







前言
这篇是CVPR 2023年末的工作,通讯作者是北大的董豪老师,利用MLLM来进行low-level的manipulation动作执行
- 论文地址:https://arxiv.org/abs/2312.16217
- 代码地址:https://github.com/clorislili/ManipLLM
核心思想
机器人操作(manipulation)依赖于准确预测接触点(contact point)和执行器方向以确保成功,这二者分别对应where和how to act。
以往使用MLLM的工作关注high-level的任务规划,例如SayCan,Voxposer,但使用MLLM直接预测low-level的操作方式存在挑战,主要是因为训练数据的缺乏,而且用文本来表示如何执行动作也有困难。
操作物体需要理解物体的物理、几何结构(例如轴的位置,关节参数),来确定操作点。而正好MLLM对物体的属性具有充分了解,可以利用它的知识。
作者认为where2act,Flowbot3d,Voxposer,RT2把low-level的manipulation当作一个黑箱,不可解释,本文尝试利用LLM的能力,使用自然语言让推理过程变得可解释。
核心问题是:给定一张图,一个任务,如何让MLLM预测end-effector的作用于物体时的位姿?
存在的困难是:
- MLLM使用自然语言,使用什么样的形式将其转化为对动作的描述?
- 如何使MLLM获得这些能力?这需要高效收集数据,进行监督训练。
基于MLLM:LlaMA-Adapter,使用了四个微调任务:
- 目标物体分类(object category identification)
- 逐像素的affordance评分(affordance prior reasoning):对应于where to act,接触点是什么?
- 预测gripper位姿(manipulation-aware pose prediction):对应where和how
- mask版本的预测gripper位姿:用来辅助上一个任务
推理时,作者还使用了三个trick来增强表现:
- impedance adaptation,一种执行Manipulation的策略
- CoT:增强MLLM的推理能力
- TTA:测试时训练,用来sim2real
最后输入一张2D-RGB图片,MLLM预测gripper的位(2D)姿(3D)。使用深度图进行位置的2D-3D转换,并使用了上述3个trick来执行最终的操作。
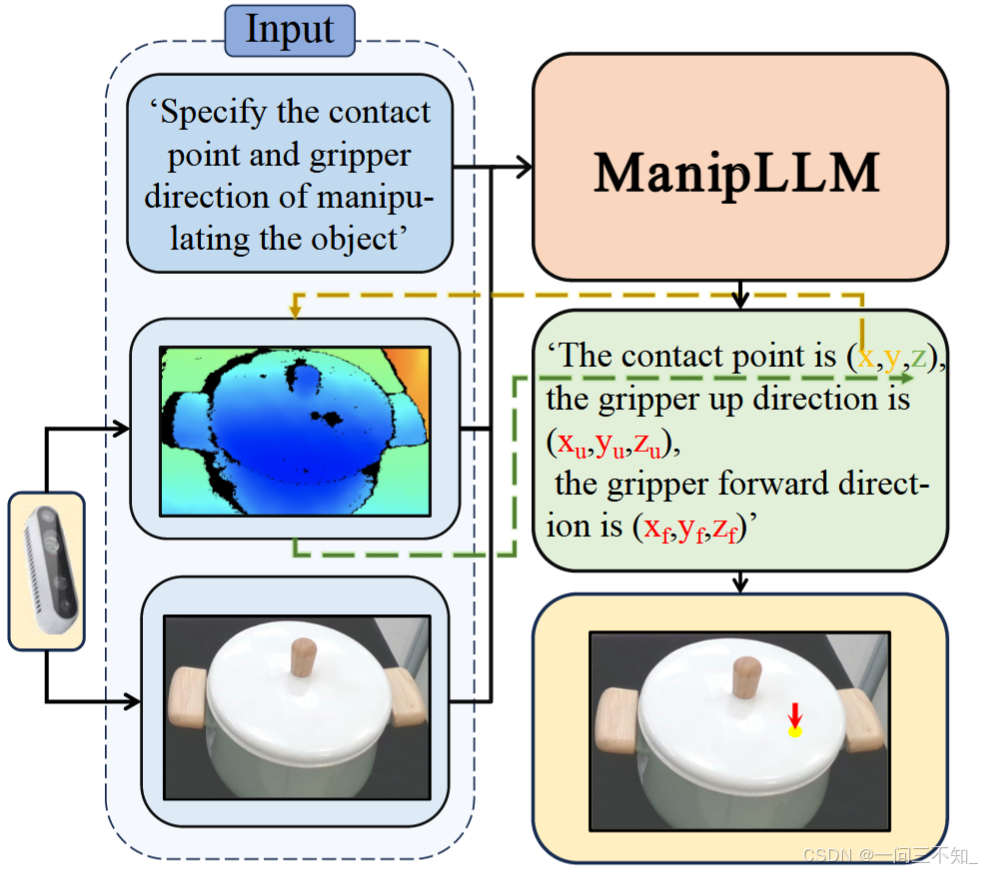
作者提出的贡献如下:
- 我们创新性地提出了一种简单而有效的方法,将 MLLM 的能力转化为以对象为中心的机器人操作(manipulation)。
- 我们设计了一个思维链微调和推理策略,利用 MLLM 的推理能力来实现稳健且可解释的末端执行器姿态预测。
- 跨广泛类别的实验证明了 ManipLLM 的泛化能力。
训练阶段
选用MLLM模型:LLaMA-Adapter
(这是一篇改进LLaMA的工作。注意LLaMA3是没有视觉输入的,需要使用CLIP预先提取视觉特征,与文本一起输入。从而将LLM改造成MLLM)
输入:
- 文本:文本prompt,首先经过LlaMa的分词器(tokenizer)处理(可能是类似BPE分词的工具)
- 视觉:包含目标物体的图片,首先经过CLIP视觉特征提取器处理,得到图片的embedding
为了尽可能保留预训练的强大效果,只微调LlaMa和CLIP中的injected adapters,如下图所示,雪花符号表示冻结参数:
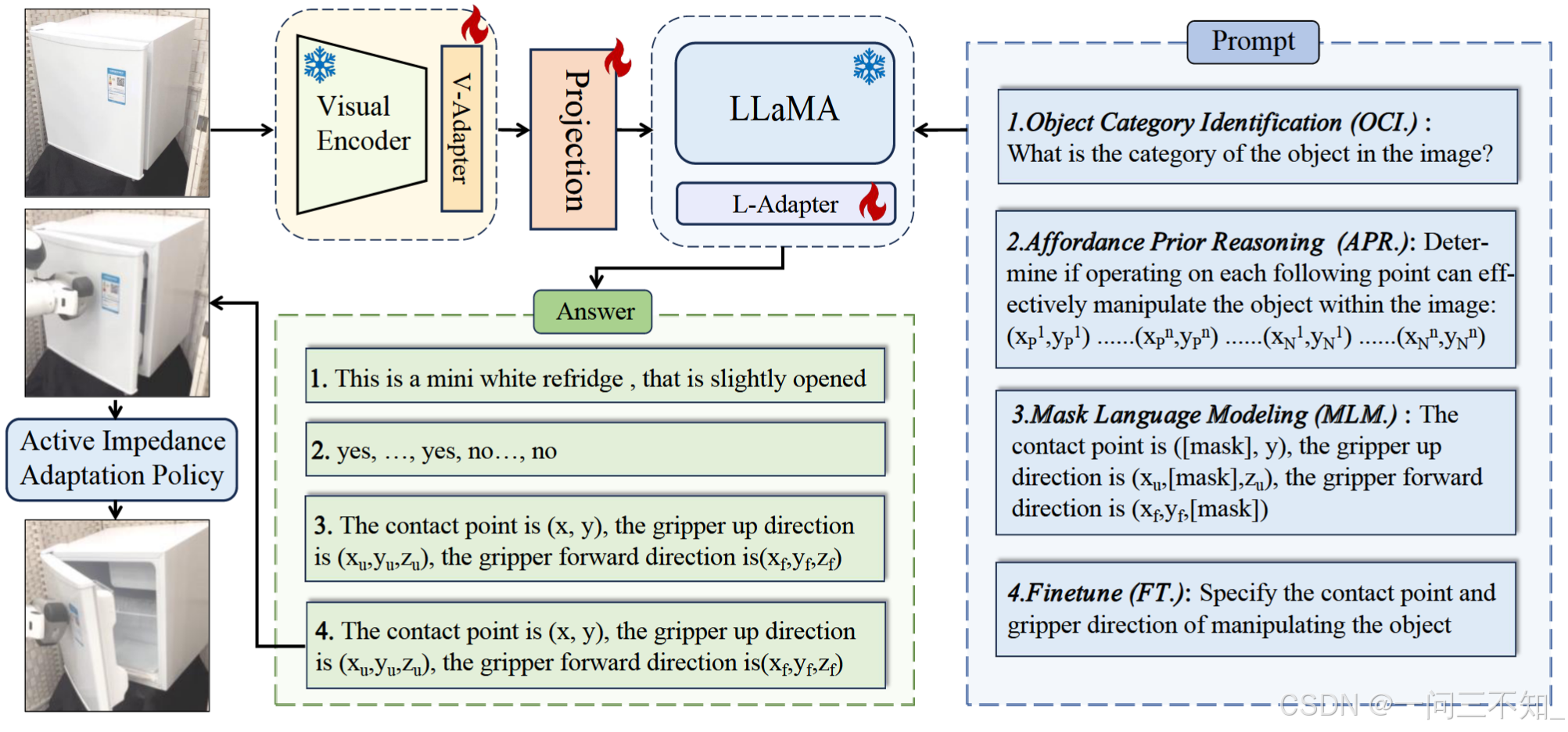
像Bert等大语言模型一样,作者提出了四种训练阶段微调的任务,参见上图的prompt和answer,我们下面来细致了解一下:
目标种类识别(OCI)
因为仿真环境中的物体种类远远少于大模型预训练阶段,MLLM已经拥有了强大的目标类别识别能力,微调反而对它的能力有害。所以本阶段不做微调,得到的结果为后面的微调任务提供信息。
Affordance 先验推理(Prior Reasoning) (APR)
这个阶段旨在使模型了解哪些物体表面区域可以被操作,对应于where to act。
获取GT label:对输入的图片逐像素(per-pixel)处理得到affordance map,每个点计算一个affordance分数
A
A
A,因为是0-1之间,称之为概率分数。
受Flowbot3D启发,作者把关节分为“平移”和“旋转”分别处理:
(1)平移关节能移动的部位的分数
A
A
A都是1,因为无论哪一个点的施力效果都相同;而且都是有效的,能让物体移动。
(2)旋转关节的分数由以下公式给出。对于所有沿着旋转轴的可移动部分,给定一个小旋转角度
d
θ
d\theta
dθ,计算每个点前后的距离差D,从而得出affordance分数
A
A
A
A
=
D
∣
m
a
x
(
D
)
−
m
i
n
(
D
)
∣
A= \frac{D} {|max(D) − min(D)|}
A=∣max(D)−min(D)∣D
这里类似杠杆原理、齿轮驱动原理。当旋转角度相同,点与转轴距离不同的时候,会移动不同的距离,越靠近转轴,越接近静止,力的作用效果越差。这也符合我们的日常经验:门把手都是在最原理远离门轴的位置。下图中红色表示分数高: 由于我们使用SAPIEN仿真器,这些GT都能在仿真阶段从编程信息中获取,并通过计算机图形学的知识把三维点映射到二维的像素平面。此时需要vision2language的转换,因为MLLM只能用语言来表达视觉信息,我们给定一系列像素坐标,让模型“说出”该点的affordance分数。
由于我们使用SAPIEN仿真器,这些GT都能在仿真阶段从编程信息中获取,并通过计算机图形学的知识把三维点映射到二维的像素平面。此时需要vision2language的转换,因为MLLM只能用语言来表达视觉信息,我们给定一系列像素坐标,让模型“说出”该点的affordance分数。
由于让模型逐个像素预测太过昂贵;而且很多像素的affordance score都是模棱两可的,不便让模型学习,因此,我们采样分数接近0或1的像素点。选取affordance score>0.8和<0.2的分别作为正负样本,让模型具有足够高的置信度,不会出现模棱两可的情况,负样本中包含根本无法移动的部分,和很难移动的部分。
prompt如下,给定一系列点的坐标:

输出:yes or no,这是一个二分类问题,可以使用二分类的交叉熵损失
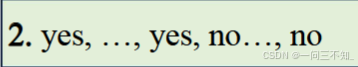
问题:模型对图片像素的定位能力很差;不同图片像素数量不一样,文中没有对坐标进行归一化;大模型对小数点的掌握能力有限(本工作没使用小数点)
微调(FT.) 和 Mask Language Modeling (MLM.)
这一阶段意图预测末端执行器操作物体的位姿:接触点坐标和方向。对应于where to act和how to act(注意上一个任务中模型了预测where to act)
作者采样得到了一系列成功的操作数据对:(图片,执行器位姿)。给定RGB图片,让模型直接预测位姿。(姿态用两个方向向量表示,分别是执行器up和forward的方向)
因为在affordance map上进行过训练,模型预测位置的能力较强,可以使用回归的损失。但预测姿态是一个回归任务,非常困难,毕竟人类也很难准确给出这些数字。于是作者将其转换为分类任务:将方向向量先normlize之后,离散化到100个bin中。使用交叉熵计算分类损失。
但作者发现直接微调模型预测位姿不太准确。为了便于训练,使用MLM任务,将输入prompt中的接触点坐标或方向向量的值进行mask,让模型预测被mask的字符,如下图所示。损失函数和上面的设置一样。

问题:gripper direction是三维的,但图片是二维的,(1)如何从像素中估计世界坐标系的三维向量方向?(2)模型怎么知道世界坐标系是怎么建立的?
答:(1)好像非常困难,需要对物体的形状有充分认知。(2)世界坐标系很可能是和相机坐标系一样的,相机坐标系是已知的。
训练总览
每一轮训练都是上面四个任务的连续执行(存疑),这样,前几个任务的信息(尤其是第一个任务)能传到后面的阶段。最后的loss是上面四个任务的loss相加。
微调之后,模型具有预测可操作点/接触点的像素坐标 ( x , y ) (x, y) (x,y) 、执行器向上方向 ( x u , y u , z u ) (x_u, y_u, z_u) (xu,yu,zu) 和执行器向前方向 ( x f , y f , z f ) (x_f, y_f, z_f) (xf,yf,zf)的能力。作者利用深度图(depth map) D H × W D^{H×W} DH×W 将接触点投影到 3D 操作空间 ( x , y , z ) (x, y, z) (x,y,z) 中。把这三个信息提供给下游的manipulation任务。
问题:为什么要用第一个任务帮助之后的理解?加快收敛吗?
数据采集
在铰接物体可移动的部分随机采样接触点,在该点的法向向量(垂直表面)相反方向施加作用力,选取成功的案例,得到“微调(FT.) 和 Mask Language Modeling (MLM.)”阶段的训练数据。
为了监督学习,我们只选择成功的案例,所以需要高效率的进行成功的探索。
问题:只选择法向方向,数据采集效率高,而且符合实际情况;但探索不够充分。
执行manipulation
有了contact point, direction,也就是执行器的目标位姿;我们接下来不用考虑怎么移动到那里去,如何生成到目标作用点的移动轨迹,这已经有成熟的解决方案。
我们要考虑的是如何持续的作用在目标作用点上,得到waypoints,毕竟推门的时候并不是只推一瞬间,而是力的持续作用,与此同时作用点的三维坐标也在不断变化。
作者使用Active Impedance Adaptation Policy策略,具有启发式和闭环的特点,基于阻抗力反馈(impedance force feedback)动态的生成轨迹。原文公式太复杂,这里用通俗的语言解释一下:
1)从起始(物体表面的)作用点出发,对于初始时刻,预测一个最优的力的作用方向(我们的MLLM已经有这个能力了)。
2)对这个方向多次添加随机微小扰动,得到不同的方向
3)在这些不同方向上分别施加微小的力,接触点发生不同大小的位移距离
4)位移最明显的方向就是力的最优方向。这一点类似于我们获取affordance score时的依据。
闭环的意思是:之后的时间步可以修正之前的策略
问题:这个策略会不会执行的特别慢,因为要采样,并逐一尝试?
测试阶段
使用CoT,为推理添加了许多辅助的信息,增强模型的表现。
MLLM输入:
- 一张RGB图像,包含物体(自始至终只有一张图)
- 文本prompt,多轮对话如下图
最后输出:
- 接触点(contact point)的2D像素坐标
- 末端执行器(end-effector)的3D方向
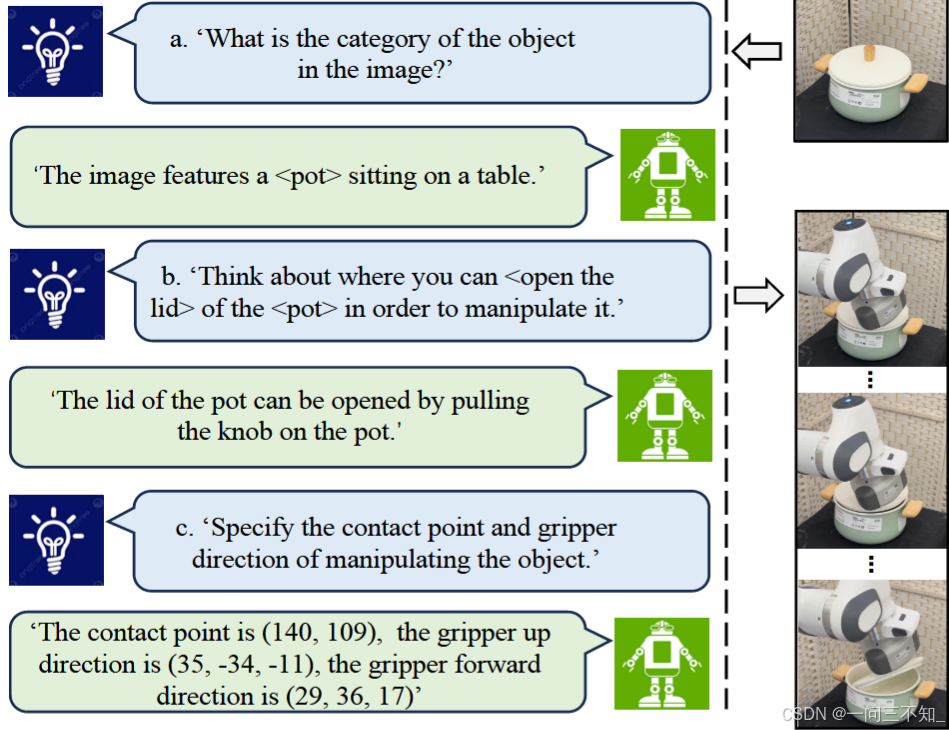
最后,根据gripper的目标位姿,使用阻抗力反馈(impedance force feedback)来执行manipulation。
sim2real
为了弭平sim2real的gap,作者使用了最近很火的测试时自适应(Test-Time Adaptation ,TTA):推理过程中根据测试样例微调模型参数。LLaMA的能力已经很强了,那么微调什么部分的参数呢?
作者发现姿态预测虽然可能会不可靠,但是可以通过闭环的阻抗力反馈来修正结果;只有位置预测比较不可靠,受到光照和纹理的影响。因此只更新LLaMA-Adapter中负责视觉信息的V-Adapter来增强结果。
- 那么如何微调?label如何设置?
作者引入额外的推理步骤来提示模型判断是否预测的位置可以成功进行操纵,这一步的text prompt和训练过程中的“Affordance Prior Reasoning”一致。
实践中先询问模型:物体该点是否是可以操纵的?模型回答yes or no。GT label是现实中的物体是否被成功操纵,根据label来更新参数。
实验
metric
metric是成功率
怎么算作成功?答:设置一个移动距离的阈值,得到0 or 1的二元结果。由于本论文中的移动都是1-DoF的,所以只要看平移的距离变化或者旋转角度的变化就好。
作者区分了initial movement和long distance movement,并为它们设置了不同阈值,二者必须同时大于阈值才算成功。
对比
和Where2Act, UMPNet, Flowbot3D, Implicit3D,VoxPoser比较,
UMPNet没有给出how to act(姿态)的信息,所以选垂直于物体表面的法向方向
作者说其他方法需要可移动的mask,来表示哪里是铰接(articulated)物体,哪里是背景。好像是因为:图片中可能存在多个物体,必须显式指定要移动哪一个物体
配置
- Franka Panda Robot with flying suction gripper
- SAPIEN, PartNet-Mobility
分析
作者针对训练阶段的四个任务和测试的两个trick做了消融实验,结果如下: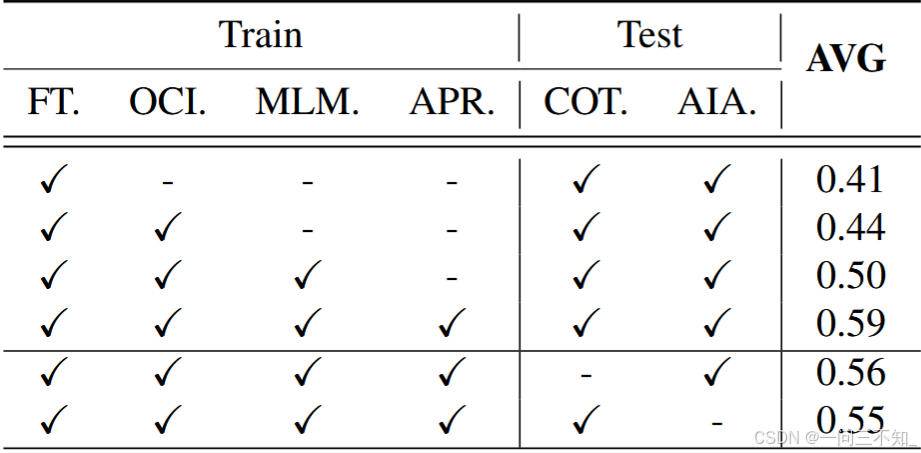
问题
- 动作执行如何变的可解释了?因为CoT?
总结
这篇文章使用MLLM来执行low-level的manipulation执行,预测物体的affordance属性,并进一步给出了where to act和how to act的信息,也就是末端执行器的位姿。微调LLaMA,使其获得了用语言来精准描述如何执行动作的能力。利用了MLLM的预训练知识,具有良好的泛化能力。
优点:
- 利用了大模型的视觉先验知识,泛化性强。而一般的manipulation都是在仿真器内学习的,操纵物体类别有限。
- 可以给定任意任务和动作类型,利用MLLM的先验知识。不用显式的对任务和动作进行建模
limitation
- 对于给定的任务和动作类型,其表现取决于训练数据。微调监督训练时并没有给定任务和动作类型,上面的第二条优点很难发挥出来。
- 只对1-DoF的平移和旋转关节进行建模,因此数据采集的时候只选择法向
- 论文中只使用吸盘,因此数据采集的时候只选择法向
参考
https://blog.youkuaiyun.com/s_m_c/article/details/141187253
https://blog.youkuaiyun.com/passer__jw767/article/details/136821394
https://zhuanlan.zhihu.com/p/685917966
https://www.zhihu.com/question/388619477/answer/3345220400

















 401
401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









