






爬虫开发中,线程(Threading)是提升效率和性能的核心技术之一,尤其在处理I/O密集型任务(如网络请求)时表现突出。
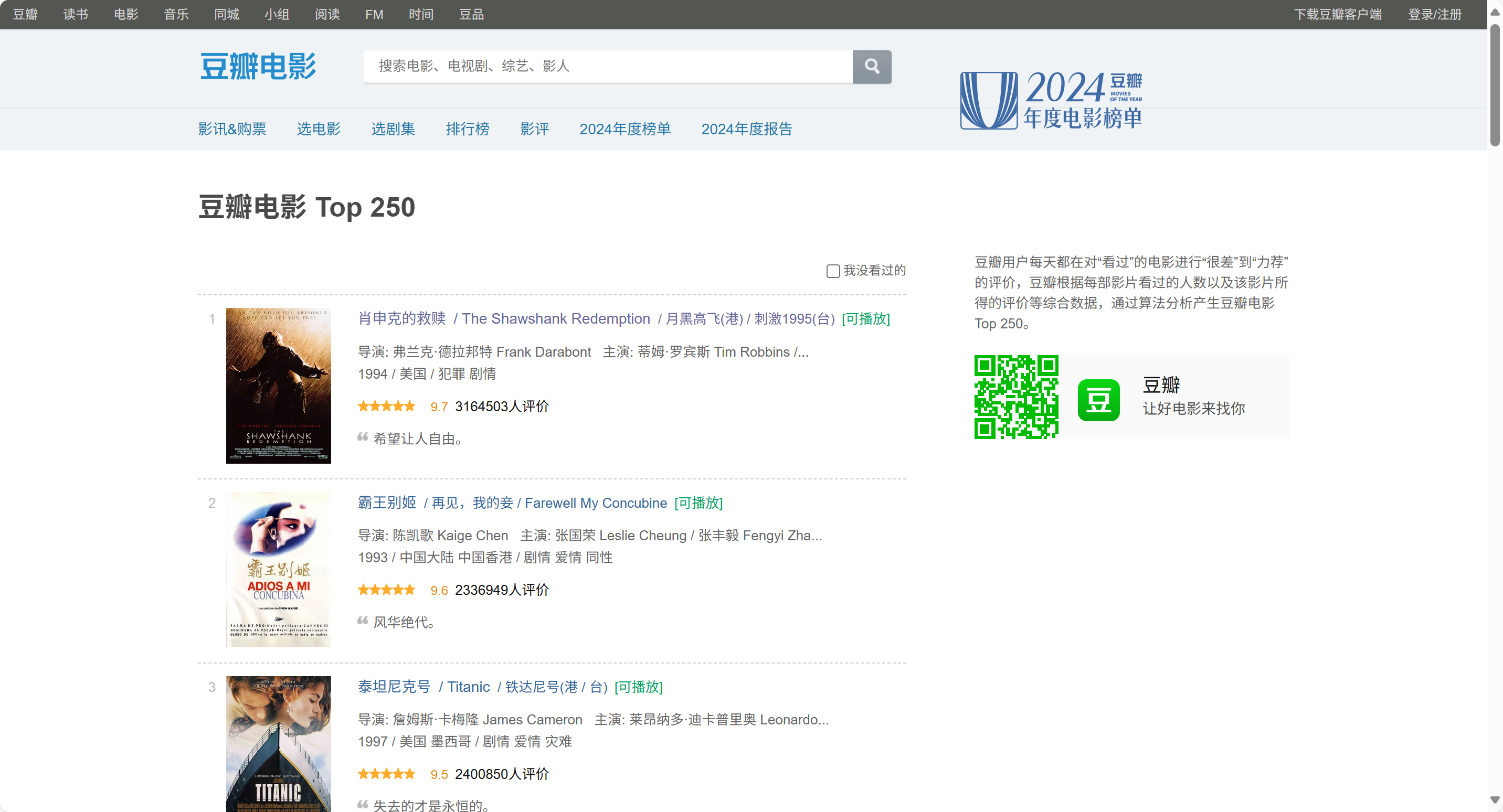
今天的目标网址:https://movie.douban.com/top250?start=0&filter=
1. 导入所需模块
import requests
import threading
from lxml import etree2. 分析网址与请求头
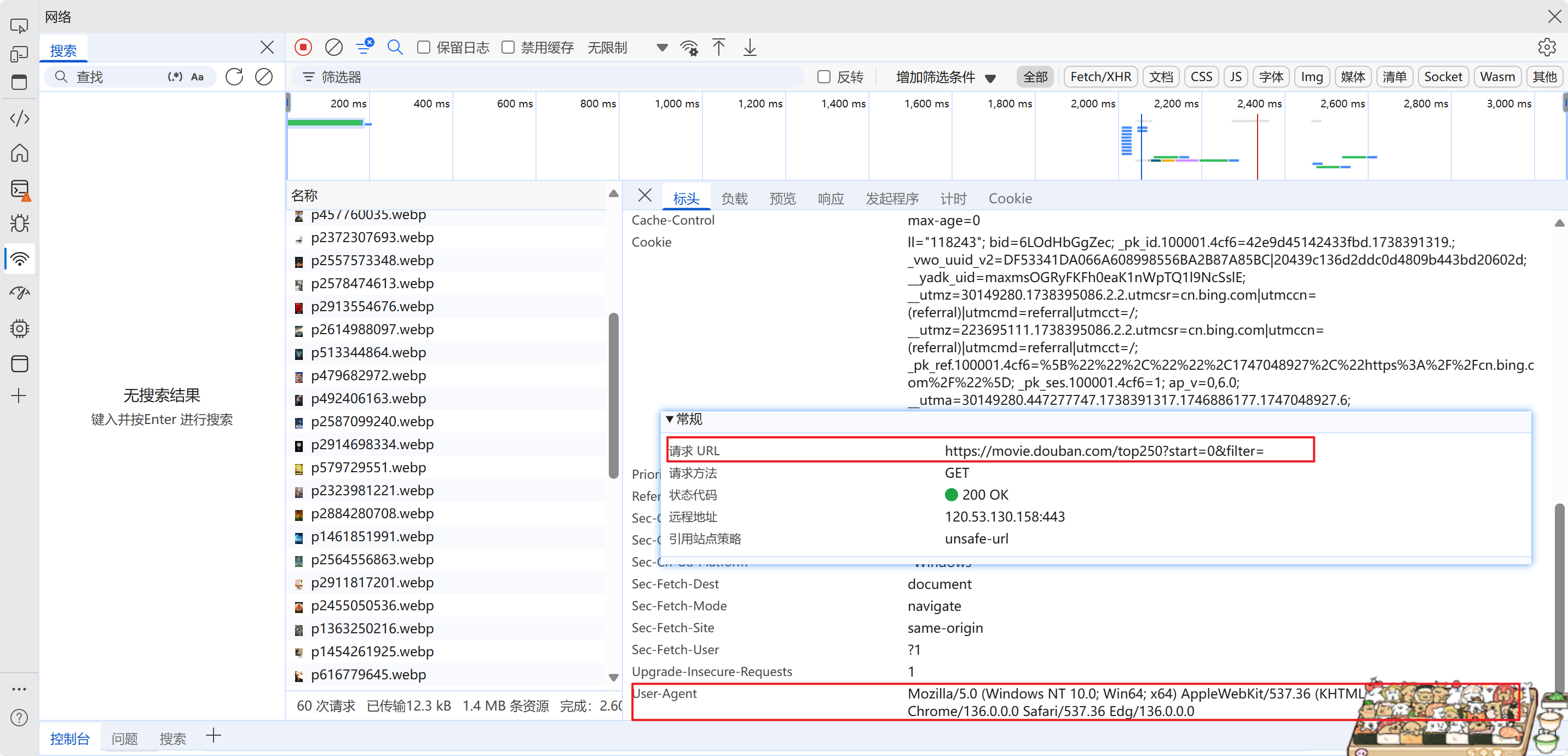
这里对比第一页与第二页的网址
可以看到start=0是第一页,start=25是第二页,每次递增25就是进行换页
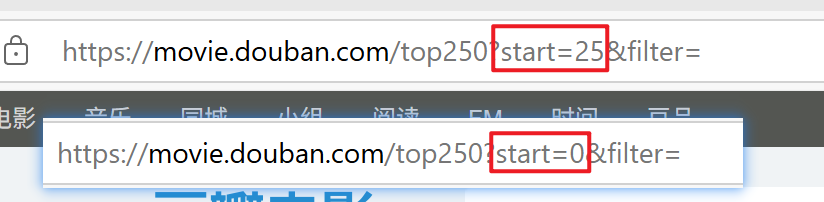
这里使用start={}动态获取
# 豆瓣电影Top250的分页URL模板,start参数表示起始位置(每页25条数据)
url = 'https://movie.douban.com/top250?start={}&filter='
# 请求头设置,模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}3.发送请求分析数据
很基础的发送请求与xpath分析
def get_movie_info(page_num):
response = requests.get(url.format(page_num * 25), headers=headers).text
html = etree.HTML(response)
movie_list = html.xpath('//div[@class="hd"]/a/span[1]/text()')
print(movie_list)4.启动函数,使用线程
threading_list是一个列表,调用线程threading.Thread方法,target方法传入请求函数,args传人page后面跟上循环10个。创建十个线程。然后遍历start执行即可。
注意:args参数接收是元组数据,所以后面加一个逗号
if __name__ == '__main__':
threading_list = [threading.Thread(target=get_movie_info, args=(page,)) for page in range(10)]
for thread in threading_list:
thread.start()5.运行结果
线程的特点:乱序
可以看到结果也是

6.完整代码
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
"""
@File :8. 线程获取豆瓣电影信息.py
@IDE :PyCharm
@Author :易辰的烂笔头
@Date :2025/5/12 00:54
"""
import requests
import threading
from lxml import etree
# 豆瓣电影Top250的分页URL模板,start参数表示起始位置(每页25条数据)
url = 'https://movie.douban.com/top250?start={}&filter='
# 请求头设置,模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
def get_movie_info(page_num):
response = requests.get(url.format(page_num * 25), headers=headers).text
html = etree.HTML(response)
movie_list = html.xpath('//div[@class="hd"]/a/span[1]/text()')
print(movie_list)
if __name__ == '__main__':
threading_list = [threading.Thread(target=get_movie_info, args=(page,)) for page in range(10)]
for thread in threading_list:
thread.start()

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









