中生成的一个位姿,改为了轨迹上多个点的位姿,这样就能连续执行动作了。可以参考下图的轨迹:
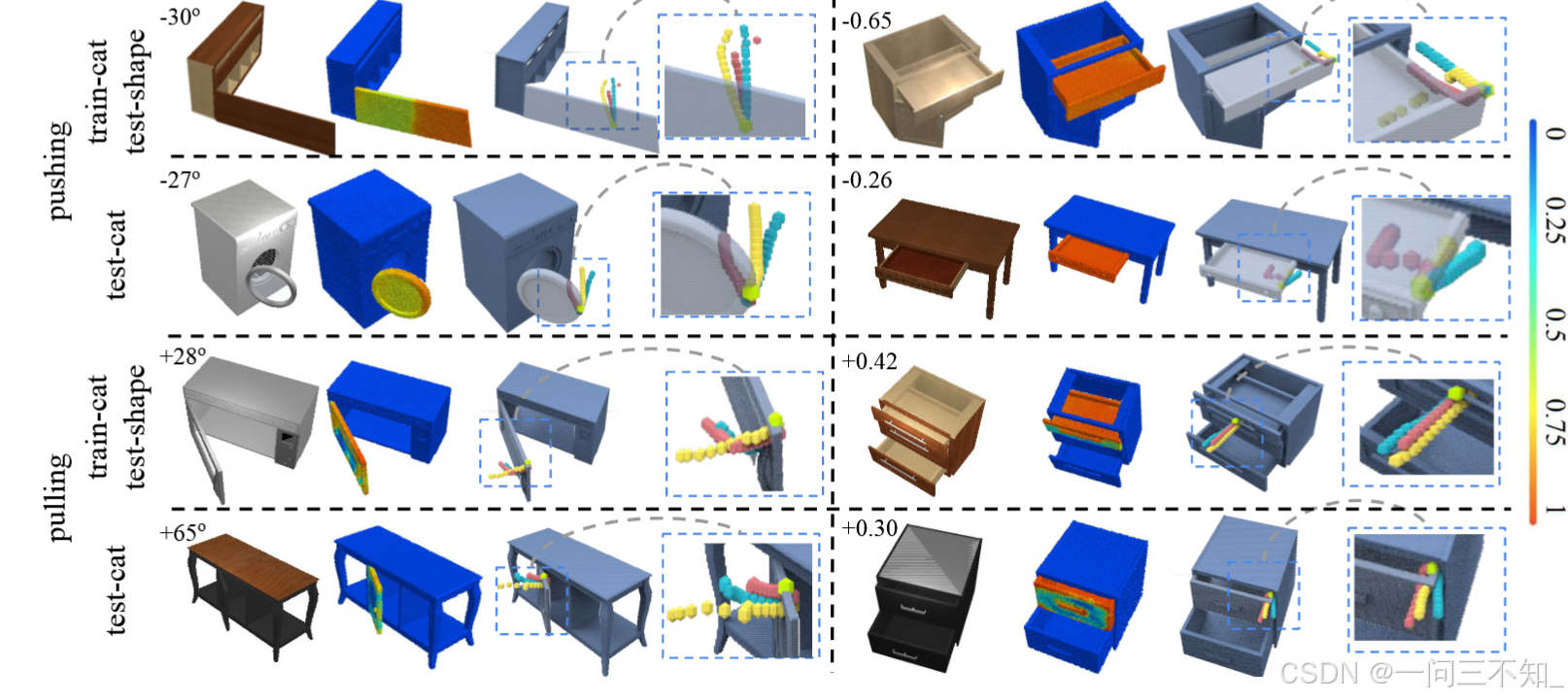
本文的另一个创新点是指定了任务,而不是仅仅给定动作,例如:将微波炉的门打开30度。作者采用简单的条件:假定铰接物体的关节只有一个自由度:旋转或平移,把旋转关节的旋转角度或平移关节的平移距离作为模型的条件输入。
为了高效采样数据,以供监督训练,作者使用了强化学习的技巧。
作者提出的贡献如下:
- 我们制定了一种新颖的可操作视觉先验,朝着弥合操纵 3D 铰接对象的感知交互差距又迈进了一步
- 我们提出了一个交互感知框架 VAT-MART 来学习这种先验,并在探索性 RL 和感知网络之间的联合学习中采用新颖的设计
- 在 SAPIEN 中对 PartNet-Mobility 数据集进行的实验表明,我们的系统在大规模上工作,并学习在看不见的测试形状、对象类别甚至真实世界数据上泛化的表示。
前人的工作
以往的工作往往聚焦于抽象的运动学结构(abstract kinematic structure),例如估计的关节参数和部件姿势(part pose)来作为视觉表征。
机器人操作任务的基本几何和语义特征,例如交互热点(例如边缘、孔、条)和零件功能(例如把手、门),在这些规范表示中被无意中抽象出来。
几何感知、交互感知和任务感知
术语
w2a:where2act论文的简称
部分点云(partial point cloud):从一个视角看过去的点云,并没有完整的物体表面信息。类似于RGB-D图像
handshaking point/contact point:接触点,指末端执行器与物体表面接触的位置。
waypoint(wp):路径(轨迹)点,指执行器接触物体表面后,持续作用的轨迹。
方法
动机
能不能执行open a door for 30◦, close up a drawer by 0.1unit-length这种类型的任务?而不是仅仅给定一个动作,让模型执行。
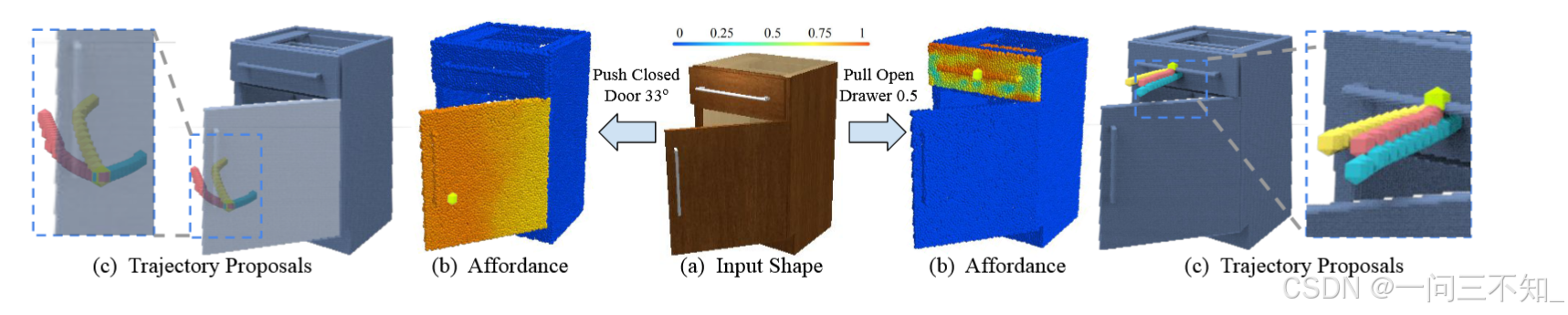
遵循where2act的设定,作者力图提供以下的affordance信息:
- an actionability map,对应 where,其实就是w2a中铰接物体表面逐点(pointwise)的可操作性分数。
- 行动轨迹提议(trajectory proposals),对应how。这和w2a中不同
- 成功概率分数,用来评估前两个信息是否有效。尤其因为第二条行动轨迹提议是生成式模型,生成的很多动作都是无效的。而且对其进行评分是一个简单的二分类任务,更容易取得好的训练效果
所有预测都是有交互条件的(interaction-conditioned),即给定任务:将门推动30度,预测相应的动作。
本文只考虑一自由度的关节运动,平移(例如抽屉)参数为标准化后的相对距离
θ
∈
[
−
1
,
1
]
\theta\in[-1,1]
θ∈[−1,1],旋转(例如冰箱门)参数为
θ
∈
[
−
π
,
π
]
\theta\in[-\pi,\pi]
θ∈[−π,π]
问题描述
输入:
- 物体O,带有铰接部位P={P1,P2,…}
- 动作类型T,论文只考虑push和pull
- 操作任务 θ \theta θ,论文只考虑一自由度的运动,给出运动参数
输出:
- 逐点的可操作性分数(actionability score) a p ∣ O , T , θ a_{p|O,T,θ} ap∣O,T,θ,对每一个点产生100个动作提议,计算Loss的时候只对评分top5的动作提议做loss。这是对w2a的改进,后者使用的是所有动作提议分数的平均,但是和测试阶段不匹配。
- 末端执行器的轨迹: ( w p 0 , w p 1 − w p 0 , ⋅ ⋅ ⋅ , w p k − w p k − 1 ) (wp_0, wp_1 −wp_0, · · · , wp_k −wp_{k−1}) (wp0,wp1−wp0,⋅⋅⋅,wpk−wpk−1),wp表示位姿,可变长。使用减法是因为作者发现以残差(也就是每步移动的距离)的形式来表示更容易训练。
- 轨迹成功概率
r
τ
∣
O
,
p
,
T
,
θ
r_{τ|O,p,T,θ}
rτ∣O,p,T,θ,对于上一条的结果输出一个成功概率,进行评估
( w p 0 , w p 1 , ⋅ ⋅ ⋅ , w p k ) (wp_0, wp_1, · · · , wp_k) (wp0,wp1,⋅⋅⋅,wpk)。
细节:对于wp0,使用6-D旋转表示,之后的使用3-DoF欧拉角表示orientation
神经网络架构如下图:左边是RL用来收集数据,右边是感知的模块。
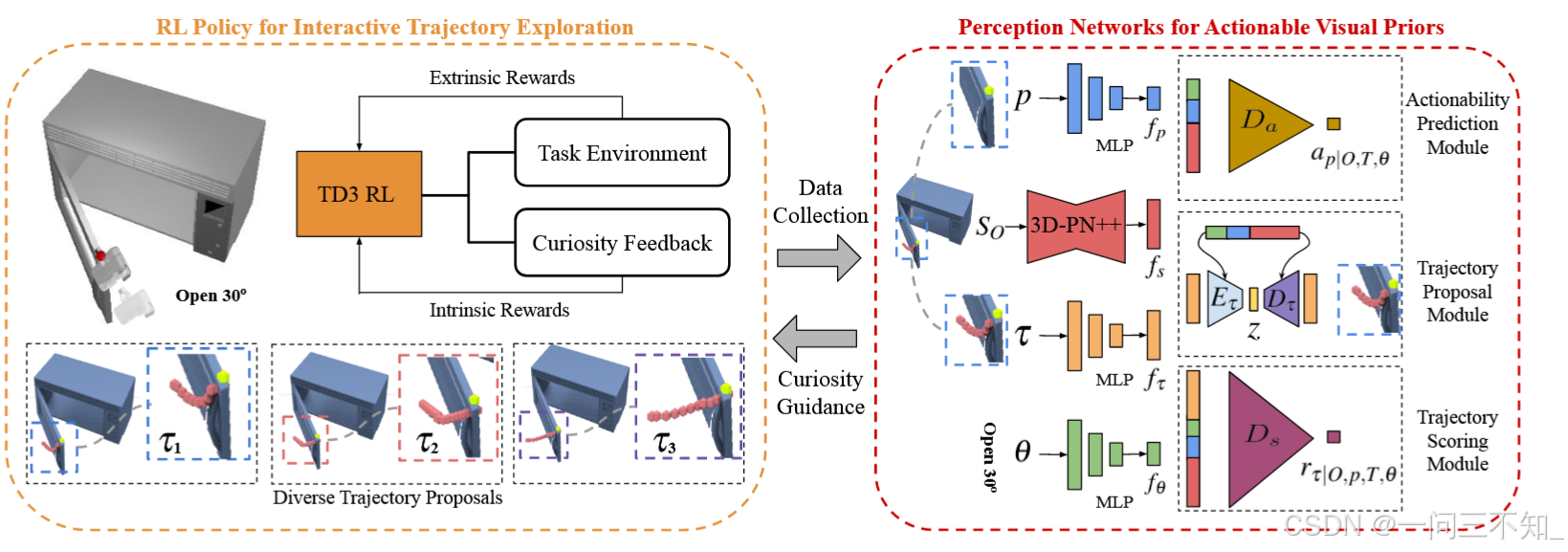
训练方法
分为三阶段:
- 预训练RL的探索性的交互策略
- 使用RL收集的数据训练感知神经网络
- 共同优化两个网络(使用好奇心反馈curiosity-feedback)
RL探索&收集数据
任务初始化
作者选取了适当的初始条件,保证更容易交互到合适的位置
算法:
使用了TD3的强化学习算法,预训练一个交互的策略,增强了成功交互的比例,大大减少了无效互动的时间。使用好奇心驱动(Curiosity-driven Exploration)的方法,鼓励进行更充分的探索。并且使用了Hindsight Experience Replay技巧增强数据利用率。参见下面的链接:
如何评价Curiosity-driven Exploration? 知乎
强化学习 Reinforcement Learning(六)——好奇心驱动的强化学习
【强化学习算法 34】HER Hindsight Experience Replay 知乎
state&action:预训练的RL是具有产生交互策略、执行任务(action)能力的,但是接收了超级多额外的信息输入(state)(从仿真器中获取准确值),难以部署到实际中,因此只能在仿真器中用来高效采样。
reward:需要逐步的给与RL奖励引导,使其向目标位置移动,否则无法保证中间的步骤是有效的,二元奖励太过于稀疏。
监督训练阶段:使用RL给出的正样本,并且对正样本加入(对于旋转关节是 [ 0.1 θ 0 , 45 ◦ ] [0.1θ_0, 45◦] [0.1θ0,45◦])噪声进行随机扰动得到负样本。
测试阶段
抛弃RL网络。
1)使用affordance map模块得到评分最大的点
2)在该位置生成多个轨迹
3)交给最后的评分模块,取最大值
实验
选取了三种baseline
(1) 端到端的强化学习,输入点云图,直接输出轨迹
(2) 启发式方法,手动制定的规则,例如:要拉开抽屉,先抓住把手并直接向后拉
(3) 多步骤的Where2act,需要额外的Oracle Part 姿势跟踪器(pose tracker),来确定目标物体的位姿
问题:为什么需要pose tracker?
答:因为我们给出了任务要求,例如:将门旋转30度,但是多次执行Where2act时,是不知道之前已经转了多少度的。所以要已知目标物体转了多少度,并根据是超出还是不足来选择动作Push或pull。
结果分析
端到端manipulation的强化学习效果很差,意味着中间通过监督学到的视觉表征是必要的:affordance map和最后的动作评分模块。
启发式方法在这几个方面表现不好:
1) 没有用于拉动的手柄部件
2) 一些对复杂手柄几何形状的抓握可能会打滑和失效
3) 非抓握操纵(推)的运动动力学(例如,惯性)会影响任务的准确完成
where2act多步骤生成轨迹非常耗时,而且需要额外的Oracle Part 姿势跟踪器。
配置
- 只考虑推、拉两种动作
- 只考虑1-DoF的铰接物体
- Panda flying gripper
- SAPIEN, PartNet-Mobility dataset
- velocity-based PID-controller
- RGB-D camera
总结
和UMPNet的对比
数据收集阶段:VAT-MART给定了任务(也就是RL的reward引导):移动多少角度/距离,所以有明确的方向,不存在back and forth的问题,也就不需要UMPNet中的时间箭头
神经网络输出:
输出下一个点的坐标和方向,比UMPNet多了坐标。UMPNet仅仅是在下一个预测的方向上执行一段动作,移动距离是预定义好的0.18m。相比较而言VAT-MART更有灵活性
优点:
UMPNet是闭环反馈的,每执行一次动作,就停下来接收视觉输入,再次决策。
缺点:
UMPNet使用吸盘作为末端执行器,无法泛化到其他end-effector
UMPNet没有显式给定任务
问题
- 什么时候停止产生动作轨迹提议?
答:训练的时候设置了轨迹长度的上限。而且训练数据中的轨迹都是有限长度的。 - 模型会不会尽量产生一步到位的轨迹?
答:不会,因为训练集不是这样的
limitation
(1)一次生成一连串轨迹,不是闭环的,无法根据情况后续调整之前的决策。UMPNet是每次只给出下一个路径点,执行动作之后根据当前视角再进行一次决策
(2)动作类型太少了
(3)对铰接物体的关节有要求:1-DoF,只能实现推开门30度之类的任务
(4)要求场景中只有一个物体,或者提供该物体的mask。否则给定任务的角度/距离描述,模型不知道该作用于哪一个物体。
参考
这篇文章已经总结的很详尽,所以我尽量从一个简单的视角来写
【计算机图形学】VAT-MART:Learning Visual Action Trajectory Proposals for Manipulating 3D Articulated Objects
VAT-MART 、AdaAfford论文阅读总结


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









