






一、线程池核心作用
- 高效并发请求
- 通过复用固定数量的线程(如
max_workers=10),避免频繁创建/销毁线程的开销,显著提升爬虫的吞吐量。 - 示例:抓取1000个URL时,线程池可并行处理10个请求,理论耗时降至单线程的1/10(忽略网络延迟)。
- 通过复用固定数量的线程(如
- 资源可控性
- 限制最大并发数(如
ThreadPoolExecutor(5)),防止因线程过多导致:- 目标服务器封禁IP
- 本地内存/CPU过载
- 对比:直接创建1000个线程可能导致系统崩溃,线程池则自动排队任务。
- 限制最大并发数(如
- 任务管理简化
- 内置任务队列、异常捕获和结果回调机制,开发者只需关注业务逻辑(如解析HTML),无需手动管理线程生命周期。
今天的目标网址:豆瓣电影 Top 250
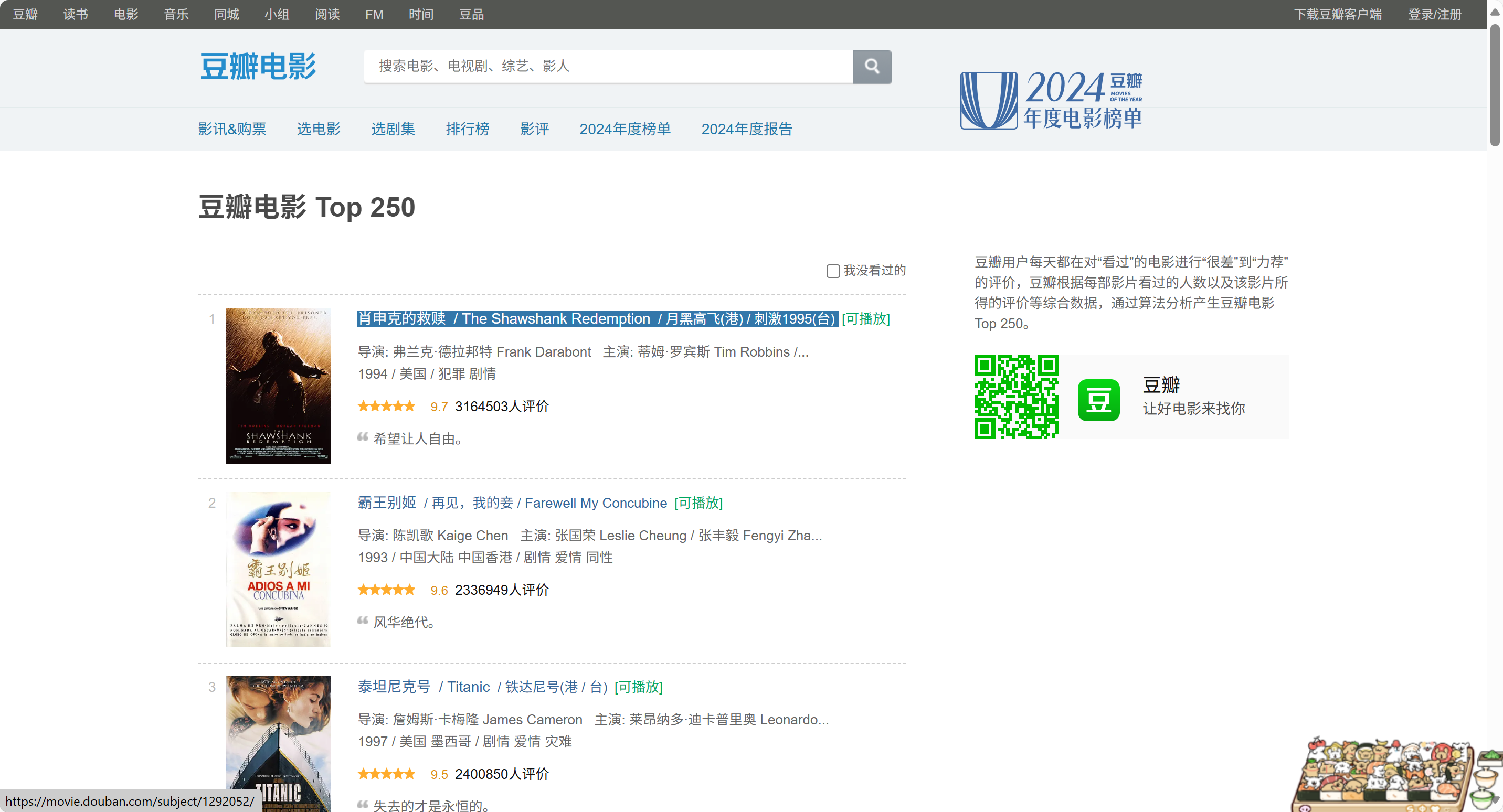
1.导入所需的模块
import requests
from lxml import etree
from concurrent.futures import ThreadPoolExecutor, as_completed2. 分析网址与请求头
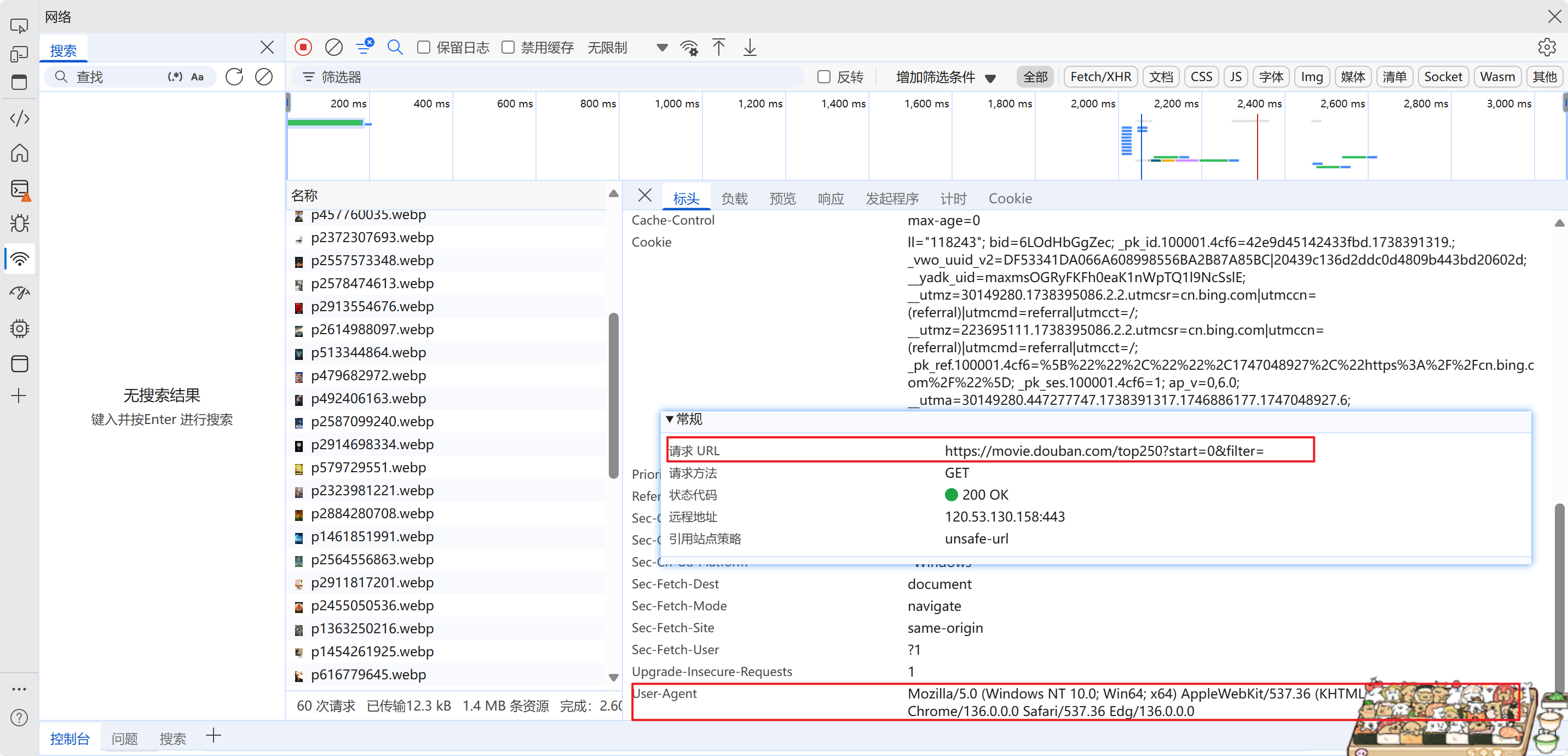
这里对比第一页与第二页的网址
可以看到start=0是第一页,start=25是第二页,每次递增25就是进行换页
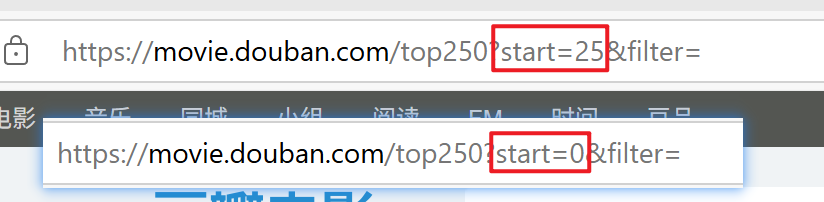
这里使用start={}动态获取
# 豆瓣电影Top250的分页URL模板,start参数表示起始位置(每页25条数据)
url = 'https://movie.douban.com/top250?start={}&filter='
# 请求头设置,模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}3.发送请求分析数据
很基础的发送请求与xpath分析
def get_movie_info(page_num):
response = requests.get(url.format(page_num * 25), headers=headers).text
html = etree.HTML(response)
movie_list = html.xpath('//div[@class="hd"]/a/span[1]/text()')
# print(movie_list)
return movie_list
# 将解析结果返回给其他函数使用4.启动函数
创建线程池,并使用线程池执行任务 max_workers=5 表示最多同时执行5个任务
as_completed:增加性能
if __name__ == '__main__':
# 创建线程池,并使用线程池执行任务 max_workers=5 表示最多同时执行5个任务
with ThreadPoolExecutor(max_workers=5) as pool:
# 通过线程池的 submit 方法提交任务
futures = [pool.submit(get_movie_info, page_num) for page_num in range(10)]
for future in as_completed(futures):
# 获取每个任务的结果
result = future.result()
print(result)5.运行结果

6.完整代码
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
"""
@File :9. 使用线程池获取豆瓣电影信息.py
@IDE :PyCharm
@Author :易辰的烂笔头
@Date :2025/5/12 16:36
"""
import requests
from lxml import etree
from concurrent.futures import ThreadPoolExecutor, as_completed
# 豆瓣电影Top250的分页URL模板,start参数表示起始位置(每页25条数据)
url = 'https://movie.douban.com/top250?start={}&filter='
# 请求头设置,模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
def get_movie_info(page_num):
response = requests.get(url.format(page_num * 25), headers=headers).text
html = etree.HTML(response)
movie_list = html.xpath('//div[@class="hd"]/a/span[1]/text()')
# print(movie_list)
return movie_list
# 将解析结果返回给其他函数使用
if __name__ == '__main__':
# 创建线程池,并使用线程池执行任务 max_workers=5 表示最多同时执行5个任务
with ThreadPoolExecutor(max_workers=5) as pool:
# 通过线程池的 submit 方法提交任务
futures = [pool.submit(get_movie_info, page_num) for page_num in range(10)]
for future in as_completed(futures):
# 获取每个任务的结果
result = future.result()
print(result)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









