







问题:
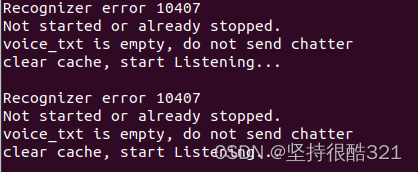
查阅了很多资料如下:
解决方案一:
参考:ROS科大讯飞语音错误:Recognizer error 10407-优快云博客
原因:so文件的复制与链接:
解决:进入到下载的SDK包 ;(64位选“x64”,32位选”x86“)
sudo cp libmsc.so /usr/local/lib/
sudo ldconfig没有解决我的问题。
解决方案二:
查阅资料是:SDK和AppID和你的应用没有对应上
于是查阅:
grep appid /home/用户名/ros_senior/robot_voice -r
查看自己的程序那些地方包含了appid。
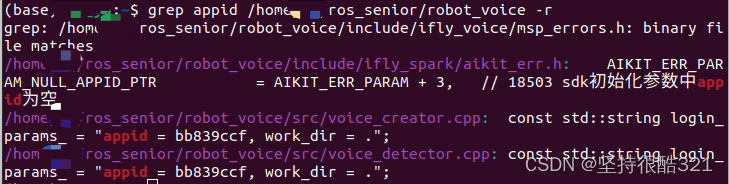
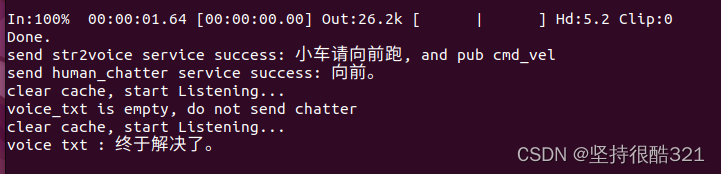
修改appid为自己申请的appid号即可解决。
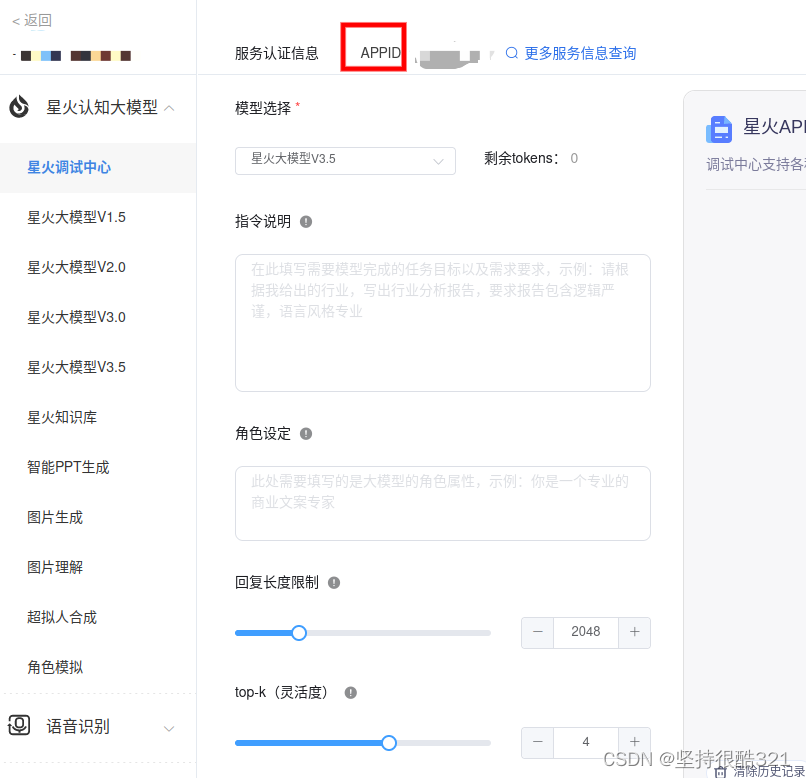
这里可查看自己的appid号:


















 4830
4830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









