






一、多进程技术(multiprocessing模块)
- 进程创建与管理
Process类实现多进程抓取(每个页面分配独立进程)daemon=True将存储进程设为守护进程(主进程退出时自动终止)join()同步进程,避免主进程提前退出
- 进程间通信
JoinableQueue线程安全队列:- 生产者进程(
get_work_info)放入数据 - 消费者进程(
save_work_info)取出并存储 task_done()和queue.join()确保任务完全消费
- 生产者进程(
二、网络请求与数据解析
- HTTP请求
requests.get发送带参数的API请求(params封装查询条件)- 请求头伪装(
User-Agent模拟浏览器)
- JSON数据处理
response.json()解析腾讯招聘API返回的JSON数据jsonpath库提取嵌套字段(如$..RecruitPostName定位岗位名称)
三、数据存储(MongoDB)
- PyMongo操作
MongoClient连接数据库db.insert_one插入文档到tencent_job_info集合
目标网址:搜索 | 腾讯招聘
1.导入所需模块
# 导入所需模块
import requests
import jsonpath
import pymongo
from multiprocessing import Process, JoinableQueue as Queue2.分析网页
这里教一个小技巧判断网页是不是静态数据或者动态数据
随便定位到一个数据,然后把下面定位到的数据进行复制
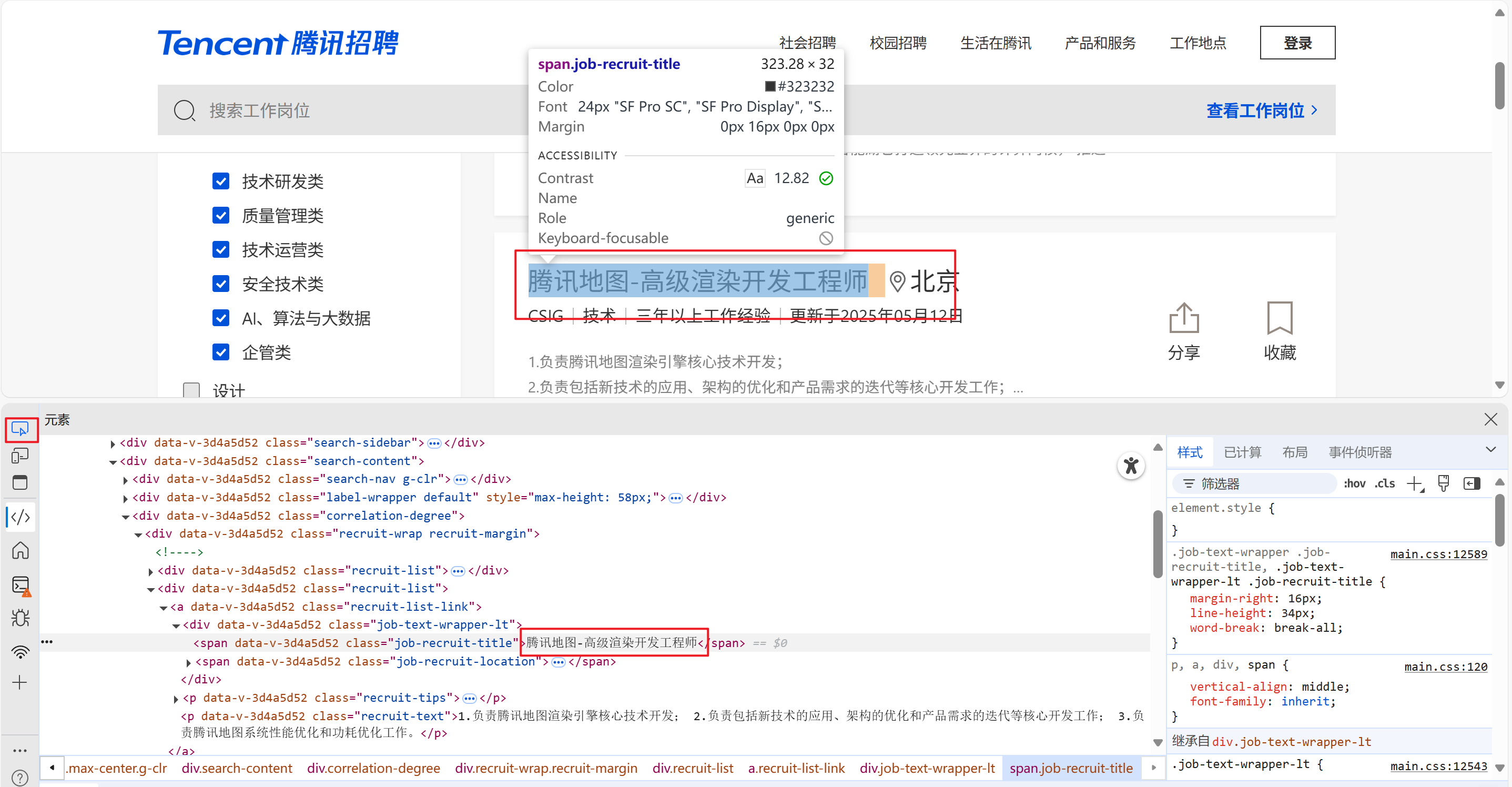
然后查看源码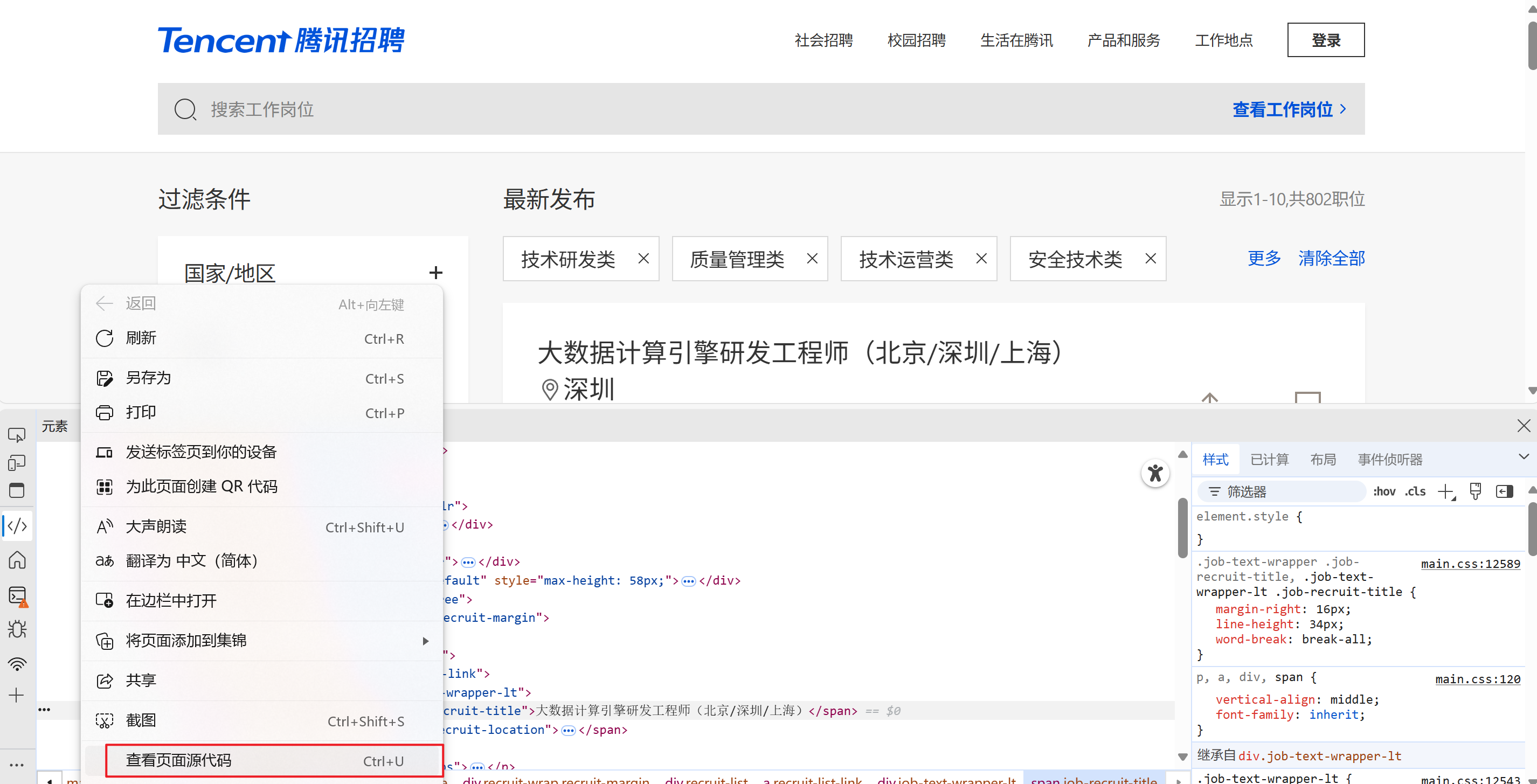
Ctrl+f:搜索 源代码里面没有复制的数据,说明是动态数据,反之静态数据
那么怎么快速分析接口呢
选择网络,页面滑到最下面,然后清除数据,点击第二页
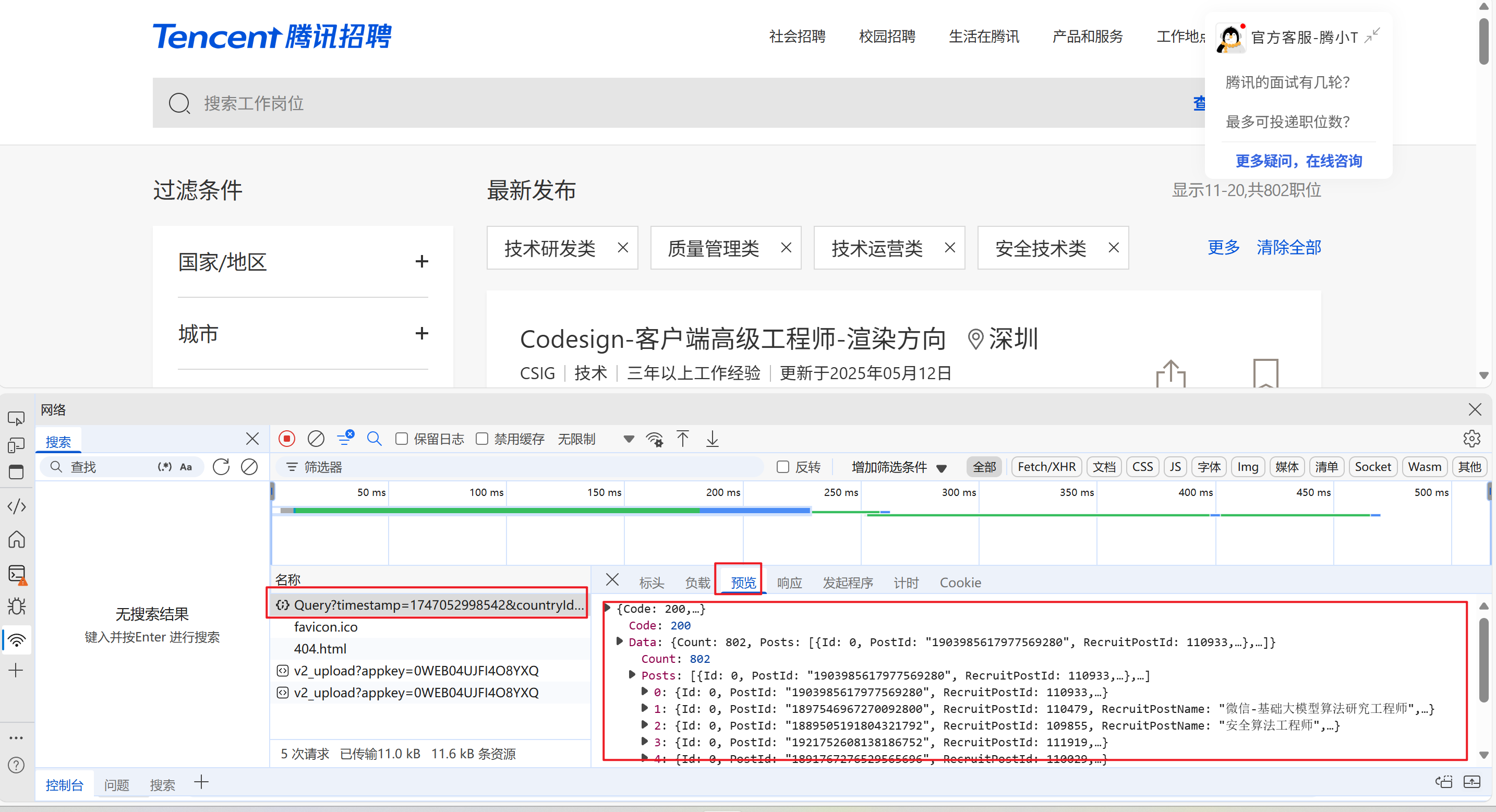
这里就使用一个工具吧------爬虫工具库
下面是怎么使用
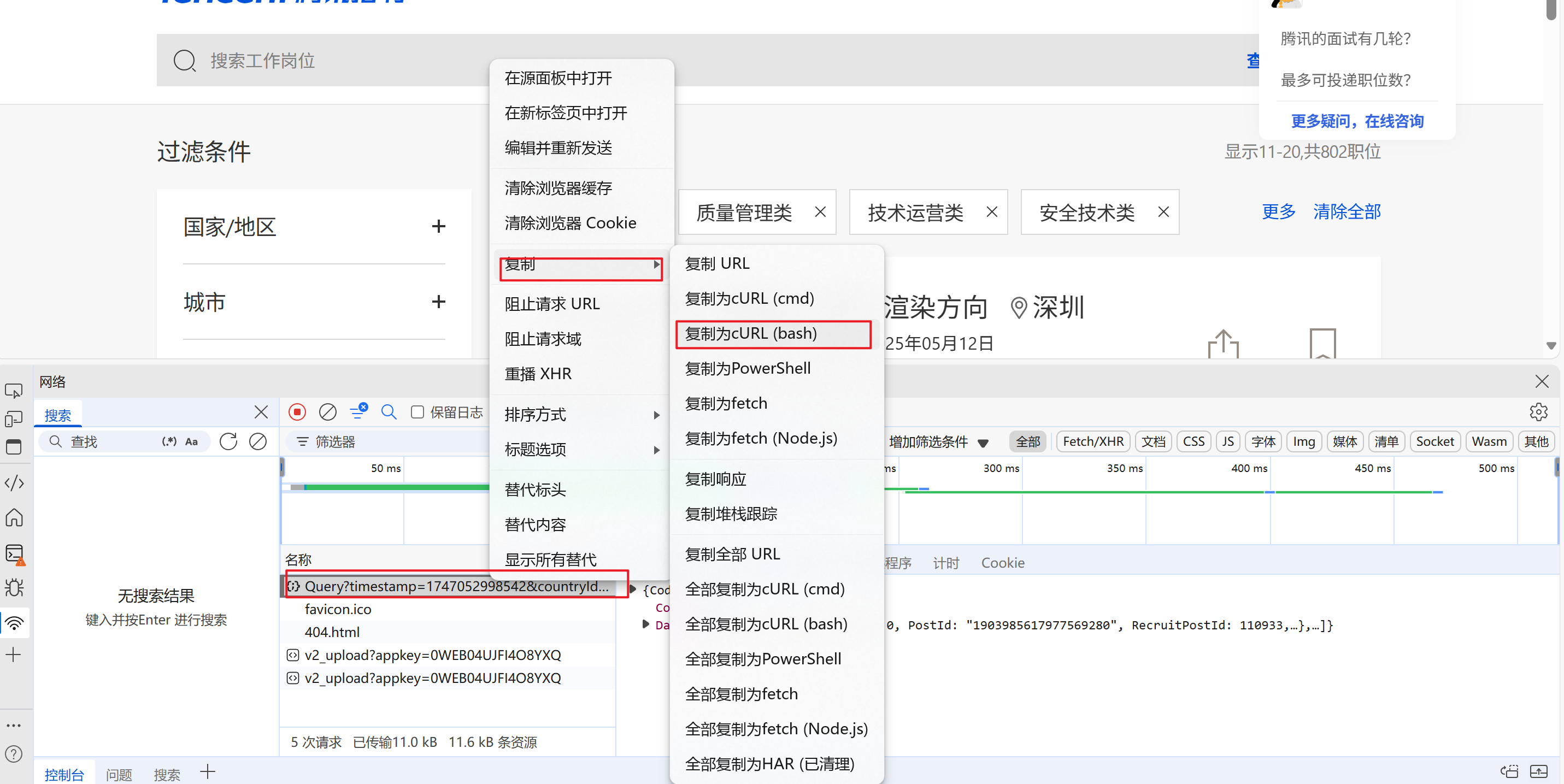
右边就是爬虫工具库替我们写的,可以直接拿来运行
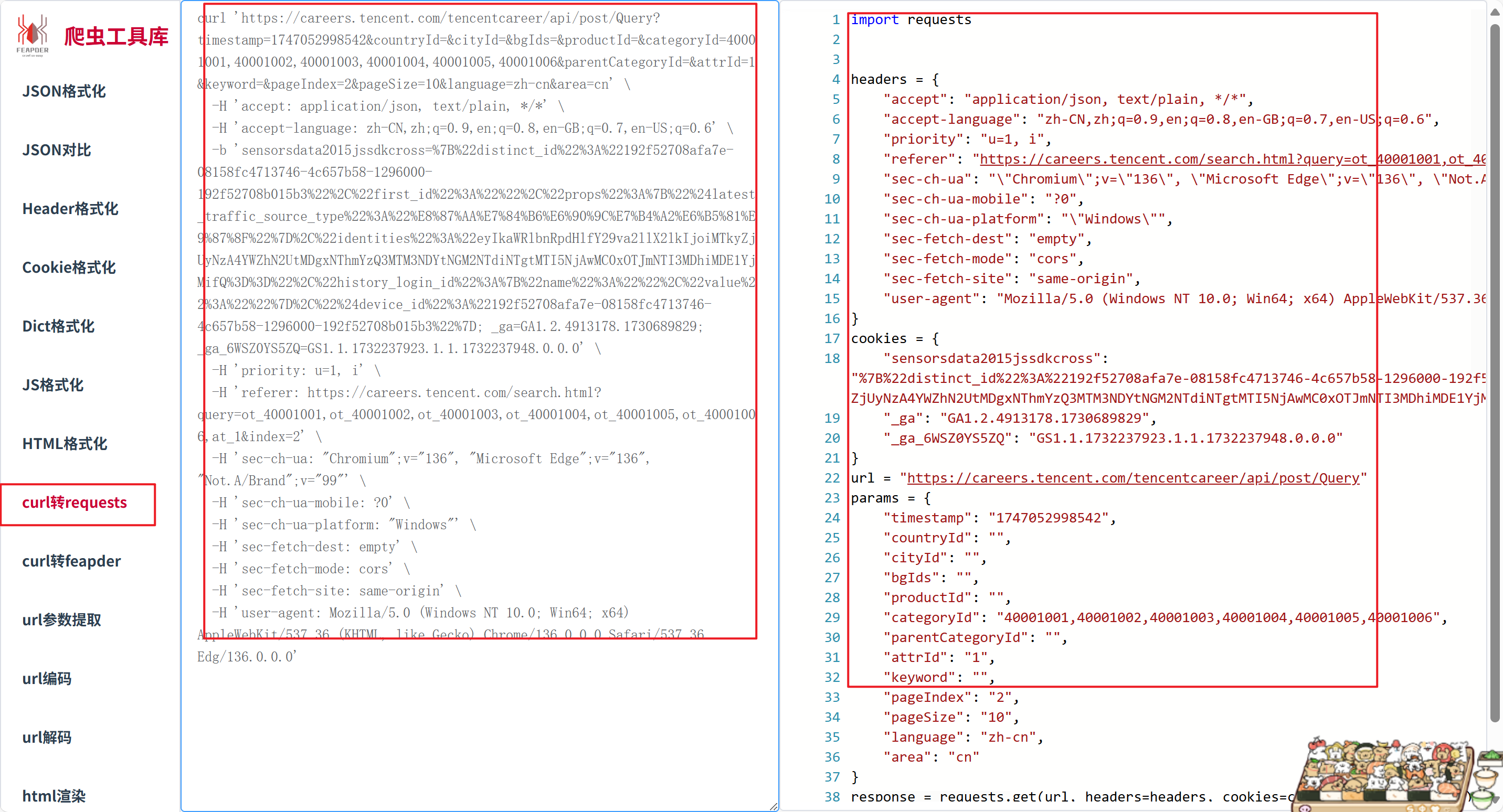
这里先简单拿他的url
url = "https://careers.tencent.com/tencentcareer/api/post/Query"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"
}创建MongoDB连接(默认本地)
mongo_client = pymongo.MongoClient()
db = mongo_client['py_spider']['tencent_job_info']创建一个网络请求函数
params在爬虫工具库里面拿出来的,注意 pageIndex是换页
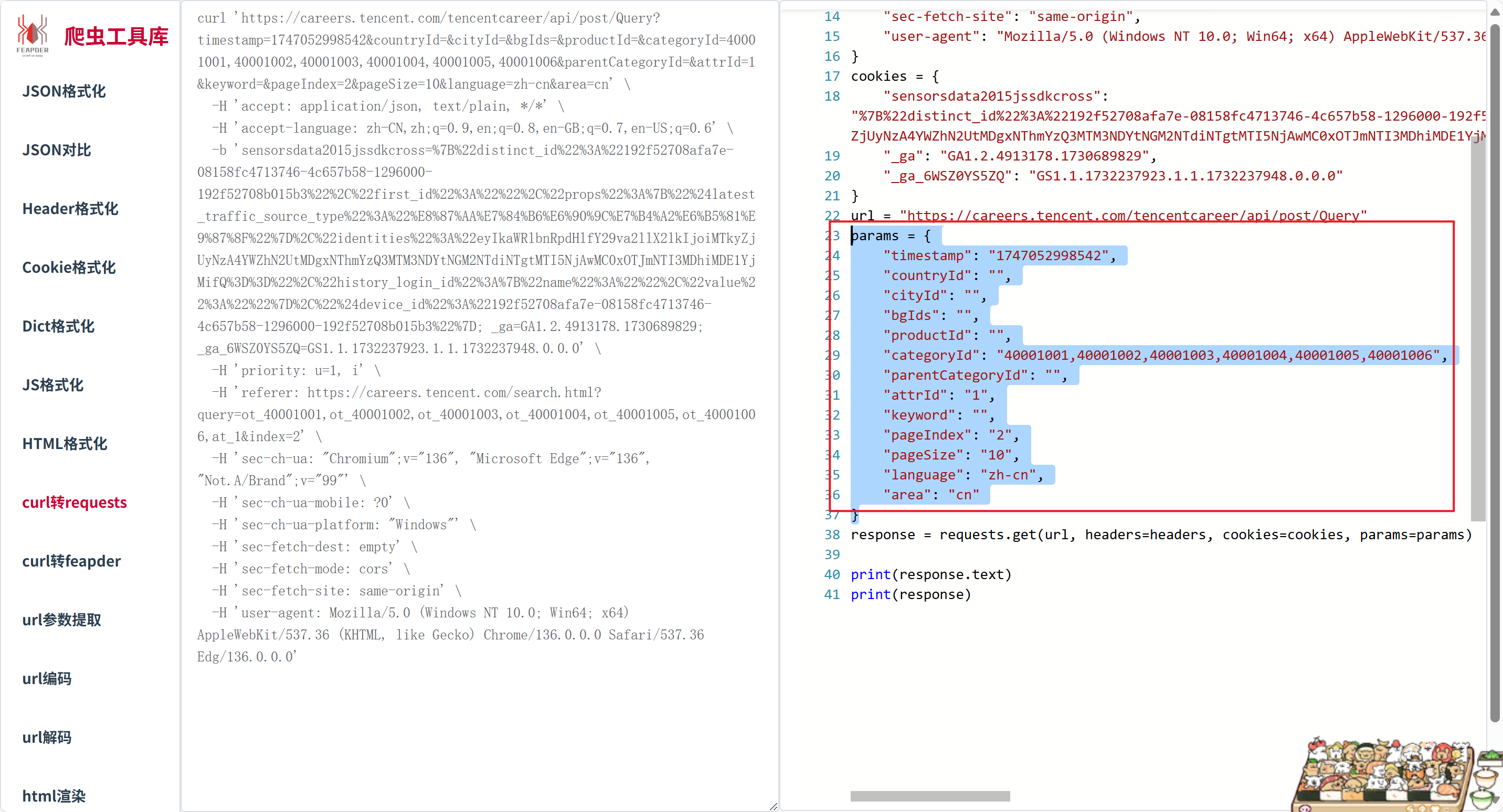
jsonpath很简单直接获取数据,同时有的数据可能不存在,使用了try方法返回不存在的数据,防止报错。
def get_work_info(page_num, queue):
params = {
"timestamp": "1747052998542",
"countryId": "",
"cityId": "",
"bgIds": "",
"productId": "",
"categoryId": "40001001,40001002,40001003,40001004,40001005,40001006",
"parentCategoryId": "",
"attrId": "1",
"keyword": "",
"pageIndex": page_num,
"pageSize": "10",
"language": "zh-cn",
"area": "cn"
}
response = requests.get(url=url, params=params, headers=headers).json()
try:
for info in response['Data']['Posts']:
work_info_dict = dict()
work_info_dict['recruit_post_name'] = jsonpath.jsonpath(info, '$..RecruitPostName')[0]
work_info_dict['country_name'] = jsonpath.jsonpath(info, '$..CountryName')[0]
work_info_dict['location_name'] = jsonpath.jsonpath(info, '$..LocationName')[0]
work_info_dict['category_name'] = jsonpath.jsonpath(info, '$..CategoryName')[0]
work_info_dict['responsibility'] = jsonpath.jsonpath(info, '$..Responsibility')[0]
work_info_dict['last_update_time'] = jsonpath.jsonpath(info, '$..LastUpdateTime')[0]
queue.put(work_info_dict)
except TypeError:
print('数据不存在:', params.get('pageIndex'))创建保存函数
队列一般都是耗时操作,get方法获取上面的数据,通过db保存到MongoDB,然后结束
def save_work_info(queue):
while True:
work_info_dict = queue.get()
db.insert_one(work_info_dict)
print('数据插入成功', work_info_dict)
# 如果队列为空,则结束进程
queue.task_done()最后启动函数有些复杂我一步一步说
写main回车这个方法

第一步实例化队列
dict_info_queue = Queue()第二步创建一个列表用来接收进程
process_list = []第三步写一个for循环,循环38次,页码也是从1到38,最后加入列表中
for page_num in range(1, 39):
p = Process(target=get_work_info, args=(page_num, dict_info_queue))
process_list.append(p)第四步创建一个进程来进行保存函数
p_save_work = Process(target=save_work_info, args=(dict_info_queue,))第五步遍历启动进程
for p in process_list:
p.start()第六步把保存进程设置守护进程,并启动
p_save_work.daemon = True
p_save_work.start()第七步让进程插队
for p in process_list:
p.join()第八步 结束总进程释放资源与MongoDB连接
dict_info_queue.join()
print('任务已完成...')
mongo_client.close()总体函数
if __name__ == '__main__':
dict_info_queue = Queue()
process_list = []
for page_num in range(1, 39):
p = Process(target=get_work_info, args=(page_num, dict_info_queue))
process_list.append(p)
p_save_work = Process(target=save_work_info, args=(dict_info_queue,))
for p in process_list:
p.start()
p_save_work.daemon = True
p_save_work.start()
for p in process_list:
p.join()
dict_info_queue.join()
print('任务已完成...')
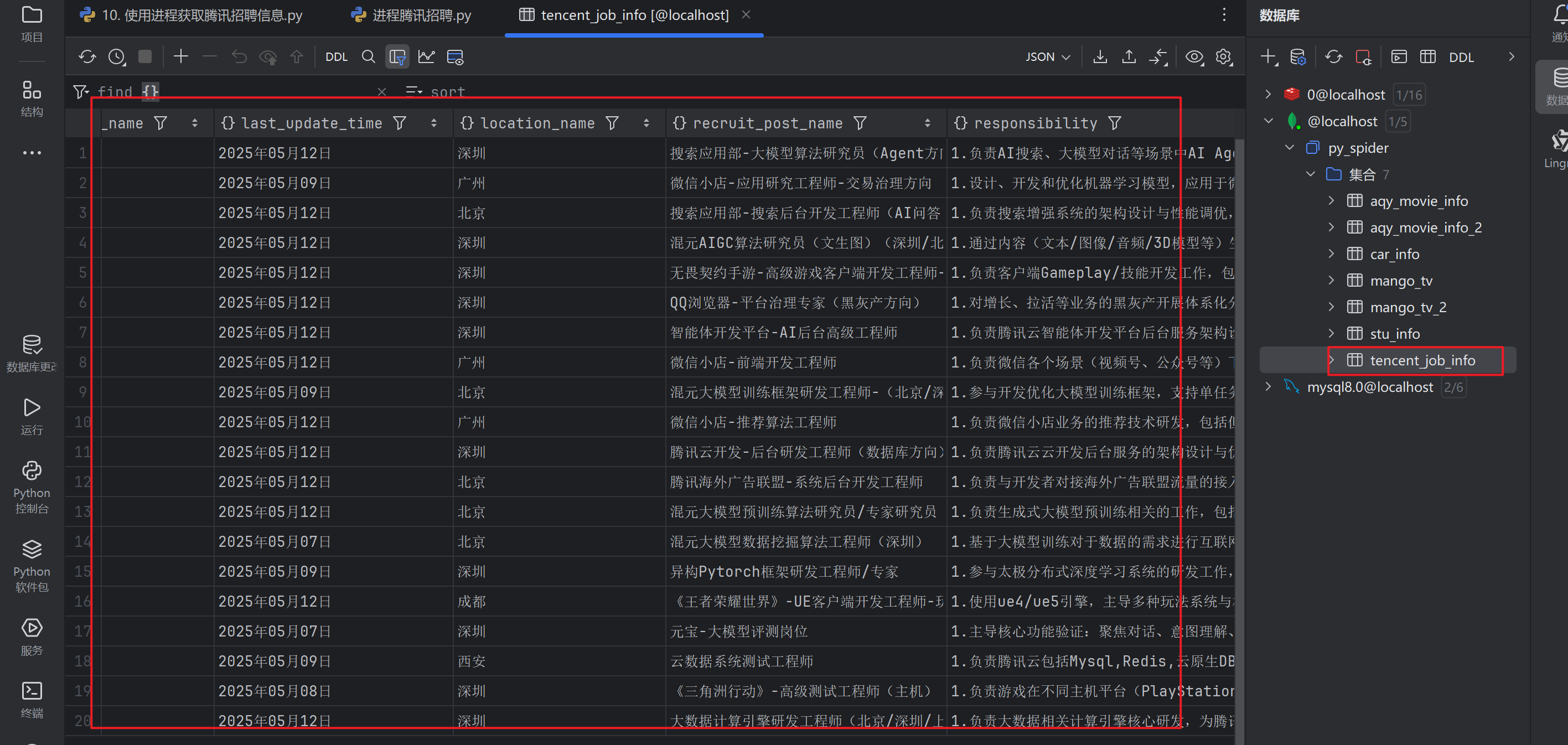
mongo_client.close()运行展示
 MongoDB展示
MongoDB展示


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









