






链表的定义:
(1)链表的初始化
链表是一种线性数据结构,由一系列节点组成,每个节点包含数据和指向下一个节点的指针。每个节点都是通过指针相互连接的,形成一个链式结构。
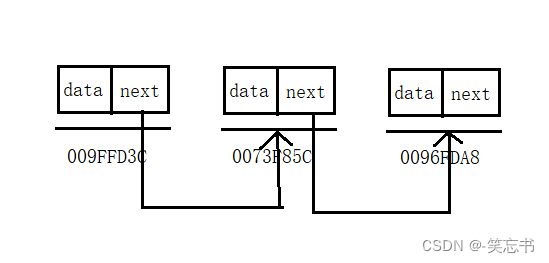
如图: 每个节点是以 next 指针相连,可以很直观的看到链表在物理上和在理论上都是不连续的。
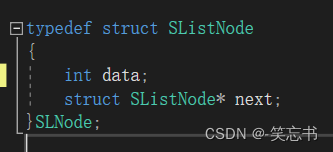
链表的定义方式如下:(其中data是用来存储有效数据,而 next 指针是指向下一个 节点 (也就是下图中的 struct SListNode)
(2)链表的增加操作
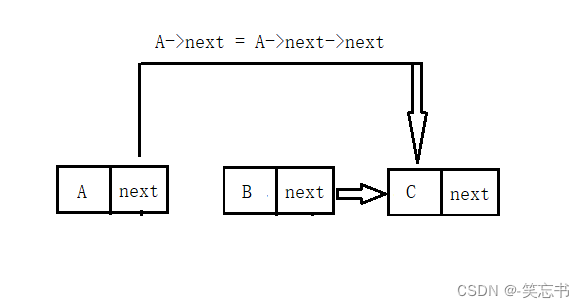
由于链表物理空间的不连续性,所以链表在进行增加操作时的效率是很高的。如下图:
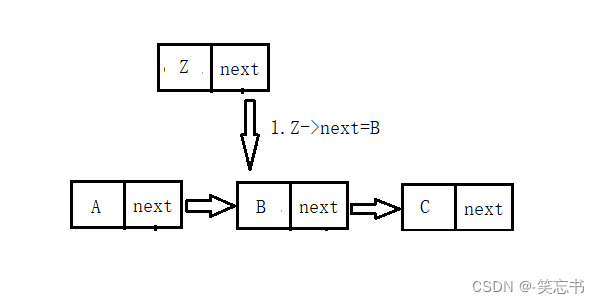
把节点 Z 增加到 节点 A 后面,只需两步即可。
1.将 Z 节点的 next 指针指向 B( 此时不能直接断开 A节点的 next指向,否则将会找不到 B 节点)
2. 将 A 节点的 next 指针指向 Z (这两步的顺序不能颠倒)
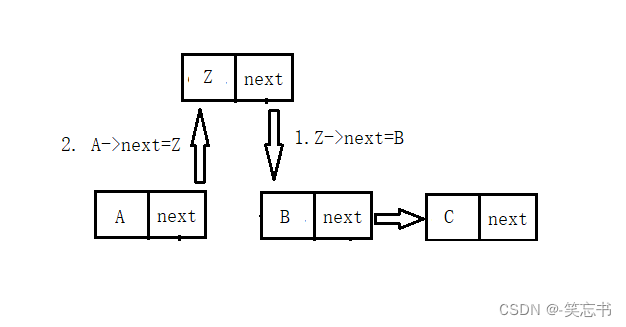
这样就完成了链表的增加操作。
(3)链表的删除操作
还是那句话:由于链表物理空间的不连续性,链表在进行删除操作时的效率是很高的。如下图:删除B 节点操作。也是非常简单,一步到位。
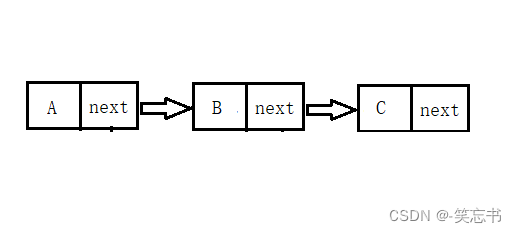
在更改 A->next 前,A->next是指向 B,所以 A->next = A->next->next 就是将 A 的 next 指针指向 节点 C. 此时 B节点就被架空了(删除了) 。( B 节点可以先存储起来,再让它的 next 指针指向 NULL)
(4)链表的查找操作
链表查找,我们看这个逻辑结构就知道,物理地址的不连续导致我们只能通过 指针 next ,从头开始查找 , 所以这个查找的效率是很慢的,这一点远远比不上 顺序表。
顺序表的定义:
(1)顺序表的初始化
顺序表是一种线性数据结构,它是由一组连续的存储单元(通常是数组)组成的数据结构。在顺序表中,数据元素之间的逻辑关系与物理关系是一致的,即相邻的元素在内存中也是相邻的。
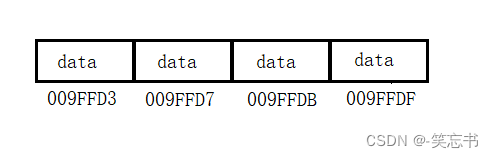
如图: 顺序表是需要开辟一段完整的空间,可以很直观的看到链表在物理上和在理论上都是连续的。(数组的物理空间和理论空间都是连续的)
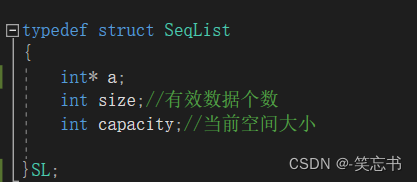
顺序表的定义方式如下: 为了避免初始化定义空间不足,采用 int*a 来定义数组,使得数组能够动态的开辟新空间,改变数组容量。
(2)顺序表的增加操作
若在顺序表的末尾增加节点,效率会嘎嘎高,但是若不在末尾增加就要考虑到移动节点的问题:
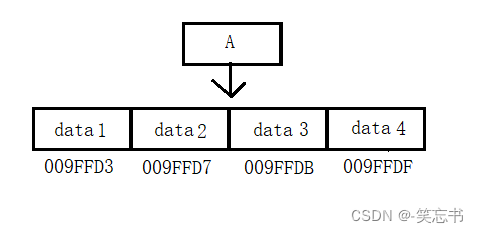
如图若想将节点 A 插入到地址为 009FFDB 的位置(data3之前),由于顺序表以数组实现,则需要移动 data3到data4的位置,这样才使得 A 能放到地址为 009FFDB 的位置。
这样已经相当繁琐了,加入我们是在数组头部插入 A 呢 ? 显而易见,顺序表中元素的移动将会更加频繁,这样大大的减少了代码效率;
(3)顺序表的删除操作
同样的,由于顺序表是以 数组 实现,在尾部删除数据非常简单,但是若不在末尾增加就要也考虑到移动节点的问题:
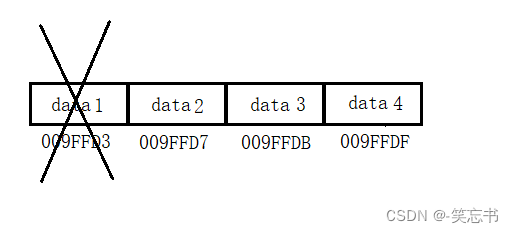
如图: 倘若删除 data1节点(即顺序表头节点),data1 之后的元素只能向前补位,倘若有 n 个元素,此时则要移动 n-1 次,可见顺序表的删除操作非常极端。
(4)顺序表的查找操作
我们可以通过下标元素来直接访问元素,从而对顺序表进行查找操作。我们只需控制下标,通过data来和目标值比对即可完成查找,最极端的情况就是遍历整个数组。倘若是有序的序列,查找操作的过程还会被大大简化。
对比:
单链表的优点:
1. 插入和删除操作方便快捷,只需修改指针即可。
2. 不需要预先分配存储空间,可以动态地分配和释放内存。
3. 可以方便地实现递归操作。
单链表的缺点:
1. 查找操作效率较低,需要遍历整个链表才能找到目标元素。
2. 无法直接访问前一个元素,需要从头开始遍历。
3. 需要额外的空间来存储指针信息。
顺序表的优点:
1. 查找操作效率高,可以通过下标直接访问元素。
2. 内存空间利用率高,不需要额外的指针存储空间。
3. 适合于静态数据集合,不需要频繁的插入和删除操作。
顺序表的缺点:
1. 插入和删除操作效率低,需要移动大量元素。
2. 静态分配内存空间,容量固定,无法动态扩展。
3. 插入和删除操作可能导致内存碎片化。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









