






LoRA微调详解:高效优化大模型的利器
1. 引言
近年来,大型预训练模型(如 GPT、BERT)在自然语言处理、计算机视觉等领域取得了巨大成功。然而,这些模型往往参数量庞大,直接进行全参数微调(Fine-Tuning)不仅需要大量计算资源,还会带来存储和部署成本的问题。为了解决这一难题,研究者提出了一种高效的参数微调方法——LoRA(Low-Rank Adaptation,低秩适应)。本文将详细介绍 LoRA 的原理、实现方式及其优势,并结合实际应用场景,帮助读者深入理解 LoRA 的精髓。

2. 微调的挑战与 LoRA 的提出
在传统的微调过程中,我们通常需要对预训练模型的所有参数进行更新,这导致:
-
计算资源消耗大:大型模型的训练需要高性能 GPU,成本昂贵。
-
存储成本高:每次微调后都需要存储一个完整的模型副本,磁盘空间占用巨大。
-
适应不同任务的难度高:不同任务可能需要多个微调模型,维护成本增加。
为了解决上述问题,LoRA 采用了一种创新的方法,只对少量新增的低秩矩阵进行训练,而保持原模型参数冻结,从而极大降低了训练成本。
3. LoRA 的核心原理
LoRA 的核心思想是利用低秩分解来对模型的权重更新进行近似,而不是直接修改原始权重。具体来说,在神经网络的线性变换层(如 Transformer 中的自注意力层)中,权重矩阵通常表示为:
其中:
-
W 是可训练的权重矩阵
-
X是输入特征
在传统的微调中,我们会直接调整 WW,而在 LoRA 中,我们假设其权重增量 ΔW\Delta W 具有低秩结构,即:
其中:
这样,我们只需优化 AA 和 BB 这两个小矩阵,而不需要直接调整庞大的 WW,从而显著减少计算和存储需求。
4. LoRA 的实现步骤
(1)在 PyTorch 中实现 LoRA 使用 loralib 库,可以轻松为预训练模型添加 LoRA 适配器:
import torch
import loralib as lora
from transformers import AutoModel
# 加载预训练模型
model = AutoModel.from_pretrained("bert-base-uncased")
# 在注意力层应用 LoRA
for name, module in model.named_modules():
if "attention" in name:
lora.lora_wrap(module)
# 只训练 LoRA 参数
for param in model.parameters():
param.requires_grad = False
for name, param in model.named_parameters():
if "lora" in name:
param.requires_grad = True
# 进行训练
optimizer = torch.optim.AdamW(filter(lambda p: p.requires_grad, model.parameters()), lr=1e-4)
这样,我们仅训练 LoRA 部分,大幅减少训练成本。
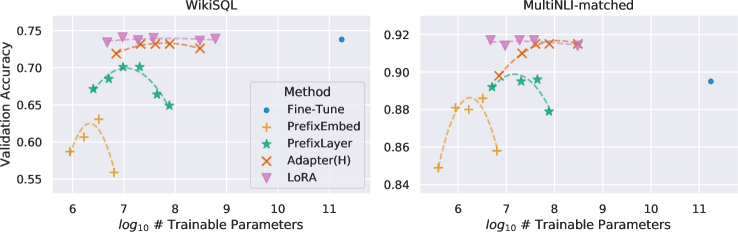
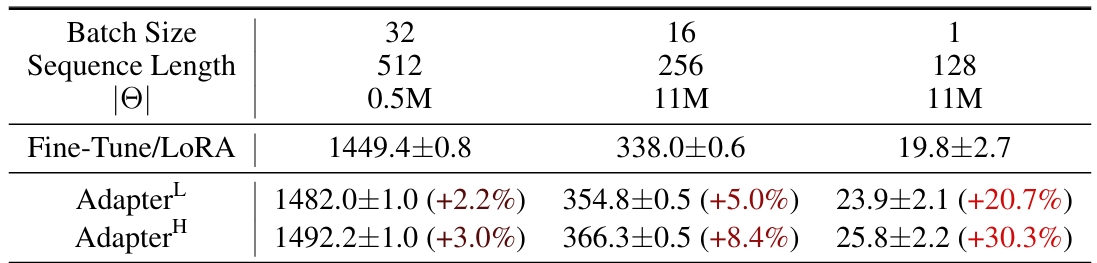
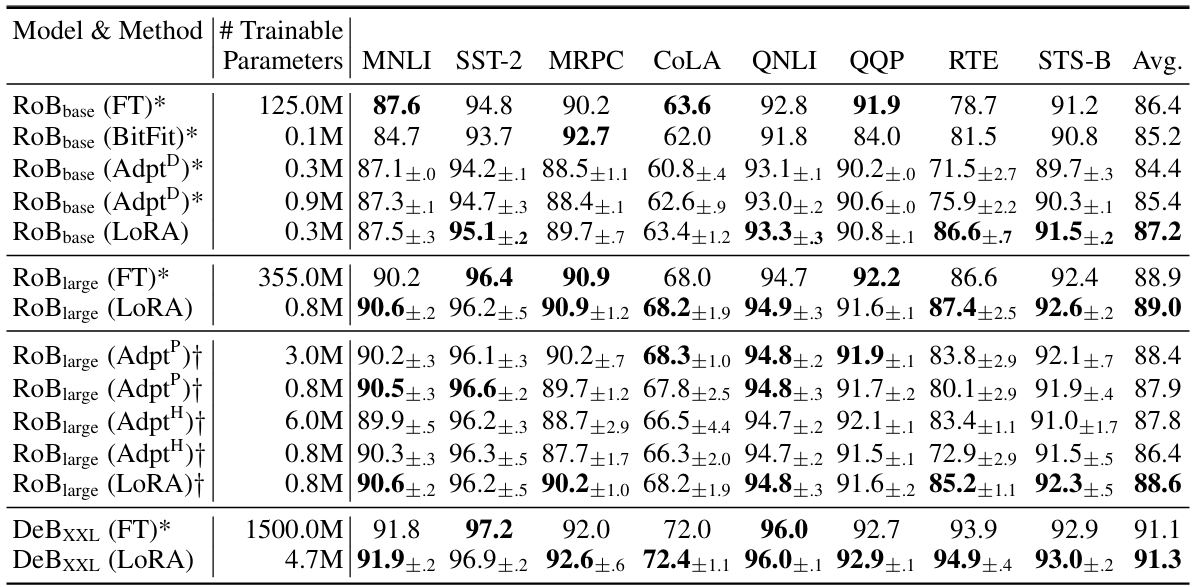
5. LoRA 的优势
相较于传统微调,LoRA 具有以下显著优势:
| 优势 | 说明 |
|---|---|
| 减少训练参数 | LoRA 仅对小型低秩矩阵进行优化,训练参数减少数十倍 |
| 降低计算成本 | 由于参数量减少,GPU/TPU 显存占用更少,训练速度更快 |
| 易于部署 | 微调后的模型仅需存储 LoRA 参数,而无需存储整个模型副本 |
| 适配多任务 | 可以快速为多个任务添加 LoRA 适配器,而无需重复训练完整模型 |
6. LoRA 的应用场景
LoRA 已在多个领域得到了广泛应用:
-
自然语言处理(NLP):用于对 GPT、BERT 等模型进行任务微调,如文本分类、机器翻译等
-
计算机视觉(CV):在 ViT 等视觉模型上进行高效适配
-
语音处理:在 ASR(自动语音识别)和 TTS(文本转语音)任务中实现高效参数优化
7. 总结
LoRA 是一种高效的参数微调方法,通过引入低秩分解,显著降低了大型模型的训练成本,同时保持了预训练模型的性能。在实际应用中,LoRA 为研究人员和企业提供了一种轻量级的解决方案,使得微调大型模型变得更加可行。
如果你正在从事大模型微调工作,不妨尝试使用 LoRA,相信它会让你的训练更加高效!
📌 你觉得 LoRA 适合哪些场景?欢迎在评论区讨论!

















 2937
2937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









