






前言
DeepSeek-R1的爆火让春节的热闹从每家每户热闹到了全世界,更是让中国的鞭炮响到了美国硅谷。所有AI届的从业者都对这横空出世的DeepSeek眼前一亮,但DeepSeek真的是横空出世嘛?
我关注到DeepSeek是在2024年7月份,当时古月居社区正好在重新构建AI社区的概念,盛行的技术有两个,微调和RAG,微调成本其实不低且费时费力,并且社区的数据属于每日更新的数据,当机立断当时分析完之后立刻选择了RAG。使用RAG不代表低成本,当时Openai、Claude等API的调用成本其实也是一个问题,这个时候DeepSeek出现在我面前,它好像是一个性价比极高的大模型!
但是用DeepSeek而不了解它实在是不高明,于是研究起了DeepSeek的一些工作,想要知道为什么它能在价格上比同级别(效果)低这么多。
DeepSeek-v2
先来说DeepSeek-v2,DeepSeek-v2是DeepSeek在2024年5月发布的一个大模型。这里不得不说DeepSeek最牛的地方,坚持的走开源路线,将技术路线以及创新点几乎全部share出来!
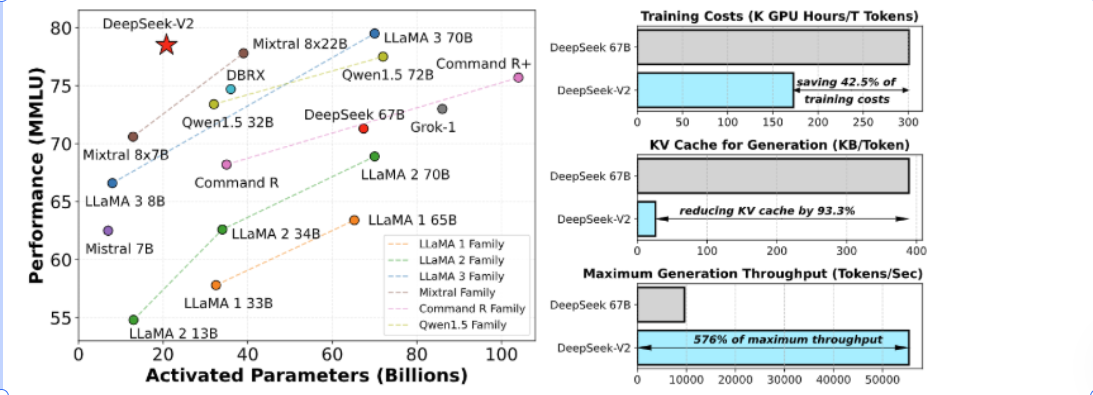
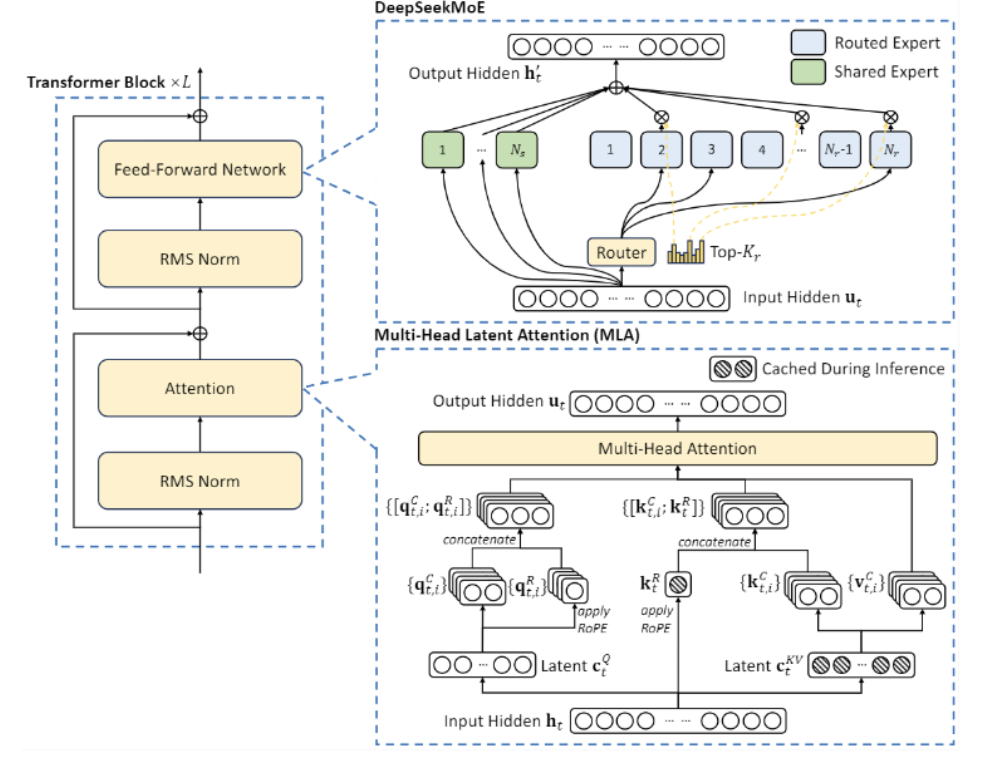
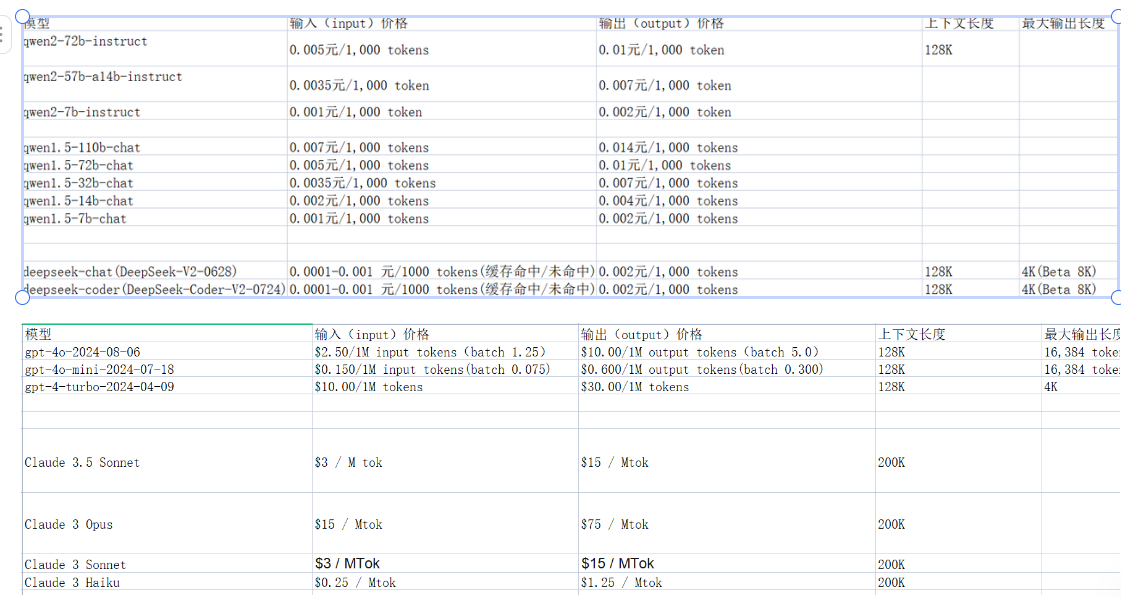
当时我其实比较关注的是这两张图,第一张是在当时DeepSeek-v2同比其他模型的价格以及参数规模,第二张是其创新的技术架构,MOE&MLA!
什么是MOE?
在MOE之前,其实整个大模型主要的技术路线是Dense,特点就是参数量大,硬件消耗大。你可以想象成一个全知全能的老师,不管是语数英、政史地、物化生他全部都会,学生有问题也全部都去问这个老师,可以预见的是这样一个老师的培养成本是非常高的。对于大模型来说也是如此,参数量会非常大,成本也很难有性价比。
MOE其实就是说,这个大模型太大了,什么都会但是成本和参数太高,那不如将Dense大模型变成很多个Sparse的专家小模型,通过多个模型聚合来达到和Dense大模型相当的能力。这样一操作,deekseek v2的激活参数量大大减少,并且性能提升很高。
如果只是Dense和MOE的区别,那为什么其他大模型厂家不适用呢?毕竟MOE也不是DeepSeek独创的。先说一下MOE的一个使用缺陷——负载均衡,具体来说有些专家模型很重要但是某些专家不是那么重要,最后使用的时候发现如果训练的时候去除掉某些专家模型那整个模型会崩掉,而去除另外一些专家模型则几乎不会对模型性能产生影响。好比学校教导主任和兴趣班助教的关系。
回到训练的过程,这就要解决一个工程问题了,业内有一个专家并行机制,通过将不同的专家模型放到不同的显卡上来加速训练,负载均衡问题会导致一些更重要的专家模型计算量更大,最后衍生出不是那么重要的专家模型显卡跑不满。
这里不得不说乱世出英雄,相当一部分原因是DeepSeek的前瞻性和显卡等硬件资源相比国外并不那么富足,才使得DeepSeek强行走通了MOE。
什么是MLA?
点击链接AI时代已来,机器人时代还会远吗?阅读全文


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









