



“达摩链接”生态系列讲座作为连接达摩院与学术界、产业界的社区活动,通过组织内外部的沙龙、讲座等形式,旨在促进前沿技术的分享交流,推动技术成果的转化、合作与应用落地。
为了让更多开发者、学术研发人员能够深入了解“达摩链接”生态系列讲座的分享内容,我们现将精彩要点整理成文。以下内容为分享人观点/研究数据,仅供参考,不代表本账号观点和研究内容。

背景
当前流行的生成式模型,其主要任务并非视频编码和评价。在视频处理领域,研究人员也在思考生成式模型是否有能力参与视频编码和质量评价的应用,并产生一定影响。
以 Sora 为代表的生成式模型已经能够生成比较逼真的视频画面场景,但这类生成式任务与视频编码有着很大区别。生成式模型输出画面时,只需要画面的质量接近人类想象的真实场景即可,并不需要像视频编码一样,需要较为准确地还原一段原始视频内容。
评价生成式模型的输出画质时,主要考察生成的画面与输入的提示内容是否匹配等要素,不需要将输出的画面与一段参考画面进行像素级对比,但在评价视频编码画质时需要这样做。尤其在诸如违章视频这样的应用中,编码输出的画面必须要足够准确地还原原始视频内容。
此外,视频编码过程非常看重编码消耗的资源,以及编解码开销是否能被编解码器覆盖,如果消耗的资源过多,不仅成本会升高,也可能会导致解码时画面卡顿等问题。

生成式模型参与的视频编码
论文:Chang, J., et al. (2022). Conceptual compression via deep structure and texture synthesis. IEEE Transactions on Image Processing, 31, 2809-2823.
视频编码研究通常先从图像编码入手。一张图像可以被分为结构层和纹理层,前者包含图像的轮廓信息,后者则包含纹理信息。
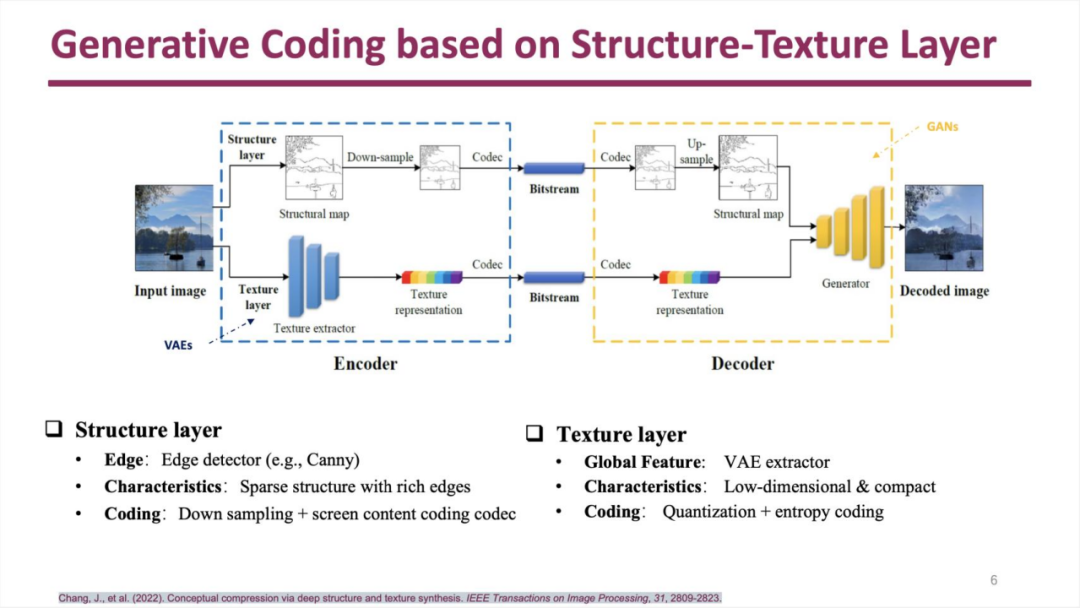
引入生成式模型后,可以在这两个层上分别加入内容生成步骤,结果可以较为明显地提升画面质量:

但生成式模型参与输出的画面存在一些“虚构”的痕迹,而常规的视频编码是不存在这样情况的。
与图像相比,视频画面更重视运动画面的质量。在运动画面中,人眼最敏感的对象是人脸,其次是人体,接下来是各类场景。只要能捕捉并提升这些对象的画面质量,就能很好地改进视频编码输出。
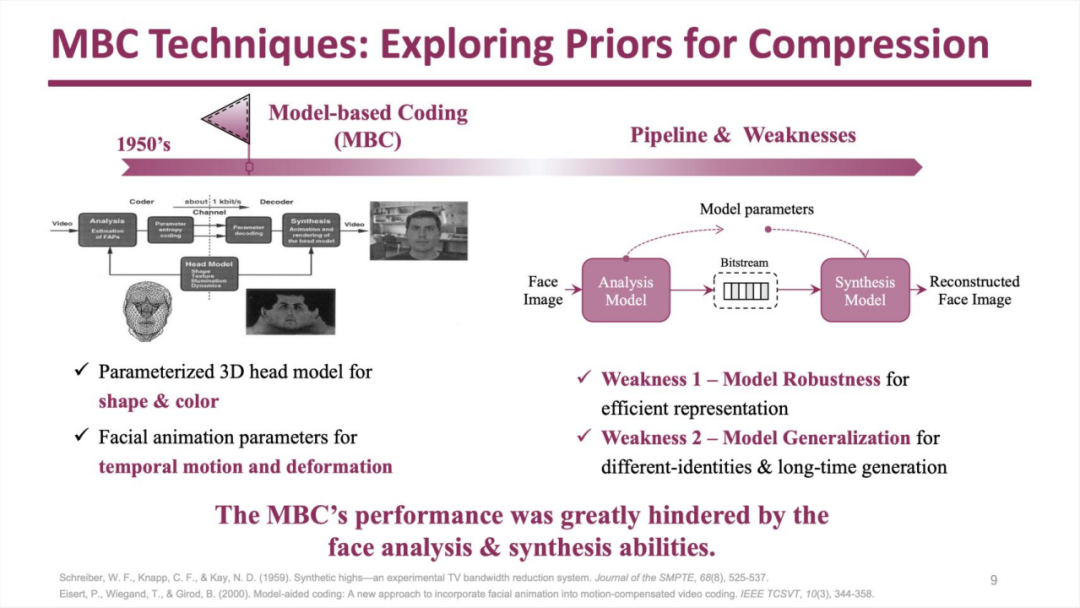
在基于人脸对象改进视频编码的研究中,1950 年就已经有了单独提取人脸进行 3D 建模,再将建模优化过的人脸图像与画面其余部分合成输出的研究。受限于当时的资源条件,这种方法没有推广开来。
随着深度学习技术的成熟,这类方法又得到了重视,只是当下的研究将 3D 建模步骤替换为用生成式模型来绘制画面。
视频可以被分为关键帧和中间帧,这种方法用传统编码器来编码关键帧,并使用生成式模型来处理从关键帧到中间帧的动作变换,生成关键帧上人脸对象的运动效果。
基于上述思想,有一些新的研究工作,包括
论文:Chen, B et al. Beyond keypoint coding: Temporal evolution inference with compact feature representation for talking face video compression. IEEE DCC 2022.
Chen, B et al. Compact Temporal Trajectory Representation for Talking Face Video Compression,“ IEEE TCSVT 2023
这些工作的第一部分是将人脸的动态过程提取成紧凑的特征(Compact Feature),第二部分则是在解码端生成密度流(Dense flow)等信息,最终合成输出画面。

将这种方法与传统编码器对比发现,某些质量评价标准下这种方法的效果更佳,但另一些标准下其质量并没有更好,原因是配色不对齐等问题。从主观对比来看,这种方法的效果是比较出色的:

除了提升画面质量外,这种方法还可以对画面中的人脸加入互动效果,例如更换发色、让对象眨眼等。
论文:Chen, B., Wang, Z., Li, B., Wang, S., Wang, S., & Ye, Y. (2023). Interactive face video coding: A generative compression framework. arXiv preprint arXiv:2302.09919.
下一项工作的目标是增强解码器的适应性。
论文:Yin S, et al. (2024). Enabling Translatability of Generative Face Video Coding: A Unified Face Feature Transcoding Framework. In 2024 DCC, IEEE
编码器输出的视频流可能因为各种原因而不被解码器识别:
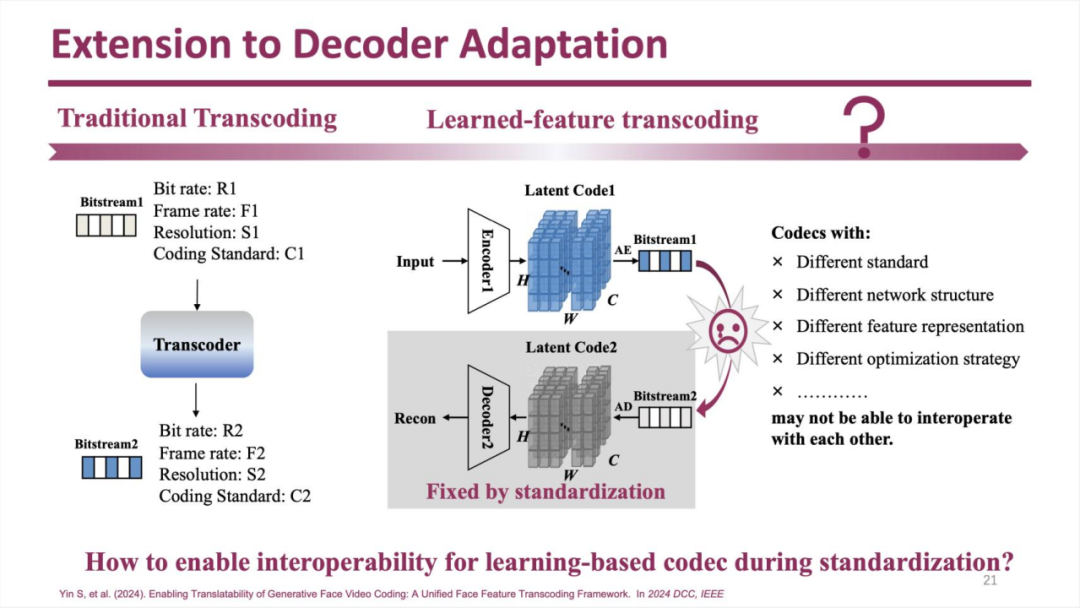
为了提升解码器的适应性,可以在解码器之前加入一个翻译器,使编码码流的图像特征更好地被解码器识别出来:

下一项工作的重点则是针对视频的机器分析场景。传统视频编码的通行假设认为人类是画面查看者,但在很多分析类场景中,分析视频画面的实际是机器。
而机器是通过画面特征来分析内容的,关注的重点与人眼不同。由于特征值所需的码率较低,因此针对这类场景可以向机器传递画面的特征值,而非压缩后的视频画面本身。
但机器对视频进行分析以后,工作人员也想抽取某些视频片段直接观看复核,使得需求更加复杂。一种方法是将人类需要观看的视频编码压缩后播放,但这样一来,新压缩的视频也会包含之前向机器传递的特征内容,出现了数据冗余。本篇工作的重点就是如何去除这样的冗余。
论文:Wang S., et al. “Towards Analysis-friendly Face Representation with Scalable Feature and Texture Compression,” TMM, 2022.
该方法将视频分为基础层和增强层,前者包含图像特征,后者包含图像纹理。两个层之间使用生成式模型进行交互:
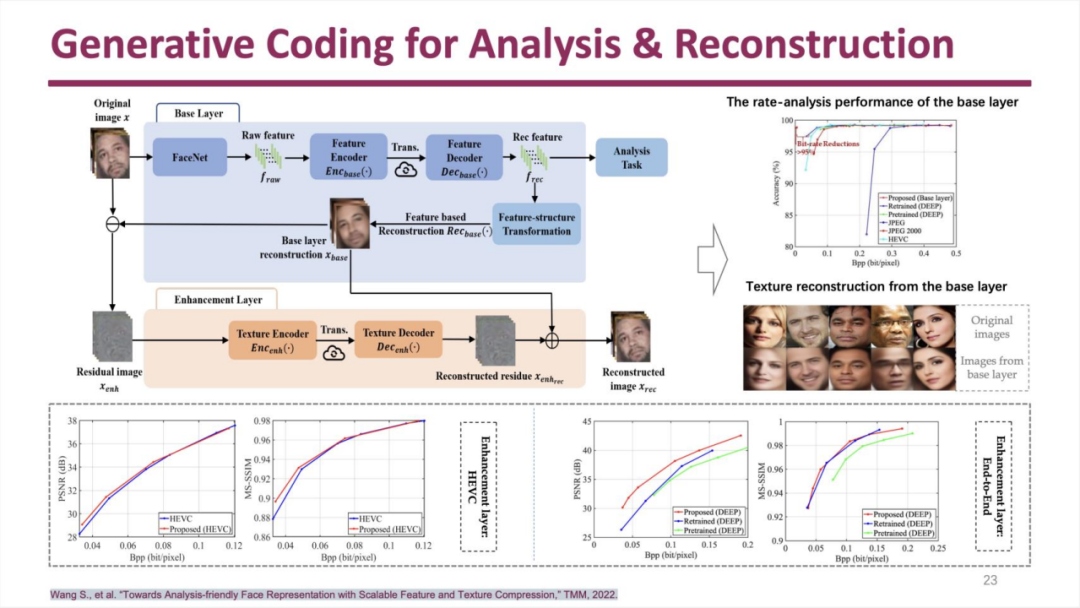
这种方法可以获得不错的码率节省效果,内容重建的质量也符合要求。进行上述研究时发现,对于主要包含人脸对象的视频进行编码的效果评估,目前缺乏一个良好的评估手段,团队也开发了一套系统性的评估方法:
论文:Li, Y., et al. (2024). Perceptual quality assessment of face video compression: A benchmark and an effective method. IEEE Transactions on Multimedia.

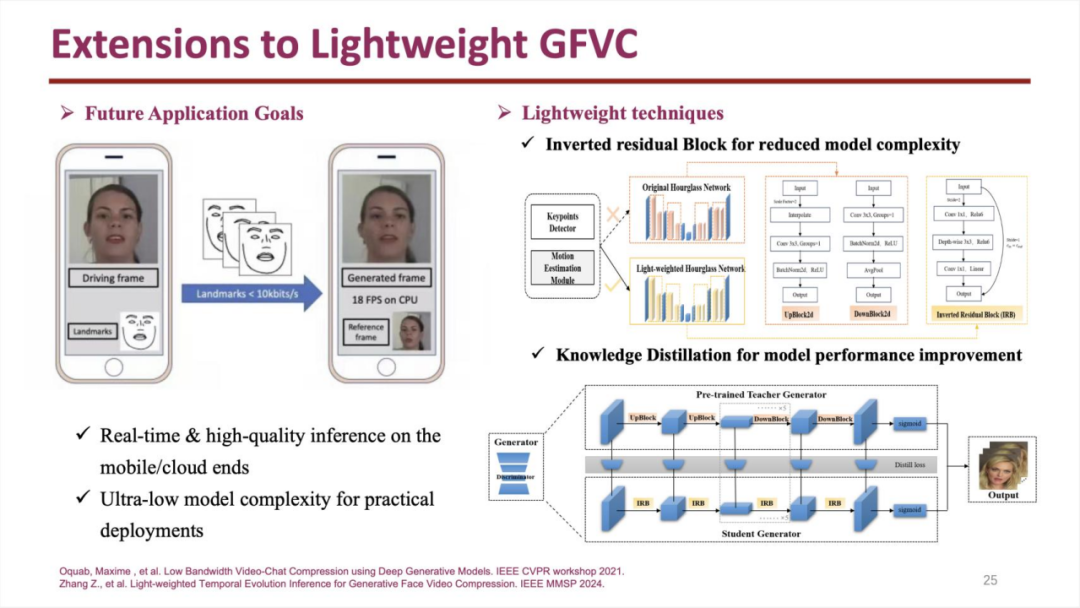
视频编码的另一个关注重点是编解码开销。可以通过降低生成式模型的大小等方法降低了解码性能需求:
论文:Oquab, Maxime , et al. Low Bandwidth Video-Chat Compression using Deep Generative Models. IEEE CVPR workshop 2021.
Zhang Z., et al. Light-weighted Temporal Evolution Inference for Generative Face Video Compression. IEEE MMSP 2024.
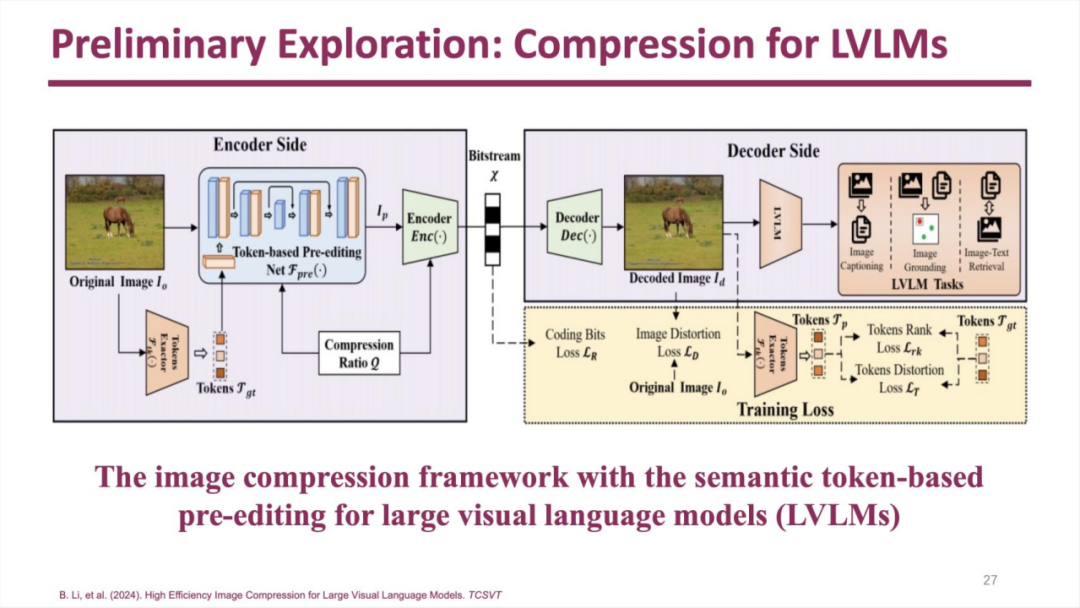
当视频最终的输出目标是大模型时,还可以采用一些适合大模型的压缩手段来有效降低码率:
此外,这项工作还研究了利用 Sora 一类的生成式模型来直接生成编码画面,节约码率,初步的尝试发现确实有一定的性能提升。
由上述研究可以看出,生成式模型在视频编解码领域有不错的应用潜力,但要充分挖掘这些潜力还要解决一系列挑战。除了将生成式模型应用在视频编码方面外,通过大模型来评估画面质量也是业内的一个研究方向。

使用大模型评估视频质量
大模型在很多领域都表现出了很强的应用潜力,而在视频画面质量评估方面,当前的大模型表现出了能力与人类相比是参差不齐的。

例如,对比一组高低质量的图片时,无论图片顺序如何,人类都能准确找出质量更高的一张,但大模型就可能只选择固定序号的一张。
基于上述现象的启发,团队提出了一种根据不同规则列举成对图片,让大模型判断质量的方法。

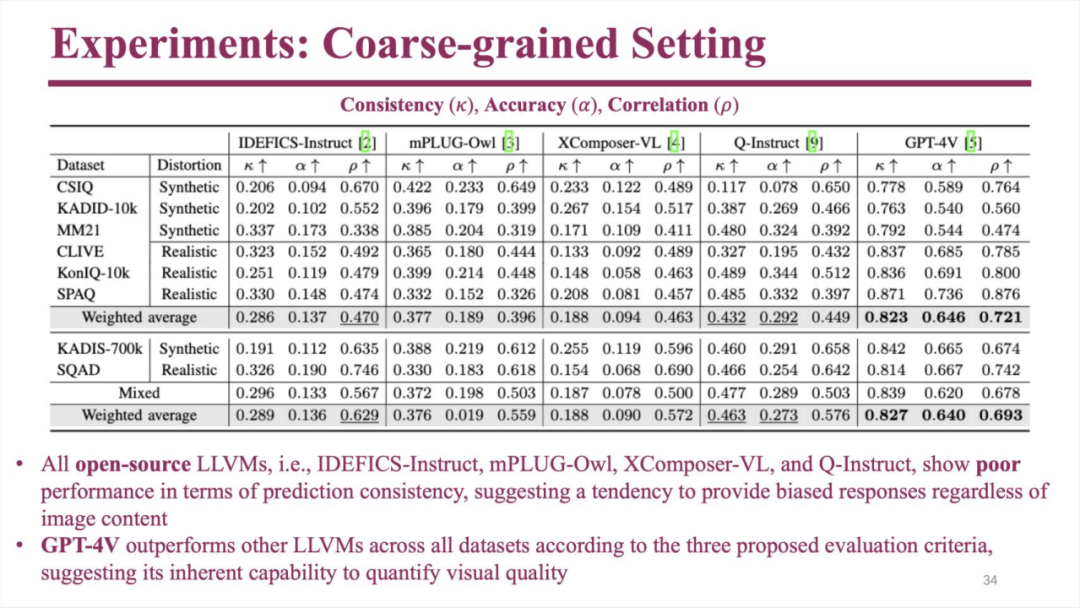
这种方法主要评价三个维度,首先是一致性,观察图片顺序调换后模型能否正确识别出来,判断标准是否受图片顺序影响;其次是准确性,观察模型能否达到和人类接近的判断能力;最后是相关性,观察模型给出的评分与 MOS 评分的相关性。
使用这种方法对比不同的模型发现,很多大模型的评价能力乏善可陈,但 GPT-4V 取得了较好的成绩。
下一项工作则受到了人类对图片质量评估现象的启发。研究发现,不同人对一组图片评估时,如果只是对单张图片独立打分,不同人给出的分数差异是较大的。但如果让每个人都对一组图片的质量排序,不同人的排序结果往往比较类似,显示更高的可靠性。同样的原理也可以用在大模型一侧,为大模型构建一个数据库来进行训练。

这个数据库通过这种方法训练出来的模型,可以在图片对比方面取得比其他模型更好的效果:
论文:H. Wu, H. Zhu, et al., “Towards Open-ended Visual Quality Comparison,” in ECCV, 2024

此外,虽然画面质量评估数据库有很多,但不同数据库中同样评估为“低、中、高”质量的画面,其实际 MOS 分数可以相差巨大。例如 A 数据库中一幅评价为“差”的图像的评分只有 1.1,B 数据库中同样评价为“差”的一幅图像评分却为 1.4,以此类推。
为此,下一项研究将每组对比图像之间的质量差异用五个级别来表示,并给出了具体的计算方式:

基于这五个级别就可以构建出一个更可靠的数据集,用来训练模型的质量评价能力。测试发现,这种方法的性能是当前业内最好的。
论文:H. Zhu et al., “Adaptive Image Quality Assessment via Teaching Large Multimodal Model to Compare,” NeurIPS, 2024

总结与展望
在大模型时代,行业非常关注如何将模型的能力应用在各个垂直领域。在视频编码领域,传统的编码技术主要考虑人类对画面的观感,但未来随着各个领域出现越来越多基于大模型的智能体、智能代理,这些智能体之间交互通信时也可能用到视频。
基于此,如何在交互通信过程中,根据智能体的感知特性来压缩、处理视频,实现较高的压缩率和质量是未来非常值得研究的主题。
作者介绍
王诗淇,香港城市大学计算机科学系副教授,博士生导师,目前担任人工智能视频处理领域旗舰期刊 IEEE TIP、TMM、TCyber 和 TCSVT 的编委。并获得多个国际会议和期刊的最佳论文奖,他的研究也获得国家自然科学基金委优秀青年科学基金项目和香港研究资助局杰出青年学者计划等多项项目资助。

















 1546
1546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









