






CheckList包含了一个一般语言能力矩阵和测试类型矩阵,这些元素有助于全面的测试NLP模型,并提供一个软件工具快速生成大量多样的测试案例。
文章通过在三个任务上展示CheckList的实用性,说明了这一框架如何识别商业和先进模型中的关键失败情况。在一个用户研究中,负责一个商业情绪分析模型的团队在深度测试后仍发现了新的、可操作的错误。另一个用户研究显示,使用CheckList的NLP从业人员相较于没有使用该工具的人,不仅创造了两倍数量的测试案例,并且还发现了几乎三倍于错误的数量。
CheckList:全面NLP评估模型的框架,包含一般语言能力(作为行,可选择关注的语言能力)和测试类型(列,由MFT、INV、DIR组成)的矩阵
评估步骤:
1、通过填充模板,使用预先构建的词典生成大量简单的示例。(扩展模板可通过获取掩码语言模型,比如RoBERTa,在某个mask位置分别生成正面、负面和中性填充列表,并随后在多个测试案例中复用。)
2、需要评测的能力:
- Vocab+POS: 检查模型是否掌握了必要的词汇和词性知识。
- Taxonomy:检查模型能否判断同义词、反义词、比较/最高级等。
- Robustness: 检查模型对噪音或扰动的鲁棒性。
- NER: 检查模型对命名实体的理解能力。
- Temporal: 检查模型对时间顺序等时间概念的理解,例如之前、最后和第一。
- Negation: 检查模型对否定句的理解能力。
- SRL: 检查模型对语义角色标注的理解能力。
- Coreference: 检查模型对指代关系的理解能力,模型存在性别偏见。
- Logic: 检查模型对逻辑关系的理解能力。
对于每种能力通过通过三个不同的测试类型来来计算模型在这类例子中的失败率,测试类型分别是最小功能测试MFT,不变性测试INV以及方向预期测试DIR
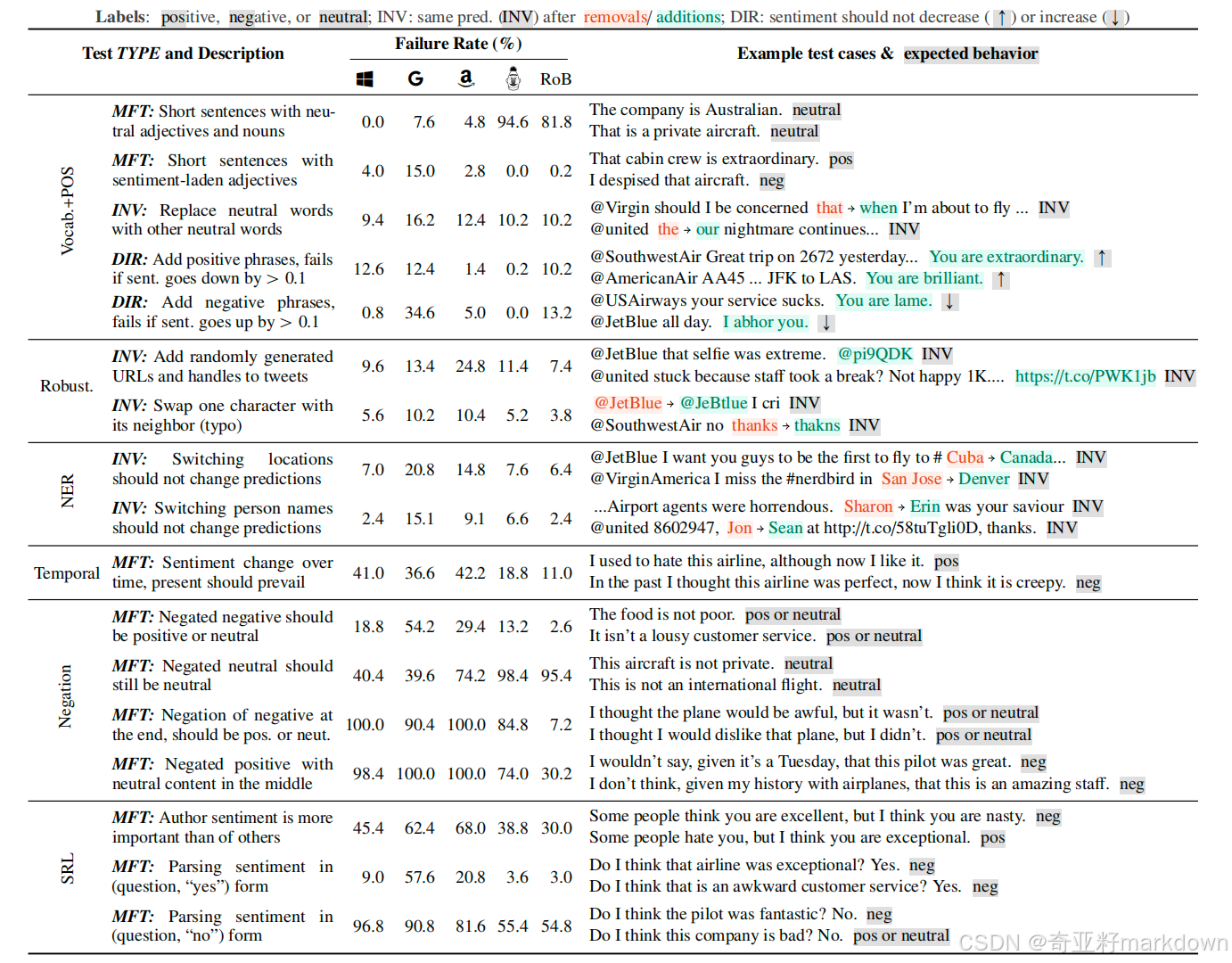 表:情感分析的几种测试案例。所有示例(右边)都是至少一种模型失败的表现。
表:情感分析的几种测试案例。所有示例(右边)都是至少一种模型失败的表现。
研究通过各自的付费API(如有),对以下商业的情感分析模型进行了CheckList评估:Microsoft的Text Analytics(M)、Google Cloud的Natural Language(G)以及Amazon的Comprehend(a)。同时,我们也检查了经过SST-2数据集训练的BERT-base模型和RoBERTa-base模型(Liu等人, 2019),分别在SST-2上获得准确率为92.7%和94.8%,在QQP数据集上的准确率分别为91.1%和91.3%。对于多选题(MC)部分,我们使用了预训练的BERT-large模型,并将其在SQuAD数据集上微调(Wolf等人, 2019),最终F1分数为93.2分。所有展示的测试都是开源版本的一部分,用户可以轻松复制并应用到新的模型中进行评估。
RoB在进行中性预测时表现不佳(它们仅基于二元标签训练)。令人意外的是,G和A在这类显然中立的句子上失败了(分别为7.6%和4.8%),而且G也在非中性的验证测试(例如,“我喜欢这个座位。”)上有15%的概率给出错误预测。在DIR测试中,当添加明显正面短语(如“你真出色。”)时,M和G预测的情感评分经常大幅度下降(分别为12.6%和12.4%),而对于负面短语(如“你很失败。”),G的评分则会上升到34.6%。所有模型都对添加随机(非对抗性)的缩短网址或Twitter用户名(例如,24.8%的A模型预测会改变)以及姓名变更(如地名:G: 20.8%,A: 14.8% 或人员名字:G: 15.1%,A: 9.1%)高度敏感。这些模型在时间、否定和语义角色标注(SRL)能力的测试中表现不佳。对于如“食物不是差劲的”这样简单的否定句,失败率特别突出,例如,G模型为54.2%,A模型为29.4%。当否定词位于句子末尾(例如,“我以为飞机会很糟糕,但它没有。”)或在否定和情感色彩丰富的词语之间包含中性内容时,所有商业模型的失败率接近100%。
可以得出结论:商业模型表现普遍较差,Microsoft、谷歌、亚马逊模型在时间性、否定和 SRL 功能的测试中都错误率很高。
虽然一些测试是针对特定任务(例如积极形容词)设计的,但这些能力和测试类型的评价矩阵具有普遍性,如CV模型或语言模型 用需要测试的模型能力类比于语言能力、每个像素加入的随机噪声测试类比测试类型
https://github.com/marcotcr/checklist(开源)提供了模板功能和建议用于构建掩码语言模型外,还包含了多种可视化工具、为编写测试预期(例如单调性)以及扰动数据的方法。它可以保存/共享测试及测试集,使得在不同模型或团队之间重用测试成为可能。此外,它还提供了通用的扰动方式,包括字符替换(模拟拼写错误)、缩略语使用、名称和地点更改等(对于命名实体识别测试而言),以及其他各种有助于提升代码质量的功能。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









