






前言
最近想拓展一下部署相关的操作!虽然目前很少使用libtorch进行部署了,但是还是去体验了一下。在网上查询了一些相关的操作,对于libtorch部署还是比较容易的,查询了相关的文档,模型的导出和前后处理都有现成的,剩余的基本就是环境搭建了!本文也就是记录一下整体的流程!
环境搭建
本文基础环境搭建于WSL2的Ubuntu20.04的环境,具体安装使用方式网络上还是比较详细。可以自行下载体验,建议安装完成后,导出到非C盘进行使用。
opencv的安装与下载
这里有两种安装方式
第一种:使用conda环境新建虚拟环境后,进行使用conda install 进行opencv的安装,conda会自行处理相关的依赖,安装完成后会在虚拟环境的目录下存放头文件和库文件,编译的时候记得正确链接即可。本文不重点介绍这种方式。
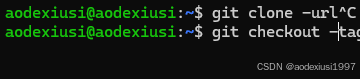
第二种:下载opencv的源码进行编译安装源码。链接可以在github或者sourceforge进行下载,本文推荐使用github进行安装下载https://github.com/opencv/opencv/releases/tag/4.10.0,可以将代码进行git clone,然后使用git checkout切换版本。编译前期需要很多的依赖,需要先apt好。
同时也给出opencv官方的指导安装文档链接Installation in Linux — OpenCV 2.4.13.7 documentation。
[compiler] sudo apt-get install build-essential
[required] sudo apt-get install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev
[optional] sudo apt-get install python-dev python-numpy libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libjasper-dev libdc1394-22-dev如果存在有无法下载的环境,可以参考相关的文档,此处给出我使用的博客,成功安装o( ̄▽ ̄)d!
或者直接下载对应版本的zip包(找到release发布)进行解压然后进行编译。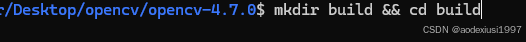

进行源码编译会有很多的拓展选项,如果开启过多非常容易在make阶段失败,因为编译过程会依赖一些其它的库文件,比如cuda相关,同时拓展编译可能还会涉及一些模块可能会依赖opencv_contrib,按照同样的方式下载对应版本到同一个文件夹中,然后在camke时进行指定文件路径。
建议体验的话只开启一些基础功能即可,如下参考:
cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D OPENCV_GENERATE_PKGCONFIG=ON \
-D OPENCV_PC_FILE_NAME=opencv4.pc \
.. \
其它的备选可以搜索了解这些功能以及对应依赖后进行选择:
cmake -D INSTALL_PYTHON_EXAMPLES=OFF \
-D INSTALL_C_EXAMPLES=OFF \
-D OPENCV_ENABLE_NONFREE=ON \
-D OPENCV_EXTRA_MODULES_PATH=<opencv_contrib文件夹路径> \
-D BUILD_NEW_PYTHON_SUPPORT=ON \
-D WITH_TBB=ON \
-D ENABLE_FAST_MATH=1 \
-D CUDA_FAST_MATH=1 \
-D WITH_CUBLAS=1 \
-D WITH_CUDA=ON \
-D BUILD_opencv_cudacodec=OFF \
-D WITH_CUDNN=OFF \
-D OPENCV_DNN_CUDA=OFF \
-D CUDA_ARCH_BIN=7.5 \
-D WITH_V4L=ON \
-D WITH_QT=OFF \
-D WITH_OPENGL=ON \
-D WITH_GSTREAMER=OFF \
-D WITH_FFMPEG=OFF \
-D WITH_OPENCL=ON \
-D ENABLE_PRECOMPILED_HEADERS=YES \
-D EIGEN_INCLUDE_PATH=/usr/include/eigen3 \
-D BUILD_EXAMPLES=OFF ..如果仍然需要构建cuda支持的opencv,此处给出一个链接,可以查看修改对应VERSION进行opencv构建tensorrt-cpp-api/scripts/build_opencv.sh at main · cyrusbehr/tensorrt-cpp-api
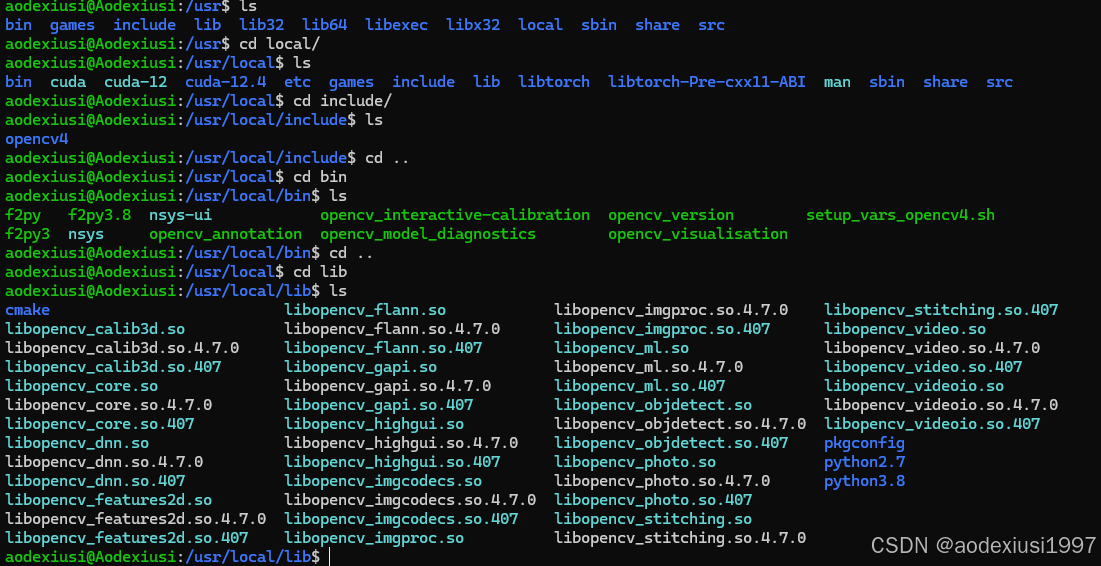
编译完成后文件夹就会放置在-D CMAKE_INSTALL_PREFIX=/usr/local \你设置的这个目录下面,也会在/usr里面找到相应的库文件
libtorch的安装与下载
首先这里的cuda和cudnn需要配置好,有很多教程,此处不详细展开。
libtorch可以直接下载torch官方提供的编译好的文件,但是要事先知道自己适合的版本,比如说我这里的版本就是需要下载cxx ABI版本才可以正常和Opencv一起编译,否则就会报错。具体原因,可以搜索 libtorch和opencv一起编译报错:undefined reference to `cv::imread。
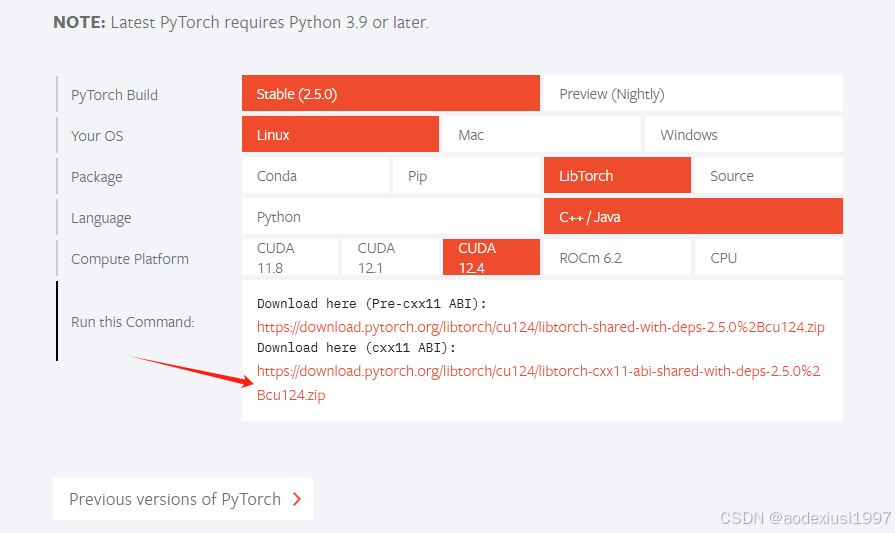
要下载之前的libtorch版本,可以自行搜索链接。我的cuda版本和libtorch版本是对应的都是cu124,只要你的libtorch-cuda版本不高于安装的显卡cuda版本且二者版本差距不大应该都能正常使用,此处如有错误请指出。还有看过一些博主文章推荐的是libtorch版本和导出torchscript的pytorch版本尽量保持一致。
将这个文件下载下来,然后直接进行解压,编译的时候只需要指定libtorch的头文件和库文件。

然后你就会在/usr/local看到文件夹libtorch,里面就会有相应的头文件和库文件。

代码编译测试
代码直接使用github里面的ultralytics官方测试代码进行验证,这里直接给出main.cpp和CMakeLists.txt的链接。ultralytics/examples/YOLOv8-LibTorch-CPP-Inference at v8.2.103 · ultralytics/ultralytics
编译的时候只需要修改cmakelists里面的libtorch的路径指定和main.cpp对应的yolov8导出的torchscripit权重和图片路径的路径即可(如果需要测试视频,只需要简单修改代码按照c++版本opencv读取视频,然后将图片放入模型进行推理)。如下:
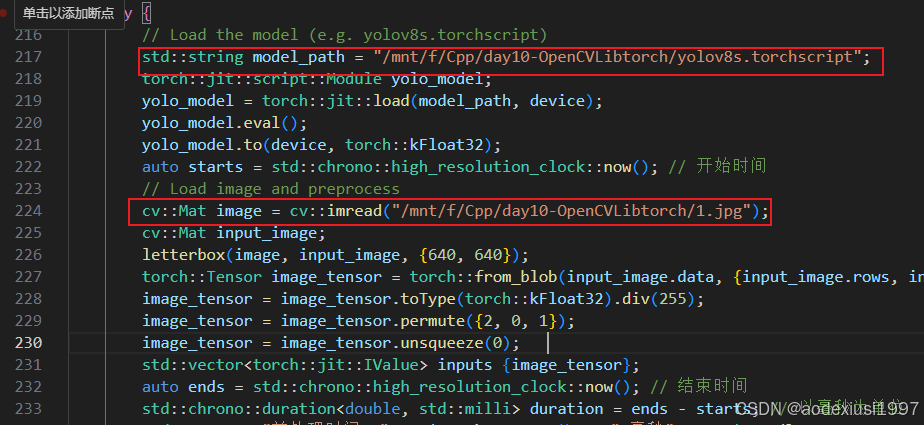
修改cmake版本 apt 直接安装的是3.16版本,使用高版本的需要自己下载
cmake_minimum_required(VERSION 3.16 FATAL_ERROR)
project(yolov8_libtorch_example)
set(CMAKE_CXX_STANDARD 17)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
set(CMAKE_CXX_EXTENSIONS OFF)
-----------------
编译器可能会涉及cuda相关编译报错,此处可以指定,可以先删除进行编译测试
# 设置 CUDA 的标准为 C++14
set(CMAKE_CUDA_STANDARD 14)
set(CMAKE_CUDA_STANDARD_REQUIRED ON)
-----------------
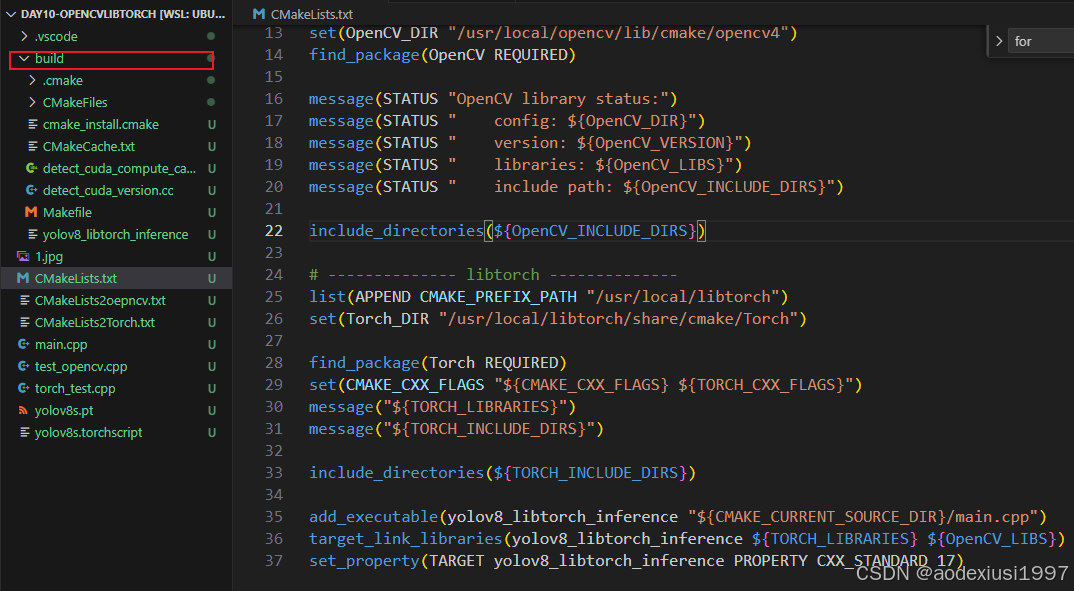
此处路径
# -------------- OpenCV --------------
set(OpenCV_DIR "/usr/local/opencv/lib/cmake/opencv4")
find_package(OpenCV REQUIRED)
message(STATUS "OpenCV library status:")
message(STATUS " config: ${OpenCV_DIR}")
message(STATUS " version: ${OpenCV_VERSION}")
message(STATUS " libraries: ${OpenCV_LIBS}")
message(STATUS " include path: ${OpenCV_INCLUDE_DIRS}")
include_directories(${OpenCV_INCLUDE_DIRS})
此处路径
# -------------- libtorch --------------
list(APPEND CMAKE_PREFIX_PATH "/usr/local/libtorch")
set(Torch_DIR "/usr/local/libtorch/share/cmake/Torch")
find_package(Torch REQUIRED)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${TORCH_CXX_FLAGS}")
message("${TORCH_LIBRARIES}")
message("${TORCH_INCLUDE_DIRS}")
include_directories(${TORCH_INCLUDE_DIRS})
add_executable(yolov8_libtorch_inference "${CMAKE_CURRENT_SOURCE_DIR}/main.cpp")
target_link_libraries(yolov8_libtorch_inference ${TORCH_LIBRARIES} ${OpenCV_LIBS})
set_property(TARGET yolov8_libtorch_inference PROPERTY CXX_STANDARD 17)接着在,终端中的对应文件夹位置 mkdir build && cd build && cmake .. && make -j8 && ./yolov8_libtorch_inference
最终就可以看到想要的输出了。到此简单部署验证体验libtorch就结束了,当然还可以体验用它相应的接口来训练等等,哈哈哈,应该很少人用吧。后面给出测试结果。cuda启动时间太长了588ms,1660、没有量化、float32、yolov8s。

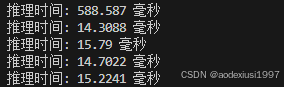
这是刚刚开始的时间,运行后很快会稳定在 前处理 1ms 推理 15ms 后处理1ms 左右。

















 2453
2453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









