







!!!!!!!!!
很对人不知道选题怎么选 不清楚自己适合做哪块内容 都可以免费来问我 避免后期給自己答辩找麻烦 增加难度(部分学校只有一次答辩机会 没弄好就延迟毕业了)
会持续一直更新下去 有问必答 一键收藏关注不迷路
源码获取:https://pan.baidu.com/s/1q8QKsgqj8O50BK3MIiH28Q?pwd=ngid 提取码: ngid
!!!!!!!!!
项目介绍
基于大数据python sprak熬夜人群数据分析可视化系统(源码+LW+部署讲解+数据库+ppt)
技术栈
1.运行环境:python3.7/python3.7
2.IDE环境:pycharm+mysql8.0;
3.数据库工具:Navicat15
技术栈
后端:python+django
前端:vue+CSS+JavaScript+jQuery+elementui
项目截图
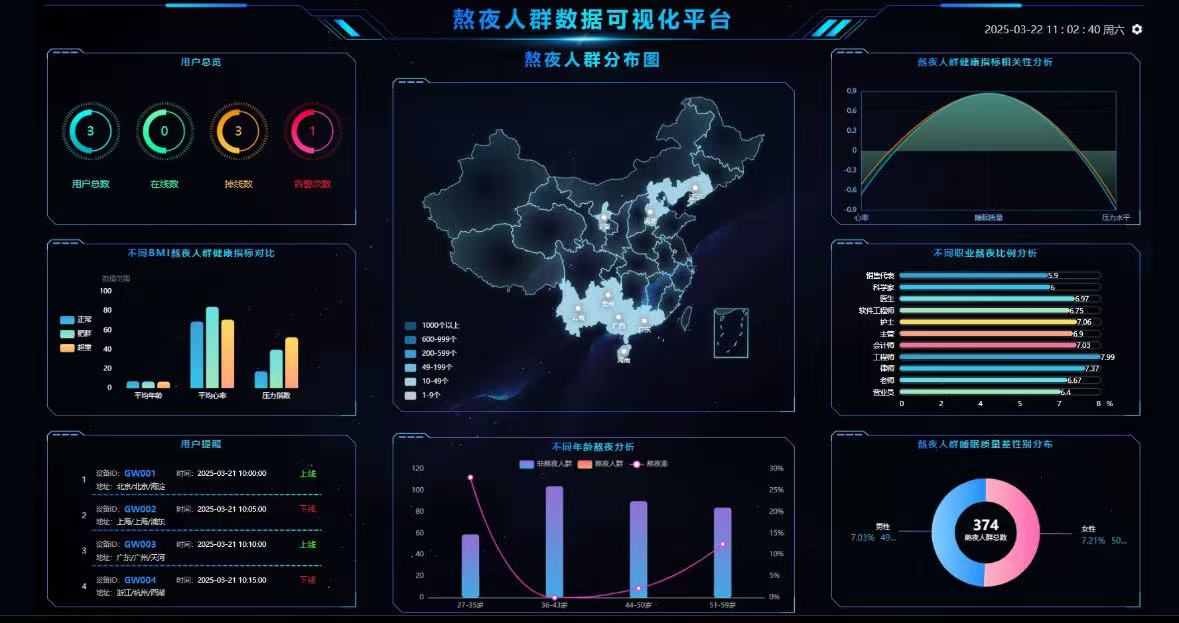
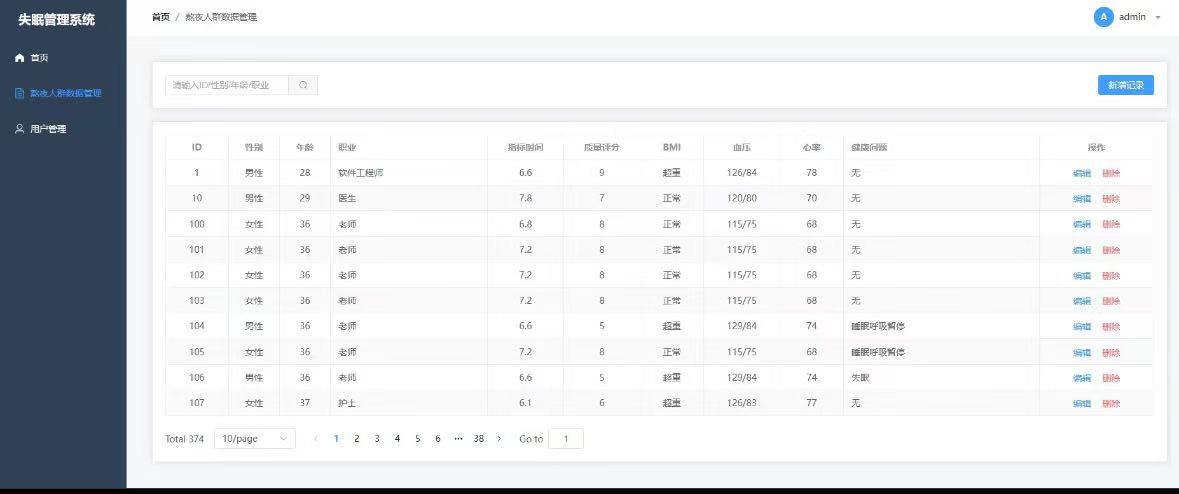
核心代码
# coding:utf-8
# author:ila
import click,py_compile,os
from configparser import ConfigParser
from configs import configs
from utils.mysqlinit import Create_Mysql
from api import create_app
from api.exts import db
from api.models.user_model import *
from api.models.config_model import *
from api.models.brush_model import *
@click.group()
def sub():
pass
@click.command()
@click.option("-v", default=0.1, type=float)
def verr(v):
# VERSION = 0.1
click.echo("py sub system version:{}".format(v))
@click.command()
def run():
app = create_app(configs)
app.debug = configs['defaultConfig'].DEBUG
app.run(
host=configs['defaultConfig'].HOST,
port=configs['defaultConfig'].PORT,
threaded=configs['defaultConfig'].threaded,
processes=configs['defaultConfig'].processes
)
@click.command()
def create_all():
app = create_app(configs)
with app.app_context():
print("creat_all")
db.create_all()
@click.command()
@click.option("--ini", type=str)
def initsql(ini):
cp = ConfigParser()
cp.read(ini)
sqltype = cp.get("sql", "type")
database= cp.get("sql", "db")
if sqltype == 'mysql':
cm = Create_Mysql(ini)
cm.create_db("CREATE DATABASE IF NOT EXISTS `{}` /*!40100 DEFAULT CHARACTER SET utf8 */ ;".format(database))
with open("./db/mysql.sql", encoding="utf8") as f:
createsql = f.read()
createsql = "DROP TABLE" + createsql.split('DROP TABLE', 1)[-1]
cm.create_tables(createsql.split(';')[:-1])
cm.conn_close()
elif sqltype == 'mssql':
cm = Create_Mysql(ini)
cm.create_db("CREATE DATABASE IF NOT EXISTS `{}` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;".format(database))
with open("./db/mssql.sql", encoding="utf8") as f:
createsql = f.read()
createsql = "DROP TABLE" + createsql.split('DROP TABLE', 1)[-1]
cm.create_tables(createsql.split(';')[:-1])
cm.conn_close()
else:
print('请修改当前面目录下的config.ini文件')
@click.command()
@click.option("--py_path", type=str)
def compile(py_path):
print("py_path====>",py_path)
py_compile.compile(py_path)
@click.command()
def replace_admin():
filePath=os.path.join(os.getcwd(),"api/templates/front/index.html")
if os.path.isfile(filePath):
print(filePath)
with open(filePath,"r",encoding="utf-8") as f:
datas=f.read()
datas=datas.replace('baseurl+"admin/dist/index.html#"','"http://localhost:8080/admin"')
datas=datas.replace('baseurl+"admin/dist/index.html#/login"','"http://localhost:8080/admin"')
with open(filePath,"w",encoding="utf-8") as f:
f.write(datas)
sub.add_command(verr)
sub.add_command(run,"run")
sub.add_command(create_all,"create_all")
sub.add_command(initsql,"initsql")
sub.add_command(replace_admin,"replace_admin")
if __name__ == "__main__":
sub()

















 5467
5467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









