







C++模型部署通常指的是将训练好的机器学习模型应用于生产环境中。以下是使用C++进行模型部署的一些优势:
-
性能:C++代码通常比Python等解释性语言运行速度更快,这使得C++成为部署模型的一种高性能选择。
-
平台兼容性:C++代码可以在不同的操作系统上编译,并且可以被编译成本地代码,这使得部署变得跨平台和设备容易。
-
低维护成本:C++代码通常维护成本较低,因为它的抽象级别较低,相比动态类型语言,修改和扩展代码更为直观和安全。
-
安全性:C++提供了内存安全性的控制,可以防止某些类型的安全漏洞。

一、导出为onnx格式
首先需要将训练好的yolov8模型转换成onnx格式的模型。在yolov8工程中找到default.yaml文件,该文件即训练时的通用配置文件,具体位置如下:
首先修改其Train settings,如下:
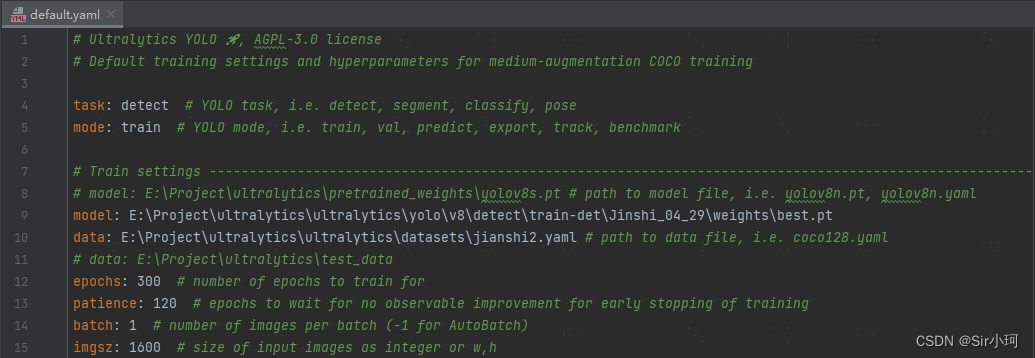 📌model: 此处为训练后模型权重的路径。
📌model: 此处为训练后模型权重的路径。
📌batch:此处的batch一定修改为1,否则后面导出的onnx模型的输入不为1。
📌imgsz:输入图片的尺寸大小与训练时保持一致即可。
接下来继续修改Export settings(在default.yaml文件的后半部分),如下:
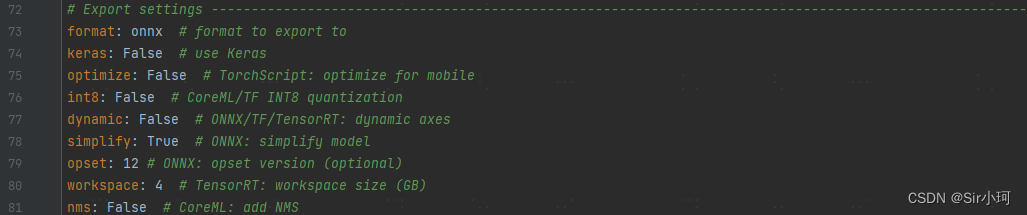
📌format: 此处为onnx格式。
📌opset:此处为onnx的对应版本,修改为12即可。
📌nms:非极大抑制保持关闭。
最后在yolov8工程中找到exporter.py文件,其具体位置如下:
右键,运行该文件,耐心等待即可
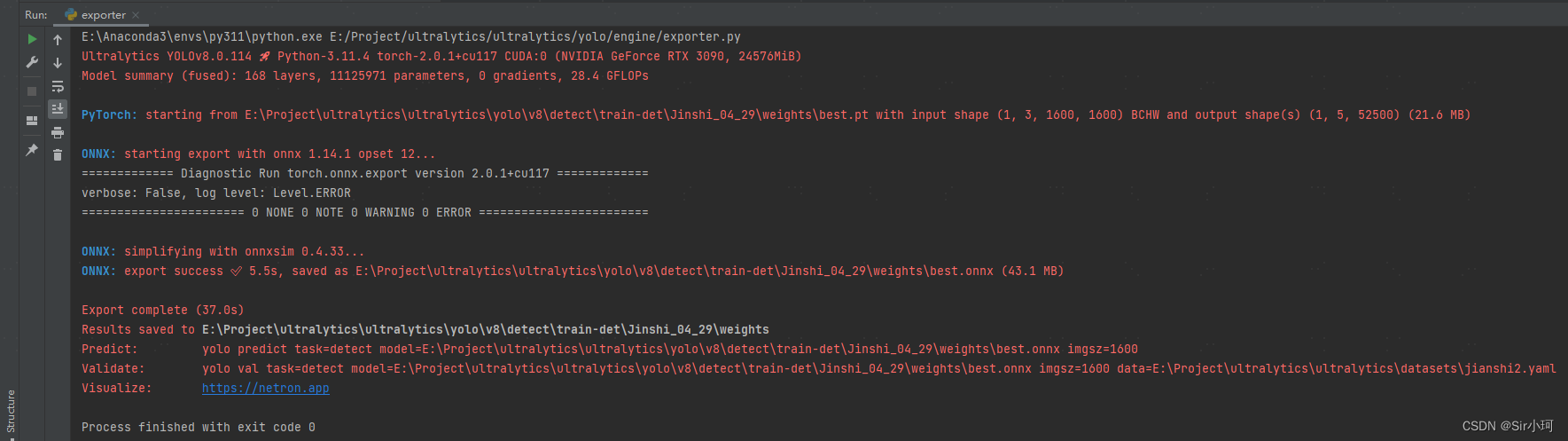
出现
export success ✅ 5.5s
Export complete (37.0s)
表明导出成功,其导出的onnx模型保存在与yolo训练模型相同的文件夹下。
二、基于opencv 推理onnx
本文使用opencv4.7.0版本,其在Linux和windows下均可运行,下面以windows为例子,使用Visual Studio 2022作为开发环境。
首先需要对新建的c++工程进行opencv的环境配置
1.添加环境变量
电脑左上角找到“我的电脑”,点击鼠标右键,依次选择“属性”、“高级系统设置”、“环境变量”、“Path”。添加如下环境变量
❗❗❗路径中的版本要与自己的opencv版本对应
E:\OpenCV\build\bin
E:\OpenCV\build\x64\vc16\bin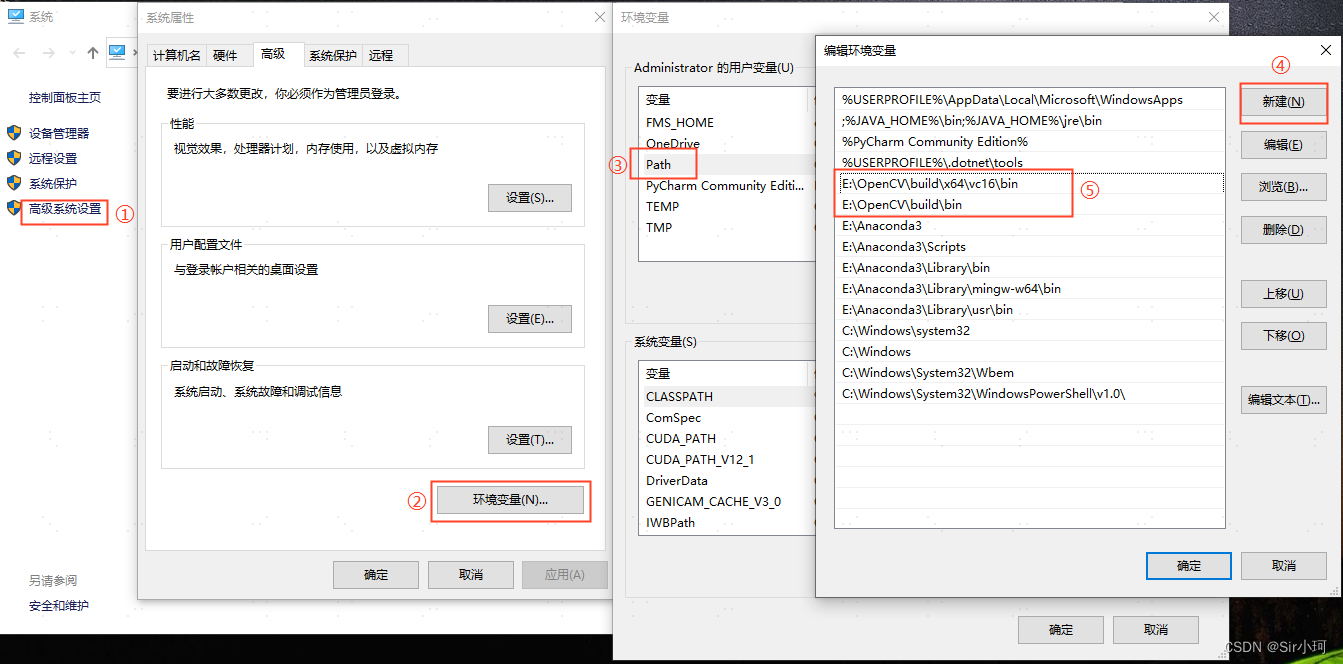
2.添加OpenCV包含目录,库目录和附加依赖项
该项目中我使用的是x64,Release模式,如果需要使用Debug模式下面会略有变化,我会一并给出。

首先在VS中新建一个工程,我这里命名为DetectionV8,可根据自己需求更改,新建完成后找到属性管理器,如图所示
如果右侧栏中没有显示属性管理器可以通过,在Visual Studio左上角菜单栏,依次选择“视图”、“其他窗口”、“属性管理器”进行显示。
然后右键属性管理器中的DetectionV8,选择属性,下面我们依次添加包含目录,库目录和附加依赖项。
①包含目录
在【配置属性】-->【VC++目录】-->【包含目录】中, 点击最右侧的倒三角按钮,选择<编辑>
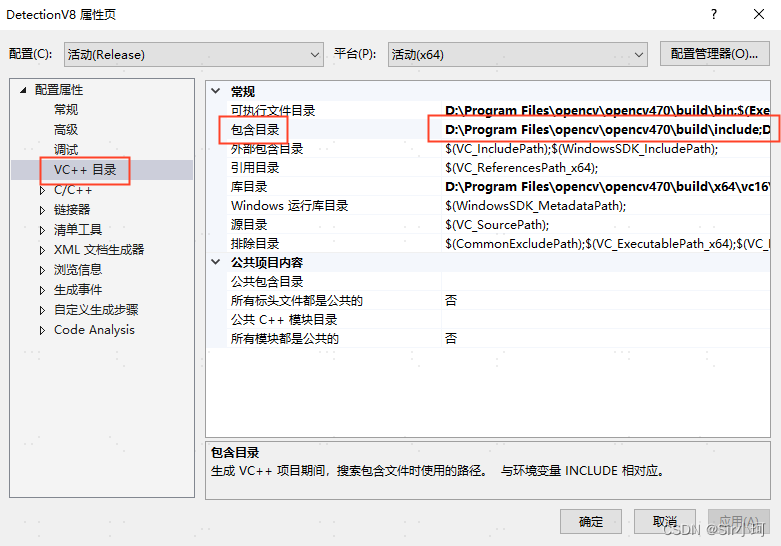
选择“包含目录”,进入“包含目录”页面,添加OpenCV包含目录路径:
❗❗❗路径中的版本要与自己的opencv版本对应,不要手动输入,点击...去浏览添加
D:\Program Files\opencv\opencv470\build\include
D:\Program Files\opencv\opencv470\build\include\opencv2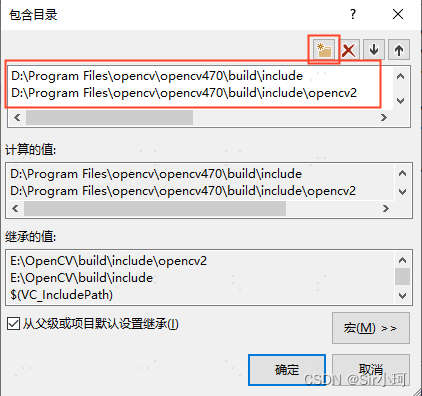
②库目录
在【配置属性】-->【VC++目录】-->【库目录】中, 点击最右侧的倒三角按钮,选择<编辑>
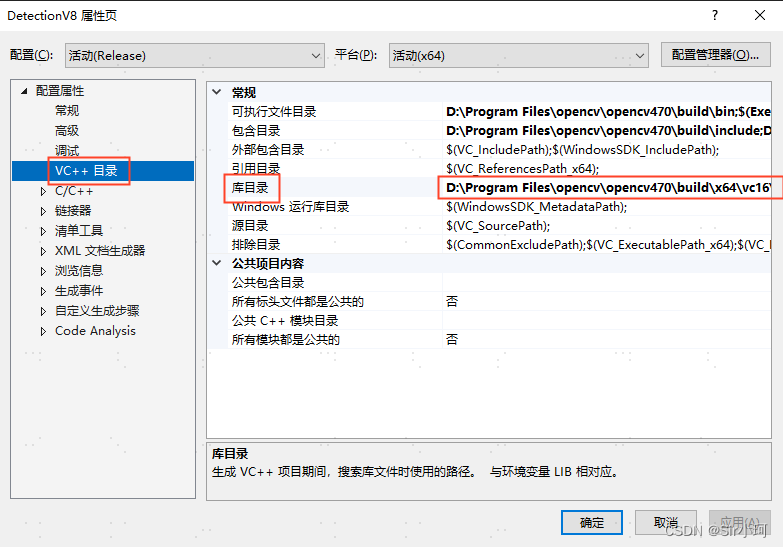
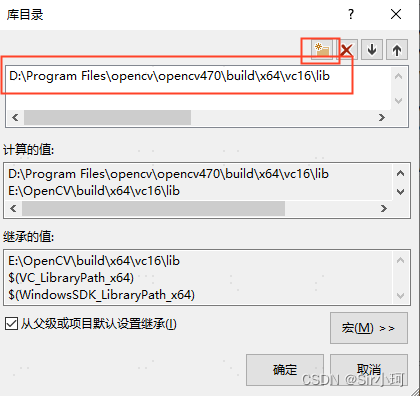
选择“库目录”,进入“库目录”页面,添加库目录(lib文件夹)路径:
D:\Program Files\opencv\opencv470\build\x64\vc16\lib❗❗❗路径中的版本要与自己的opencv版本对应,不要手动输入,点击...去浏览添加
③ 附加依赖项
添加附加依赖项就是添加所有的lib文件路径,这些lib文件都是在前面那个库目录里面保存的。
注意有两种lib文件,一种带d的是Debug模式,不带d的是Release模式,OpenCV版本不同,前面的序号也不同,需要做相应的修改,两种模式的lib最好不要放一起,否则有可能会导致其中一个模式出问题
在【配置属性】-->【链接器】-->【输入】-->【附加依赖项】中, 点击最右侧的倒三角按钮,选择<编辑>
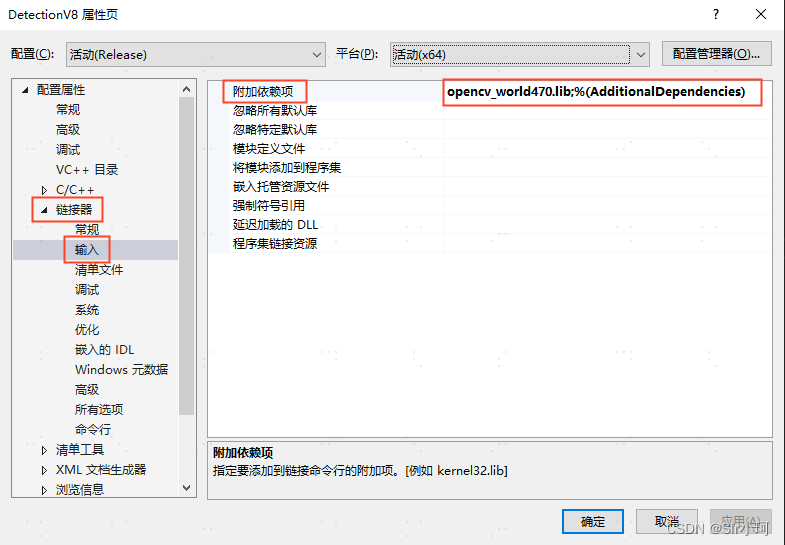
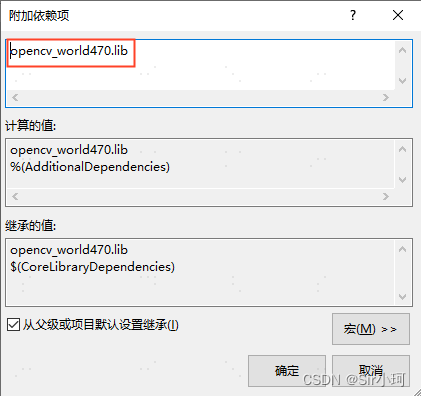
选择“附加依赖项”,进入“附加依赖项”页面,开始添加lib文件路径
# Release模式下添加
opencv_world470.lib
# Debug模式下添加
opencv_world470d.lib ❗❗❗需要与自己的opencv版本对应
3.添加cpp文件与头文件
以下是主函数文件DetectionV8.cpp
#include "yoloV8.h"
#include <iostream>
#include<opencv2//opencv.hpp>
#include<math.h>
#define USE_CUDA false //use opencv-cuda
using namespace std;
using namespace cv;
using namespace dnn;
int main()
{
// 修改为自己测试图片与onnx权重对应的路径
string img_path = "../test.jpg";
string model_path3 = "../best.onnx";
Mat img = imread(img_path);
vector<Scalar> color;
srand(time(0));
for (int i = 0; i < 80; i++) {
int b = rand() % 256;
int g = rand() % 256;
int r = rand() % 256;
color.push_back(Scalar(b, g, r));
}
Yolov8 yolov8; Net net3;
Mat img3 = img.clone();
bool isOK = yolov8.readModel(net3, model_path3, USE_CUDA);
if (isOK) {
cout << "read net ok!" << endl;
}
else {
cout << "read onnx model failed!";
return -1;
}
vector<Detection> result3 = yolov8.Detect(img3, net3);
yolov8.drawPred(img3, result3, color);
Mat dst = img3({ 0, 0, img.cols, img.rows });
cv::imshow("aaa", dst);
imwrite("../result.jpg", dst);
cv::waitKey(0);
return 0;
}以下是yolov8头文件yoloV8.h
#pragma once
#pragma once
#include<iostream>
#include<opencv2/opencv.hpp>
using namespace std;
using namespace cv;
using namespace cv::dnn;
struct Detection
{
int class_id{ 0 };//结果类别id
float confidence{ 0.0 };//结果置信度
cv::Rect box{};//矩形框
};
class Yolo {
public:
bool readModel(cv::dnn::Net& net, std::string& netPath, bool isCuda);
void drawPred(cv::Mat& img, std::vector<Detection> result, std::vector<cv::Scalar> color);
virtual vector<Detection> Detect(cv::Mat& SrcImg, cv::dnn::Net& net) = 0;
float sigmoid_x(float x) { return static_cast<float>(1.f / (1.f + exp(-x))); }
Mat formatToSquare(const cv::Mat& source)
{
int col = source.cols;
int row = source.rows;
int _max = MAX(col, row);
cv::Mat result = cv::Mat::zeros(source.rows, source.cols, CV_8UC3);
source.copyTo(result(cv::Rect(0, 0, col, row)));
return result;
}
const int netWidth = 1600; //ONNX图片输入宽度
const int netHeight = 1600; //ONNX图片输入高度
float modelConfidenceThreshold{ 0.0 };
float modelScoreThreshold{ 0.0 };
float modelNMSThreshold{ 0.0 };
std::vector<std::string> classes = { "dislocation" }; //类别,需要修改为自己对应的类别
};
class Yolov8 :public Yolo {
public:
vector<Detection> Detect(Mat& SrcImg, Net& net);
private:
float confidenceThreshold{ 0.25 };
float nmsIoUThreshold{ 0.70 };
};以下是yolov8的cpp文件yoloV8.cpp
#include"yoloV8.h"
bool Yolo::readModel(Net& net, string& netPath, bool isCuda = false) {
try {
net = readNetFromONNX(netPath);
}
catch (const std::exception&) {
return false;
}
if (isCuda) {
net.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);
}
else {
net.setPreferableBackend(cv::dnn::DNN_BACKEND_DEFAULT);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CPU);
}
return true;
}
void Yolo::drawPred(Mat& img, vector<Detection> result, vector<Scalar> colors) {
for (int i = 0; i < result.size(); ++i)
{
Detection detection = result[i];
cv::Rect box = detection.box;
cv::Scalar color = colors[detection.class_id];
// Detection box
cv::rectangle(img, box, color, 2);
// Detection box text
std::string classString = classes[detection.class_id] + ' ' + std::to_string(detection.confidence).substr(0, 4);
cv::Size textSize = cv::getTextSize(classString, cv::FONT_HERSHEY_DUPLEX, 1, 2, 0);
cv::Rect textBox(box.x, box.y - 40, textSize.width + 10, textSize.height + 20);
cv::rectangle(img, textBox, color, cv::FILLED);
cv::putText(img, classString, cv::Point(box.x + 5, box.y - 10), cv::FONT_HERSHEY_DUPLEX, 1, cv::Scalar(0, 0, 0), 2, 0);
}
}
vector<Detection> Yolov8::Detect(Mat& modelInput, Net& net) {
modelInput = formatToSquare(modelInput);
cv::Mat blob;
cv::dnn::blobFromImage(modelInput, blob, 1.0 / 255.0, Size(netWidth, netHeight), cv::Scalar(), true, false);
将图片(blob)输入到DNN网络中
net.setInput(blob);//输入经过blobFromImage处理的图像信息(支持CV_32F和CV_8U位深度)
std::vector<cv::Mat> outputs;
net.forward(outputs, net.getUnconnectedOutLayersNames());
// yolov8 has an output of shape (batchSize, 84, 8400) (Num classes + box[x,y,w,h])
int rows = outputs[0].size[2];
int dimensions = outputs[0].size[1];
outputs[0] = outputs[0].reshape(1, dimensions);
cv::transpose(outputs[0], outputs[0]);
float* data = (float*)outputs[0].data;
// Mat detect_output(8400, 84, CV_32FC1, data);// 8400 = 80*80+40*40+20*20
float x_factor = (float)modelInput.cols / netWidth;
float y_factor = (float)modelInput.rows / netHeight;
std::vector<int> class_ids;
std::vector<float> confidences;
std::vector<cv::Rect> boxes;
for (int i = 0; i < rows; ++i)
{
cv::Mat scores(1, classes.size(), CV_32FC1, data + 4);
cv::Point class_id;
double maxClassScore;
minMaxLoc(scores, 0, &maxClassScore, 0, &class_id);
if (maxClassScore > modelConfidenceThreshold)
{
confidences.push_back(maxClassScore);
class_ids.push_back(class_id.x);
float x = data[0];
float y = data[1];
float w = data[2];
float h = data[3];
int left = int((x - 0.5 * w) * x_factor);
int top = int((y - 0.5 * h) * y_factor);
int width = int(w * x_factor);
int height = int(h * y_factor);
boxes.push_back(cv::Rect(left, top, width, height));
}
data += dimensions;
}
//执行非最大抑制以消除具有较低置信度的冗余重叠框(NMS)
vector<int> nms_result;
NMSBoxes(boxes, confidences, confidenceThreshold, nmsIoUThreshold, nms_result);
vector<Detection> detections{};
for (unsigned long i = 0; i < nms_result.size(); ++i) {
int idx = nms_result[i];
Detection result;
result.class_id = class_ids[idx];
result.confidence = confidences[idx];
result.box = boxes[idx];
detections.push_back(result);
}
return detections;
}模型部署完毕,运行程序即可!
另外,在此推荐一个小工具,对深度学习的模型理解与查看非常的友好,相信大家也不陌生,就是Netron。Netron是一种用于神经网络、深度学习和机器学习模型的可视化工具,它可以为模型的架构生成具有描述性的可视化(descriptive visualization)。
下载链接放在下面了
另外,如果有想了解yolov8目标检测数据集制作以及yolov8实例分割数据集制作的小伙伴可以移步我的其他文章
YOLOv8制作自己的实例分割数据集保姆级教程(包含json转txt)![]() https://blog.youkuaiyun.com/m0_57010556/article/details/139150198?spm=1001.2014.3001.5501YOLOv8制作自己的目标检测数据集保姆级教程(包含json转xml转txt)
https://blog.youkuaiyun.com/m0_57010556/article/details/139150198?spm=1001.2014.3001.5501YOLOv8制作自己的目标检测数据集保姆级教程(包含json转xml转txt)![]() https://blog.youkuaiyun.com/m0_57010556/article/details/135460191?spm=1001.2014.3001.5502
https://blog.youkuaiyun.com/m0_57010556/article/details/135460191?spm=1001.2014.3001.5502



















 5575
5575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











