






前言
本文简称shape2prog,是ICLR 2019年的斯坦福团队的一篇工作,通讯作者是有清华“十大学神”之称的吴佳俊(jiajun wu),也是李飞飞的合作者,目前引用量为163。
- 论文地址:https://arxiv.org/abs/1901.02875
- github地址:https://github.com/HobbitLong/shape2prog
核心方法
问题的定义:给定一个三维物体,预测一个程序,来重建该三维物体
这很像自编码器的架构,给定x,要求生成z,z又能重建出x。这里的q(x|z)就是程序执行器,我们需要的是程序生成器p(z|x)。存在两个问题:
(1)一般的程序执行器是不可微的,无法端到端训练。本文使用神经网络来拟合一个程序执行器。
(2)要求latent space必须符合特定的分布。因此不能简单采取一种自监督的方式直接端到端进行训练,还要对latent space进行约束。所以必须要有z的合理数据。
另外,从三维物体反推出生成它的程序,关键在于训练数据的缺失。一般来说我们只能找到复杂三维物体的数据集,生成它们的程序并不被提供。
幸好,我们可以采取一种自监督的方式来获取简单的(物体,程序)数据,进行pretrain。网络两端天然是解耦的,所以可以分别优化。
现在的问题是:求编码器q(z|x)。我们已经有了较为粗糙的编码器q(x|z), 生成器p(z|x),如果固定后者,采取自编码器的方式优化,就可以进行端到端的优化。同时因为只有正确的程序才能被正确的执行重建原物体,这限制了latent space中z的分布必须是合理的范围。
可以看看下图示意效果,还是挺不错的:
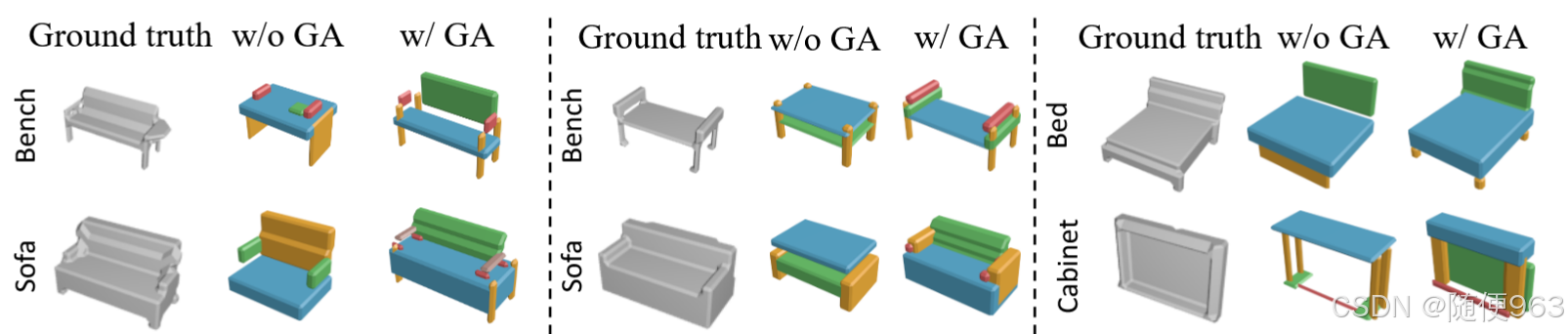
本文的核心创新点是:
- 使用神经网络拟合程序执行器,进行端到端优化
- 把for循环、semantic语句加入到程序代码中,捕获 3D 形状中的高级规则性,例如对称和重复。
作者总结的贡献如下:
- 我们提出了 3D 形状程序:一种基于认知科学和计算机图形学经典发现的新的形状表示形式。
- 我们提出了通过解释输入形状来推断 3D 形状程序,利用神经形状程序执行器(neural shape program executor)。
- 我们证明了推理模型、执行程序和它们重建的程序都在 ShapeNet 上取得了良好的性能,学习解释和重建复杂的形状。我们进一步表明,该模型的扩展可以推断形状程序并直接从图像中重建 3D 形状。
相关工作
- 三维物体生成:CAD等方法,能使用编程的方式生成物体,并提供接口给blender等应用
- Neural Program Interpreters (NPI):使用神经网络强大的拟合能力来模拟程序的执行,例如:排序。递归的方式能增强程序的能力。
- CSGNet:利用一系列几何原语去描述三维物体,属于自底向上的方法
CSGNet与PLAD框架
由于代码程序生成物体的阶段是不可微的,以往的工作都苦于(1)无法端到端的训练(2)没有充足的标注数据,纷纷引入强化学习、伪标签等技巧,利用天然的自监督信号。本文的创新点在于:使用神经网络拟合一个代码解释器,来帮助端到端的训练。
关于这类方法,简单介绍一下:它们的共同点都是先监督预训练
- CSGNet:先监督预训练p(x|z),然后使用强化学习,reward是原物体与重建物体(使用代码解释器执行一下)的ch距离,这样就不需要标签了。
但它的问题是强化学习很难收敛
下面是基于伪标签的方法:训练过程中维护一组重建效果最优的伪标签程序
P
b
e
s
t
P^{best}
Pbest。由于伪标签程序通过被执行能提供重建信息,得到伪标签物体x,所以自动引入了监督机制。这一张图片超级形象:
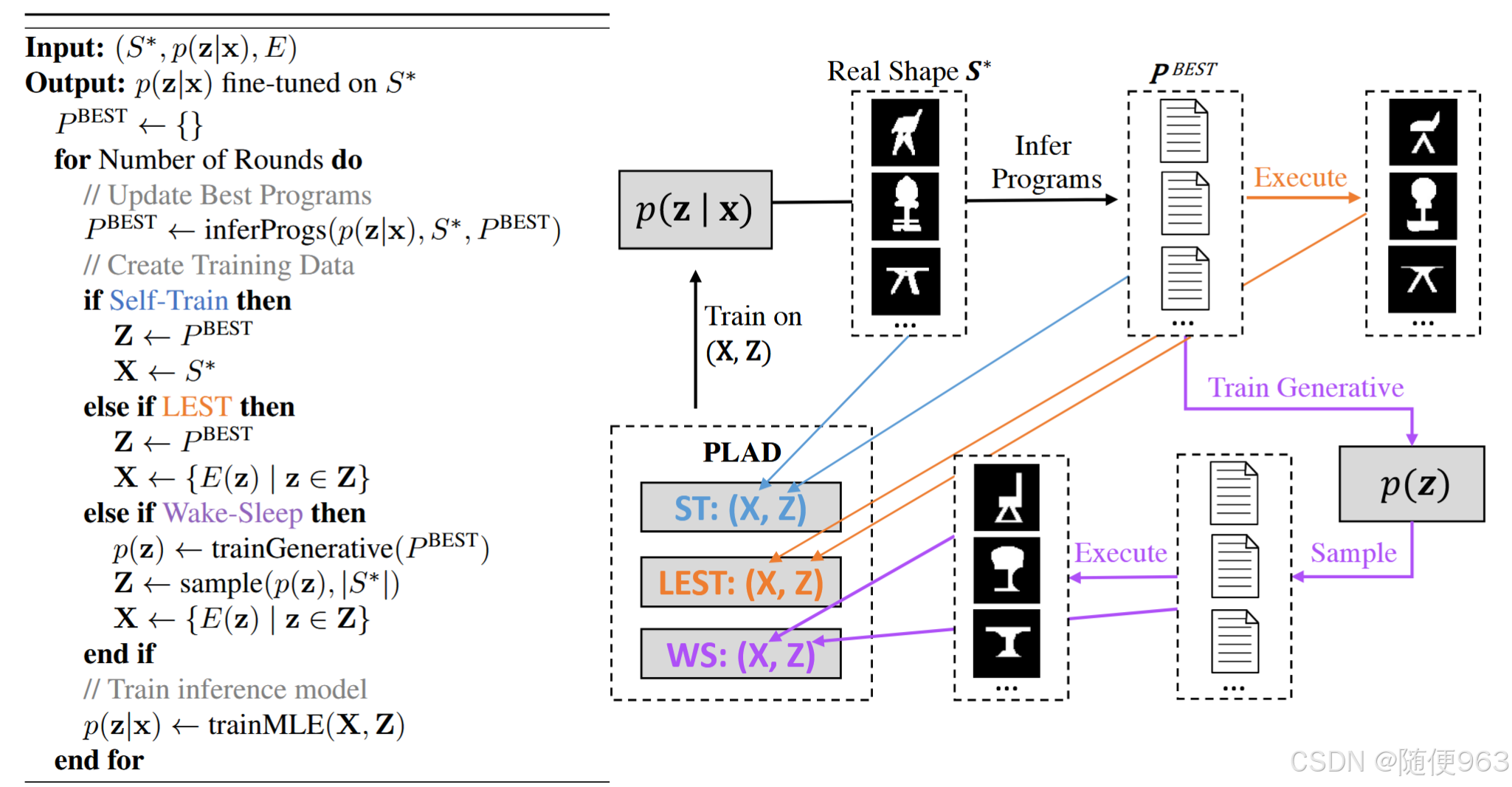
- wake-sleep:训练p(z),生成式的产生程序的模型,生成程序z。执行最优的伪标签程序 P b e s t P^{best} Pbest得到物体x,得到(x, P b e s t P^{best} Pbest)。问题是p(z)未必能拟合z的分布, 伪标签物体x也与实际 S ∗ S^* S∗分布不一样。优点是(x, P b e s t P^{best} Pbest)的对应关系是正确的,而且生成模型能生成无穷的数据。
- Self-Training:使用伪标签程序 P b e s t P^{best} Pbest和相应的真实物体x作为数据对。问题是二者并不对应。优点是物体的分布是真实的。
- LEST:通过执行维护的伪标签程序 P b e s t P^{best} Pbest得到 x = E(z),使用(x,z)进行训练,问题是伪标签x与实际 S ∗ S^* S∗分布不一样,但(x,z)的对应关系是对的。
它们的共同方式都是不停添加基础的基元几何体,然后与已有的几何体进行布尔运算。使用体素表示。
方法
代码设计
作者设计了domain-specific language (DSL)代码去描述三维物体,下面是一段代码示例。代码段分为两种:(1)语句,本文中只有Draw,表示绘制一个图像(2)代码块(block),本文中只有for循环,代码块包含Draw语句
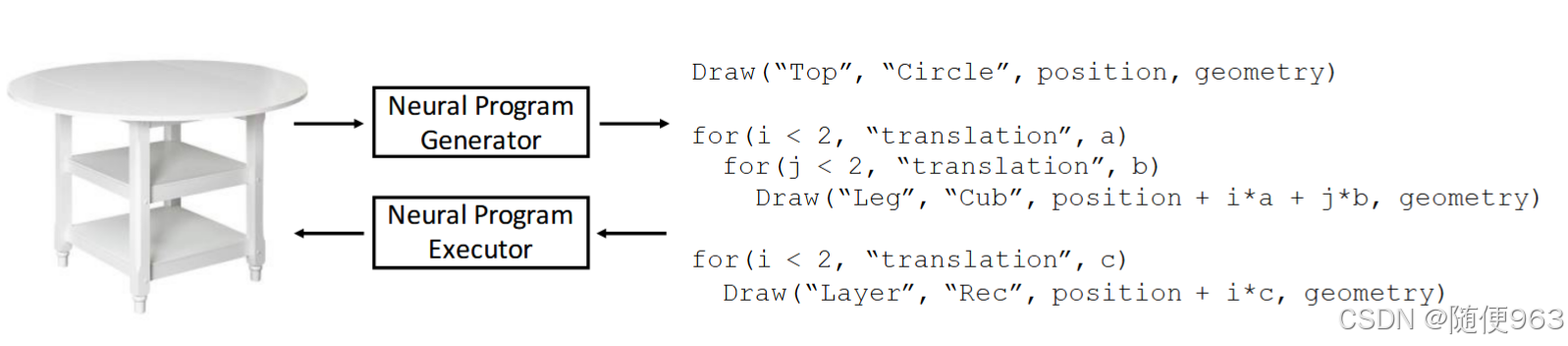
参考上下两图的信息,具体参数含义如下:
Statement,包含Draw和For两种语句
Draw: 接收以下参数
- semantic(语义):例如:“leg”,“Layer",详细了解请看“配置”一节
- shape(文章中和category一词混用):例如:“Cub”,“Rec”
- 几何、位置参数
注意semantic参数不会影响基元的几何体;相反,它们将几何部分与其语义含义相关联,帮助在语义和功能上跨物体类别共享部分(例如,椅子和桌子可能具有相似的腿)。(我的理解是,虽然semantic不能直接体现在图像上,但是可以辅助程序的生成阶段)
For 接收For_Params
- Translation_Params:平移,可参考上图
- Rotation_Params:旋转,绕轴旋转固定角度
For循环帮助捕捉high-level的规律,例如,桌子的腿可以相对于特定的旋转角度对称。

训练阶段
回顾问题的定义:给定一个三维物体,预测一个程序,来重建该三维物体。
输入:一个三维物体,本文的格式为体素
输出:一段自定义格式的DSL代码
然后使用训练好的NPI来执行这段程序,重建物体。当然也可以把这段代码翻译成CAD的标准语言来重建。但二者必然存在一些gap。
网络结构
模型分为两部分:program generator(下图) and a neural program executor.
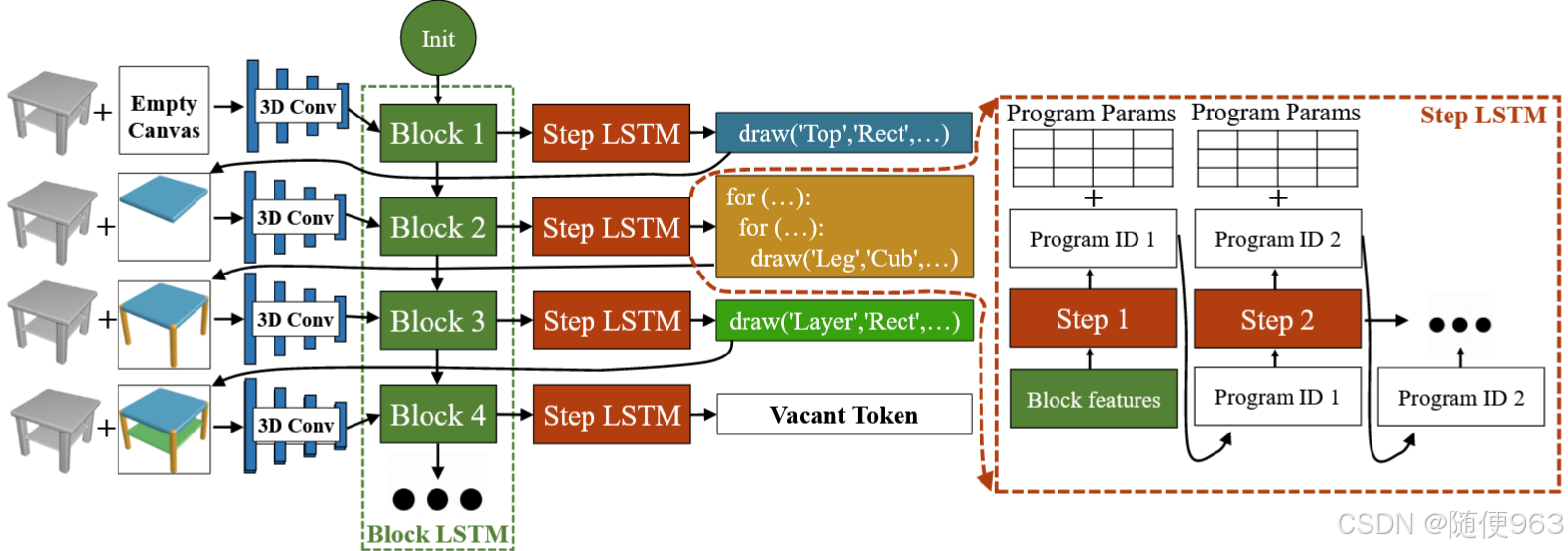
程序生成器(program generator)(上图):
任务定义还是:给定三维物体,输出程序
程序是不定长输出的,所以可以看作NLP中的文本生成问题,序列建模,使用传统的LSTM处理。这里要注意:不仅要生成high-level的每个代码句/块,而且每个代码句/块内部也要逐个生成low-level的“单词”(可能使用数字表示)
LSTM又分为Block LSTM和Step LSTM,对于每一个high-level时间步:
- Block LSTM
输入:上一时间的信息 + conv(目标三维物体+已经生成的三维部分)提取的3D卷积特征
输出:混合后的这两部分信息,提供给下游的Step LSTM - Step LSTM
输入:conv(目标三维物体+已经生成的三维部分)提取的3D卷积特征 + 再经过Block LSTM处理。
输出: a program id (N,)and an argument matrix(N, K)。这里原论文说的不清不楚,下面解释一下,N应该表示生成的代码块中语句的数量,如果只有Draw语句,那么N=1,For代码块的N>=2。
Program id应该表示该语句是Draw还是For循环
参数矩阵(Argument matrix)表示该语句的参数,K的长度应该是根据“代码设计”一节第二张图的所有参数数量确定的。(注意K不是变长的,所以无论Program id 是Draw还是For, 参数矩阵中都要包含For_params)
3D卷积最后一层是average pooling
p
t
p_t
pt表示program id,
a
t
a_t
at表示参数矩阵,由两个MLP接收LSTM的隐状态层(64-dimension的embedding)分别得到:
h
t
=
f
l
s
t
m
(
x
t
,
h
t
−
1
)
,
p
t
=
f
p
r
o
g
(
h
t
)
,
a
t
=
f
p
a
r
a
m
(
h
t
)
h_t = f_{lstm}(x_t, h_{t-1}), \\ p_t = f_{prog}(h_t), a_t = f_{param}(h_t)
ht=flstm(xt,ht−1),pt=fprog(ht),at=fparam(ht)
最后Step LSTM的输出被转换为一个代码句/块,生成一个三维物体输入到下一个high-level时间步
我觉得把(目标三维物体、已经生成的三维部分)做一个差值,会不会更有助于学习?剩余部分就是新的生成目标
损失函数:
为了确定如何训练,首先要确定输出的ground truth label。论文中是 program id和argument matrix。前者是分类任务,使用交叉熵,后者是回归任务,使用L2 loss(MSE)。
ℓ
g
e
n
=
∑
b
,
i
w
p
l
c
l
s
(
p
b
,
i
,
p
^
b
,
i
)
)
+
w
a
l
r
e
g
(
a
b
,
i
,
a
^
b
,
i
)
\ell_{gen} = \sum_{b,i} w_p l_{cls}(p_{b,i}, \hat{p}_{b,i})) + w_a l_{reg}(a_{b,i}, \hat{a}_{b,i})
ℓgen=b,i∑wplcls(pb,i,p^b,i))+walreg(ab,i,a^b,i)
预训练:
由于我们能写一些简单的程序来生成三维物体,我们就拥有了(三维物体、程序)数据对来进行预训练。但是任务太简单,难以应用到复杂的物体上
neural program executor:(本文简称为NPI)
任务定义是:给定程序,输出三维物体
作者在block level(我这里的block和之前上文的代码块还不完全一样,block是代码句/块)上来解释代码,也就是一次只解释一个Draw代码句,或者For循环以及循环内的所有语句,这正好和我们生成代码阶段的level是相同的。

像python解释器一样逐句解释代码,对每一个代码block,使用LSTM提取特征;
要把代码重建到3D空间中,使用3D反卷积是合适的选择。
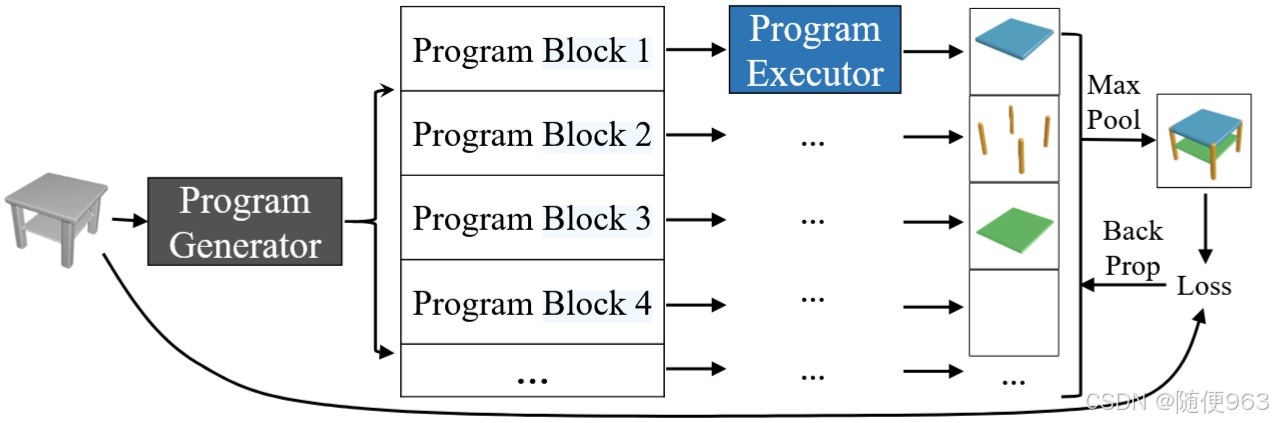
由于每个代码block重建的三维部分是互不干扰的,所以这个阶段可以并行,使用maxpool逐点提取每个代码block生成三维的公共部分,如上图所示。
maxpool有点类似点云的思想,让人不禁思考,能不能使用点云替代体素
损失函数:
这是一个语义分割任务,两种语义:有/没有。作者使用了分类的方式,最后一层是sigmoid:
L
=
∑
v
∈
V
−
w
1
y
v
log
y
^
v
−
w
0
(
1
−
y
v
)
log
(
1
−
y
^
v
)
\mathcal{L} = \sum_{v \in V} -w_1 y_v \log \hat{y}_v - w_0 (1 - y_v) \log (1 - \hat{y}_v)
L=v∈V∑−w1yvlogy^v−w0(1−yv)log(1−y^v)加权平衡了空洞的部分和不空洞的部分,因为实践中空洞的部分可能很多。
预训练:
同上一部分:由于我们能写一些简单的程序来生成三维物体,我们就拥有了(三维物体、程序)数据对来进行预训练。
guided adaptation
其实就是二者共同端到端训练的阶段,见上一张图。
由于NPI是神经网络,可反传梯度,端到端优化,类似自编码器。使用交叉熵重建误差,把预测体素改为了0-1分类任务。maxpool保证程序可变长。
但是原文“Vacant tokens are also executed and pooled.”这句我没懂。
实验
配置
- shapeNet数据集,Pix3D
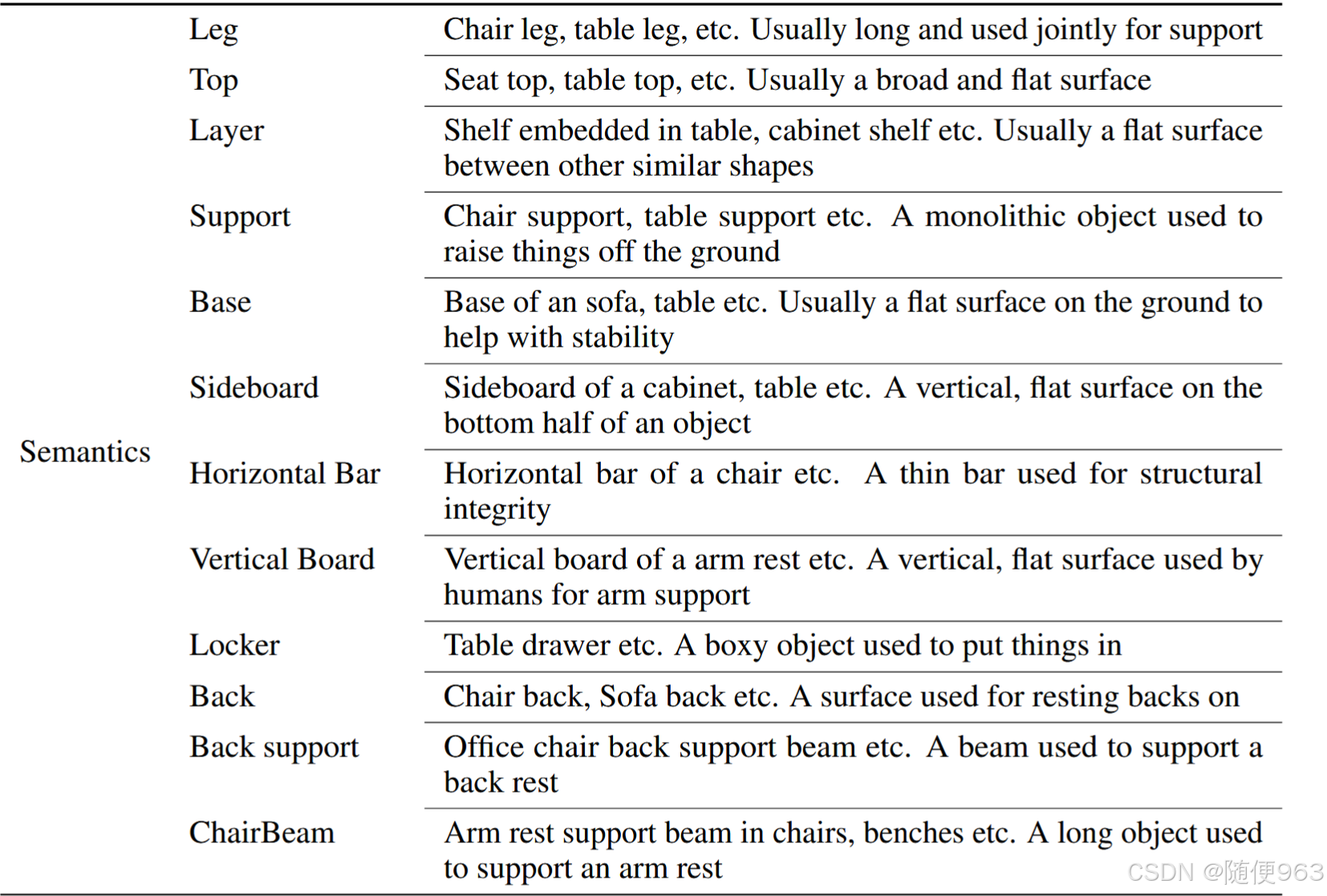
- 语义种类如下,都是一些物体共享的部分
分析
作者想展示模型学到了High-level的语义,给出了两个指标:
- 连通性:一个椅子的各个部位应该是连通的,否则就散架了
- 稳定性:一个椅子应该能稳定的立在地面上
作者还使用本工作对Marrnet重建的结果进行平滑,结果相当好:

总结
学习到一个从三维物体中推理出生成程序的模型,学习到一个解释程序的模型,首先预训练,之后二者端到端优化,冻结后者。
能捕捉到high-level的几何信息。
问题
- Block LSTM是必要的吗?
答:我觉得不是,因为我们已经知道生成目标和已经生成的部分了,它们之差就是期望生成的部分 - semantic对于重建的作用?
答:我觉得没有实质作用,但是能辅助生成 - maxpool的对于优化的影响?
答:maxpool对于label为0的点,要求所有值都输出为0。对于label为1的点,要求最大值输出为1,不管其他值,这可能导致生成部分的重叠。 - for循环是如何生成的?
答:可能在训练数据集上比较常用,但是怎么避免重复生成n句类似语句来代替for循环?我不知道。可能对for循环加一个奖励,或者惩罚程序长度会好一些? - 程序执行器为什么冻结参数?
答:容易训练不稳定。而且会与程序生成器相互适应,导致灾难性遗忘,执行器的执行功能丧失,代码生成器的代码不再可迁移,严重依赖相适应的执行器来解释。 - 程序执行器冻结参数的问题?
答: 它只在简单的数据集上训练过,并没有见过复杂的数据。性能容易出问题。
limitation
- 2019年使用的LSTM,放到今天可能有点过时了
- 有时我们只能获得物体的单个视图
- 没法给物体上色,导致无法提供视觉信息
展望
作者说预测的semantic是个双刃剑,它自然地支持跨形状的语义对应,并支持更好的类内重建;另一方面,它可能会限制泛化到训练数据之外的形状的能力。
作者希望从形状中学习到原子形状(shape primitives),可以参考聚类算法,把相似的形状归到一类,而不是人工分类。
作者还讨论了结构化搜索的问题:
神经网络没有经过太多思考就输出第一条程序,但很可能不是最优的。最优的思考结果需要很大计算量。就好像GPT无法用少量token证明费马大定理一样。原文中的摊销推理(amortized inference)含义应该是把开销都分摊到训练时间段,推理的时候输出很快,不用在解空间中搜索。
这个问题有没有可能参考beam search,做到较优的解?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









