







前言
本系列面向两种读者:(1)想浅显、直观了解论文的主要方法(2)读论文的时候有地方不理解,想深入研究论文的细节
这篇论文《Where2Act: From Pixels to Actions for Articulated 3D Objects》是斯坦福三维视觉、图形学强组的工作,2021年中稿ICCV,一作Kaichun Mo(莫凯淳)是上海交通大学ACM班本科第一名,通讯作者是Leonidas Guibas,目前已有相当可观的159次引用。
- 论文地址:https://arxiv.org/abs/2101.02692
- 项目主页:https://cs.stanford.edu/ ̃kaichun/where2act
- 代码地址:https://github.com/daerduoCarey/where2act
核心思想
一句话总结:目标是建立一个感知系统(perception system),从交互中学习(from interaction),输入单帧RGB或部分点云图像,预测给定原子动作类别的affordance信息:where/what/how to act?因为没有数据对,使用采样(也就是交互)的方式获得数据用来监督学习。
与关注where的前人不同,这篇文章的中心放在了what和how上,也就是动作类型和交互方向/姿态。
Affordance learning 的核心出发点是为机器人的决策(decision)和操纵物体(manipulation)提供有效的表征(representation),或者说可操作信息(actionable information),通俗来说就是可以把包含affordance的信息输入到机器人决策和操作的神经网络中作为辅助信息。它包含三个核心概念:(请牢记这三点!)
- where:哪个位置是可操作的(视野中的哪一个像素/点云)
- what:这个位置可以执行什么操作(pull, push,…)
- how:如何执行这个操作(pull动作的参数)
作者总结的论文贡献如下:
- 我们将任务定义为通过推理逐像素的动作分数(likelihoods)和动作建议(proposals)来得到可操纵3D铰接物体的Affordance;
- 提出了从交互中学习的方法,同时使用适应性采样来获得更多有价值的采样。
- 我们在SAPIEN中建立了benchmark。我们的网络能够学习到动作的视觉表征(visual representation),并能够泛化到新的shape甚至是未见过的物体类别上。
前置知识
- 铰接(articulated object)物体的概念
- 机器人学:位置position、姿态/方向orientation
- 末端执行器end-effector与gripper
- 矩阵理论:SO(3)与SE(3),非常简单的概念。6D-rotation representation
- 点云, RGB-D,pointnet、pointnet++网络
- Partnet和PartNet-Mobility数据集,SAPIEN仿真环境
- Affordance learning:请参考本人的综述:#TODO
与前人工作的对比
- 预测语义表征(semantic representation)的方法
问题:只获得了where的信息和间接的what,how的信息,例如:给出“把手”、“按钮”的位置,但没有直接指明如何(how)使用这个“把手”或“按钮” - 推断物理属性的方法
问题:引入了对推理帮助不大的冗余信息,而且还是没有指明如何操作(how to act) - 被动学习vs主动学习
这是相对于本文“在交互中学习”的概念
问题:模仿学习没有足够的负样本;相机的位置很重要,观察者和学习的对象的视角和构造都可能不同 - 从交互中学习
问题:大部分工作都关注于相对复杂的动作,没有关注low-level的动作。于是作者提出了学习low level的动作原语
方法
首先考虑我们应该提供什么样的affordance可操作信息(actionable information)。
针对where, what, how,作者提供了以下三点actionable information:
1.可操作分数(‘actionability’ score),物体表面的每一个点都有逐点(pointwise)的可操作的概率分数,对应where to interact,
2. 动作提议(action proposals),一个在该点操作方向矩阵R的提议,对应how to interact,
3. 交互分数(interaction outcomes),用来评估前两个信息是否有效
这里读者不禁要问:what去哪里了?
答案是what是动作类型,这里涉及到动作空间参数化的问题,论文中动作类型采用的是动作原语(primitive action)或者说原子动作,共六种:push,push-up,push-left,pull,pull-up,pull-left。作者为每个原子动作专门训练一个模型(decoder head ,MLP)
那么问题来了,为什么没有将what作为actionable information来输出?
可能的答案是:
- 同一个物体可以有多个对应的action,例如:门可以被推、拉。所以对一个位置,不能预测一个动作,也不能预测归一化的多个动作概率(这样体现不出来绝对值)。
- 可能的动作太多,但我们只关心我们任务所需要的动作。
- 生成方向矩阵R的时候必须根据对应的唯一动作来生成,如果第一阶段输出了大量提议的动作类型,需要在第二阶段针对动作类型来提议方向矩阵R,这样要么难以控制生成的R的数量,要么难以控制#TODO
可以把本文的动作类型当作一个key,去查询不同的模型(decoder head ,MLP)来得到动作对应的affordance information
训练阶段
这里请注意:为每一个原子动作训练一个神经网络!(具体指的是encoder提取特征之后的三个decoder MLP网络)因此原子动作并不作为网络的条件输入。请牢记这一点
输入:(动作类型被隐式的提供了,因为模型是专门训练的)
- 一个二维RGB图像,或者三维RGB-D图像(3D 部分点云扫描(3D Partial Point Cloud Scan)),分别对应C*H*WF的图片、D*N的点云
输出:
1.可操作分数(‘actionability’ score)
a
p
a_p
ap,对输入的每一个点(像素/点云)输出一个分数
3. 操作提议(action proposals)
R
z
∣
p
R_{z|p}
Rz∣p,提议一个矩阵R
∈
\in
∈SE(3),表示(操作的)姿态
4. 交互分数(interaction outcomes)
s
R
∣
p
s_{R|p}
sR∣p,一个标量分数,表示在某一点某一方向执行某一操作的靠谱程度
训练方式
使用监督学习,获得(data, label)的数据对,使用神经网络进行训练。
数据格式为(S, p, R, r)的数据对。其中前三者对应data,后者对应label(R也可以作为label),它们的含义是:
- S(state):环境信息,场景中的物体是什么(门、柜子、抽屉)?物体初始状态是什么(门开了多少角度)?机械臂初始位置是什么?视角(相机的信息)是什么?
- p:二维像素或三维点云,点云是(从一个视角)部分扫描的
- R:末端执行器(gripper)到该点的姿态/方向(orientation),使用一个矩阵R表示。请注意:R并不是旋转矩阵,因此与执行器的初始姿态无关
- r(reward):交互是否成功(success or fail),作者定义为:“如果我们正在交互的零件沿预期方向表现出相当大的零件运动,则我们定义一次交互试验成功。”
网络结构:
- backbone
首先我们需要提取逐像素/点云的信息,这是一个类似于语义分割的任务,输入和输出的大小相同。对于二维RGB、三维点云输入,自然分别使用Unet, Pointnet++作为backbone,也就是逐点的特征提取器(feature extractor)。
使用视觉输入得到{ f p f_p fp}(表示一个逐点特征的集合, f p f_p fp表示一个点的特征),然后利用这些特征输入到下游decoder head的三个MLP模块中,注意这时每个点已经与其他点的信息做了交互。请参考下图:
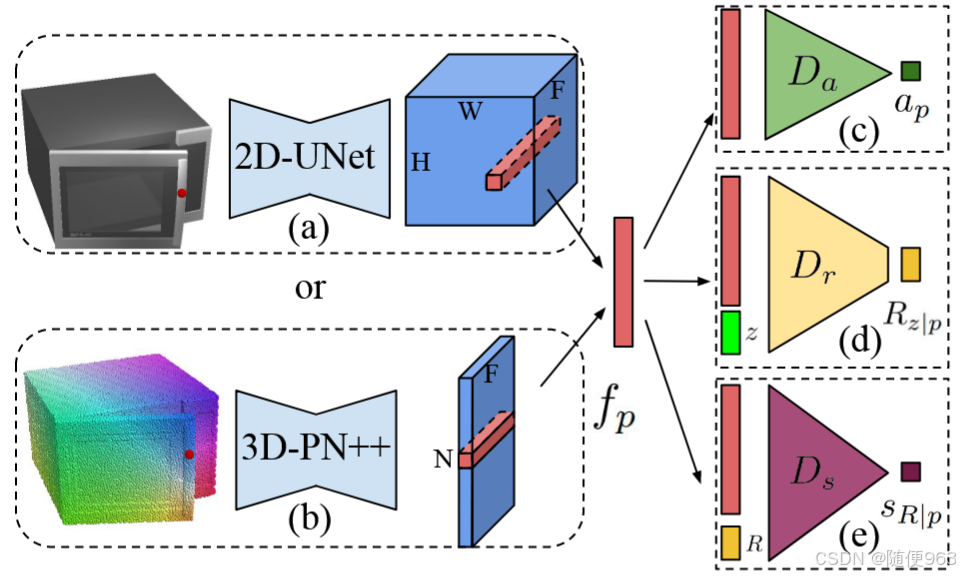
- 可操作性评分模块(Actionability Scoring Module),记作
D
a
D_a
Da
我们已经有了逐点的特征 f p f_p fp,将其输入到一个MLP中得到分数 a p ∈ [ 0 , 1 ] a_p\in[0,1] ap∈[0,1],表示该点可操作的可能概率。
a p = D a ( f p ) a_p = D_a ( f_p) ap=Da(fp) - 操作建议模块(Action Proposal Module),记作
D
r
D_r
Dr
这里使用了条件生成模型,基于MLP,接收高斯噪声z和逐点的特征 f p f_p fp,生成一个表示 夹持器(gripper)方向(orientation)的矩阵 R ∈ S O ( 3 ) R\in SO(3) R∈SO(3)。
使用生成模型可能是为了保证策略的多样性,这能保证模型充分探索到所有可能的动作,有利于采样阶段。
作者在这里使用6D旋转表示,通过 3 × 3 旋转矩阵中的前两个正交轴来表示 3-DoF 夹持器方向。问题:理论上3个参数就能表示一个旋转矩阵,为什么要6D表示?
R z ∣ p = D r ( f p , z ) R_{z|p} = D_r ( f_p, z) Rz∣p=Dr(fp,z) - 操作评分模块(Action Scoring Module),记作
D
s
D_s
Ds
出发点是根据末端执行器的位姿 ( p , R ) ∈ S E ( 3 ) (p, R) \in SE(3) (p,R)∈SE(3),估计一个分数 s R ∣ p ∈ [ 0 , 1 ] s_{R|p} \in [0, 1] sR∣p∈[0,1],衡量该动作的可行性。实践中使用MLP,接收逐点特征和方向矩阵 ( f p , R ) ( f_p, R) (fp,R)
s R ∣ p = D s ( f p , R ) , s_{R|p} = D_s ( f_p, R) , sR∣p=Ds(fp,R),
如何训练?
既然目标输出已经有了,“如何训练”其实就是两个核心问题(1)如何设置input和label?(2)如何计算loss?
实践中发现首先训练
D
s
D_s
Ds模块会更好(可能是因为这部分更好优化)
- 操作评分模块(Action Scoring Module),记作
D
s
D_s
Ds
(1)输入实际采样得到的(p,R),得到预测分数 s R ∣ p s_{R|p} sR∣p,label是采样得到对应的r(是否成功)(2)这是一个分类问题,使用交叉熵分类损失
L s = − 1 B ∑ i r i log ( D s ( f p i ∣ S i , R i ) ) + ( 1 − r i ) log ( 1 − D s ( f p i ∣ S i , R i ) ) . \mathcal{L}_s = -\frac{1}{B} \sum_i r_i \log \left( D_s(f_{p_i|S_i}, R_i) \right) + (1 - r_i) \log \left( 1 - D_s(f_{p_i|S_i}, R_i) \right). Ls=−B1i∑rilog(Ds(fpi∣Si,Ri))+(1−ri)log(1−Ds(fpi∣Si,Ri)). - 操作建议模块(Action Proposal Module),记作
D
r
D_r
Dr
(1)输入实际采样得到的(p,),执行100次生成,使用Min-of-N strategy,其实就是只优化最好的结果。label是采样得到对应的R矩阵。注意这里要求这批次采样的r=1(操作成功)(2)最小化两矩阵(6-D表示)之间的距离
L r = 1 B ∑ i = 1 B min j = 1 , ⋯ , 100 dist ( ( D r ( f p i ∣ s i ; z j ) ) , R i ) , \mathcal{L}_r = \frac{1}{B} \sum_{i=1}^{B} \min_{j=1,\cdots,100} \text{dist}\left(\left(D_r(f_{p_i|s_i; z_j})\right), R_i\right), Lr=B1i=1∑Bj=1,⋯,100mindist((Dr(fpi∣si;zj)),Ri), - 可操作性评分模块(Actionability Scoring Module),记作
D
a
D_a
Da
(1)输入:前两个阶段得到的结果,利用它们作为伪标签计算出pseudo-label。具体而言:上一部分生成的100个矩阵R加上对应点特征 f p f_p fp计算出操作评分(评分就是成功概率)的平均值作为label(2)MSE损失
作者在这里说:
(a)我们本来可以在这个点p重新生成+执行一遍操作,根据成功率来确定分数。(我觉得之所以没这么做是因为节省计算量和仿真量)
(b)这么做并不耗费算力,因为我们在上一模块中已经生成过100个矩阵R了
(c)由于 D r D_r Dr的生成具有多样性,能够涵盖大部分情况,所以这么计算还算准确
我的疑惑:为什么不直接把上一阶段生成的100个矩阵R在仿真器中跑一遍呢,这样更准确啊?
a ^ p i ∣ S i = 1 100 ∑ j = 1 , ⋯ , 100 D s ( f p i ∣ S i , D r ( f p i ∣ S i , z j ) ) ; \hat{a}_{pi|Si} = \frac{1}{100} \sum_{j=1,\cdots,100} D_s \left( f_{pi|Si}, D_r \left( f_{pi|Si}, z_j \right) \right); a^pi∣Si=1001j=1,⋯,100∑Ds(fpi∣Si,Dr(fpi∣Si,zj));
L a = 1 B ∑ i ( D a ( f p i ∣ S i ) − a ^ p i ∣ S i ) 2 . \mathcal{L}_a = \frac{1}{B} \sum_i \left( D_a(f_{pi|Si}) - \hat{a}_{pi|Si} \right)^2. La=B1i∑(Da(fpi∣Si)−a^pi∣Si)2.
总结一下:训练的流程为#TODO
如何收集数据?
affordance learning的特点是人工标注数据特别昂贵,因此必须采用自监督的方式来获取有标注的数据对。因此作者使用随机采样的方法,获得了大量(S, p, R, r)数据对。但是由于随机采样的方式效率极其低下,数据不平衡或者说正样本太少(1%)(可交互的位置p过于少,而且就算到了位置p,姿态R也很可能不合适)。
于是作者(1)维护两个相等长度的正、负样本队列,而且同等概率采样不同shape(2)利用监督学习的结果来提升采样正样本的效率。具体而言是先后采用offline,on-policy的策略(参考强化学习)。
- offline,在铰接部位表面随机采样(p,R),根据是否成功得到(S,p,R,r)
- on-policy,操作评分模块
D
s
D_s
Ds能衡量一个点p在方向R执行动作是好还是不好,所以采样时任意给定一个方向矩阵R,作者对所有点p根据R进行评分,这样每个点都有一个分数s=
D
s
D_s
Ds(p,R)(也就是成功概率),使用softmax策略根据概率对所有点进行采样,得到(p*,R,r)数据对。
然而,这种自适应的方法依然有未充分探索的问题,所以依然采用了一半的随机数据。(我的解释是此前尝试次数少的区域可能由于采样次数少、方差大,因而得到一个较低的概率分数,导致对此前尝试次数少的区域采样数据不够)
实验
测试(test)与评估(metric)
评估 D s D_s Ds:随机采样摄像机视角,位置,姿态,使用F-score。可想而知成功率非常低。
使用 ssr 对三个指标做全面评估:使用
D
a
D_a
Da得到采样概率,采样一个交互点,然后用
D
r
D_r
Dr生成大量动作提议R,最后用
D
s
D_s
Ds进行评估,根据分数确定采样概率。对于概率设定0.5为阈值,过滤掉低概率的部分。然后测试成功率。
这其实模拟了给机器人提供affordance信息来辅助manipulation的完整流程,也就是从train过渡到test的转变,指明了把本工作应用到manipulation中的方法。
同样,采样100个动作提议R,公式为:
s
s
r
=
#
s
u
c
c
e
s
s
f
u
l
p
r
o
p
o
s
a
l
s
#
t
o
t
a
l
p
r
o
p
o
s
a
l
s
ssr = \frac{\# successful\ proposals} { \# total\ proposals}
ssr=#total proposals#successful proposals
这里我觉得在实际应用阶段可以选
D
a
D_a
Da分数最高的交互点,而不是根据概率采样?同样
D
s
D_s
Ds也选分数最高的。
Baselines
未完待续…
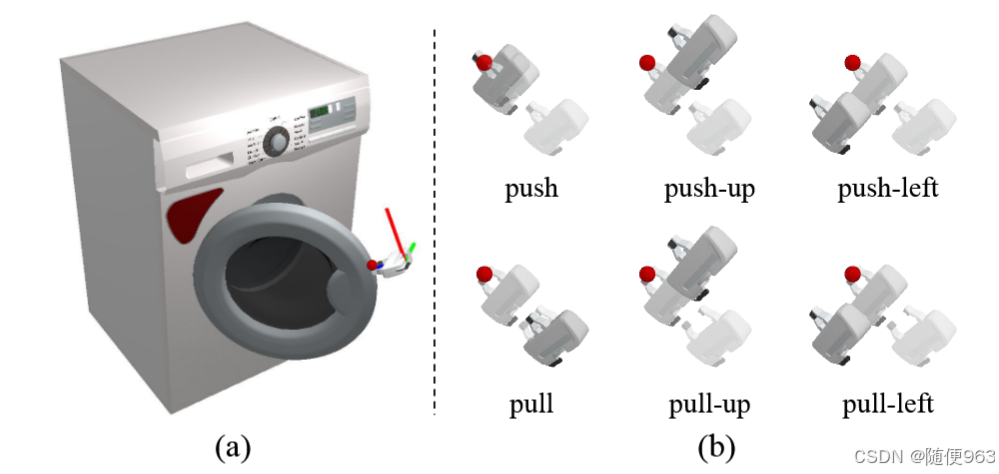
对上图红色区域的解释:#TODO
配置
- 使用SAPIEN模拟器,而SAPIEN使用了NVIDIA PhysX作为物理引擎,关于SAIPEN,请看:
- 使用Franka Panda Flying Gripper
- 删去了太小的物体)、无法操作的物体(桌子)、需要多抓手合作来操作的物体,使用6个动作原语:push,push-up,push-left,pull,pull-up,pull-left,15种物体类别
- 三维物体经过normlize,在单位球中
- 从具有已知内在参数的 RGB-D 相机观察场景中的物体,该相机安装在距离物体 5 个单位的地方,面向位于物体上半球的物体中心,具有随机方位角 [0◦, 360◦] 和随机高度 [30◦, 60◦],参考上面的图
还有几个细节:
- 已知gripper初始位置,给定目标操作点和操作方向R,如何移动到该位姿?
答:使用NVIDIA PhysX 内部 PID 控制器,高级轨迹规划是通过在具有已知起始和结束末端执行器位姿之间进行简单的运动学计算插值来完成的。 - 给定二维可操作的pixel点数据,如何定位到该位置(没有三维信息)?
答:可能是利用了类似Inverse Perspective Projection(逆透视投影)的方法,将图像中的像素坐标转换为世界坐标系中的三维坐标。需要已知相机的内参和外参。
limitation
前三条是论文中提出的:
- 网络使用单帧视角作为输入,如果铰接部件运动信息无法从单帧中进行确定,则容易引起解空间的二义性
- 实验限制在6个类型的原子动作,每个动作策略都是硬编码的(没有可调整的参数)
- 没有显式地对零件分割和零件运动轴(part segmentation and part motion axis)进行建模(我的理解是:没有利用这方面的信息)
- 每一个动作都需要重新训练一个模型
- 逐点预测可操作性,并生成大量操作提议,在计算上有点昂贵
- 没有体现交互的力学信息:使用多大力进行push?
- 采样效率太低,正样本数量不足
- 没有利用充足的(尤其是连续的)上下文视觉环境信息,例如,在厨房中的东西很可能是能打开的微波炉。
- 视角是fix住的,不是第一视角
我的思考
思考论文中的设计,关键在于想象一下没有这部分会怎么样,从而领悟到作者设计的巧妙,以及各部分的紧密耦合。
问题:
- 为什么要在交互中学习?
答:(1)省人力成本,不用人工演示(2)充分探索所有可能的结果 - 为什么操作建议模块
D
r
D_r
Dr是生成模型?可以是确定性的输出吗?
答:在之前“网络结构”章节,我们已经讨论过了。这有利于充分交互探索。 - 为什么要使用操作评分模块
D
s
D_s
Ds?
答:因为生成模型给出的是从操作方向R的分布中采样的结果,并不保证该采样一定可行,需要对生成结果进行评估 - 为什么decoder head都是MLP?
答:因为每个动作都要专门训练一个decoder head,MLP比较轻量级 - 能不能把动作类型作为输入条件,尤其是作为生成模型
D
r
D_r
Dr的生成条件?
答:笔者还在思考,似乎是可行的,这必然要求增大 D r D_r Dr - 为什么要逐像素/点云预测操作的可行性?
答:有一种替代方案:输出n个最可行点的坐标。但这个方法存在的问题是(1)从输入图片到输出坐标,这有点类似目标检测(2)提供的采样点不够多,在收集数据阶段难以做到多样化。 - 能不能使用多帧视角的点云作为输入?
答:问题是如何根据多帧视角中确定的不同交互点,最终确定一个准确的交互坐标。而且实际应用中视角一般只有一个。 - 能不能对动作进行参数化,例如:调整push的距离?
答:这是作者后续VAT-MART论文的工作,关于更多解读,请看本人的:【具身智能 Affordance learning论文精读系列】VAT-MART - 本工作只指定了执行器的目标位姿,能不能生成移动的轨迹?
答:这是作者后续VAT-MART论文的工作,关于更多解读,请看本人的:【具身智能 Affordance learning论文精读系列】VAT-MART
总结
使用视觉表征,从交互中学习。采样数据,监督学习:输入单帧图像,对于给定动作,生成位姿提议,根据概率采样来进行交互。
这篇论文中使用了很多小trick,很多细节都值得推敲,可以作为了解本领域的一篇模板式的工作。
想更深入了解Affordance learning,请关注本系列的其他文章
笔者才刚刚入门,有什么问题欢迎指正!
参考
【计算机图形学】Where2Act: From Pixels to Actions for Articulated 3D Objects


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









