



我们今天来介绍一篇工作,它可以从人类的指令中(比如语言指令中)理解到High-level的一些概念,然后利用这些High-level的指令概念从而映射到low-level的执行层面,进而去进行human-object interation。
文章链接:[2406.17840] Human-Object Interaction from Human-Level Instructions
背景
在日常生活中,我们经常需要执行各种各样的任务,比如“整理工作区”、“把鞋子收好”或者“洗衣服”。这些任务听起来简单,但其实涉及了对环境的理解、物体的识别和操作等复杂过程。对于人类来说,这类任务是基于多年的生活经验和常识来完成的。然而,对于人工智能(AI)来说,要能够理解和执行这样的高级别指令,不仅需要理解语言,还需要具备物理世界的基础知识以及精确的动作技能。

最近的研究中,来自斯坦福大学的一组研究人员开发了一种全新的系统,这个系统可以接受类似于人类的高级别指令,并生成与之匹配的人类-物体交互动作。这项技术结合了大型语言模型(LLMs)、条件扩散模型和强化学习(RL),以实现对动态物体的精细操作,包括手指运动的同步协调。这意味着,智能体不仅能移动大件家具,还能像人一样灵活地抓取小物件,为实现更加自然的机器人助手铺平了道路。
从指令到动作的转换
高级别规划器:解读指令与构建场景图
在我们的系统中,高级别规划器是理解人类意图并将其转化为具体行动计划的核心。这一过程分为两个主要步骤:场景图生成和执行计划生成。如下图所示:
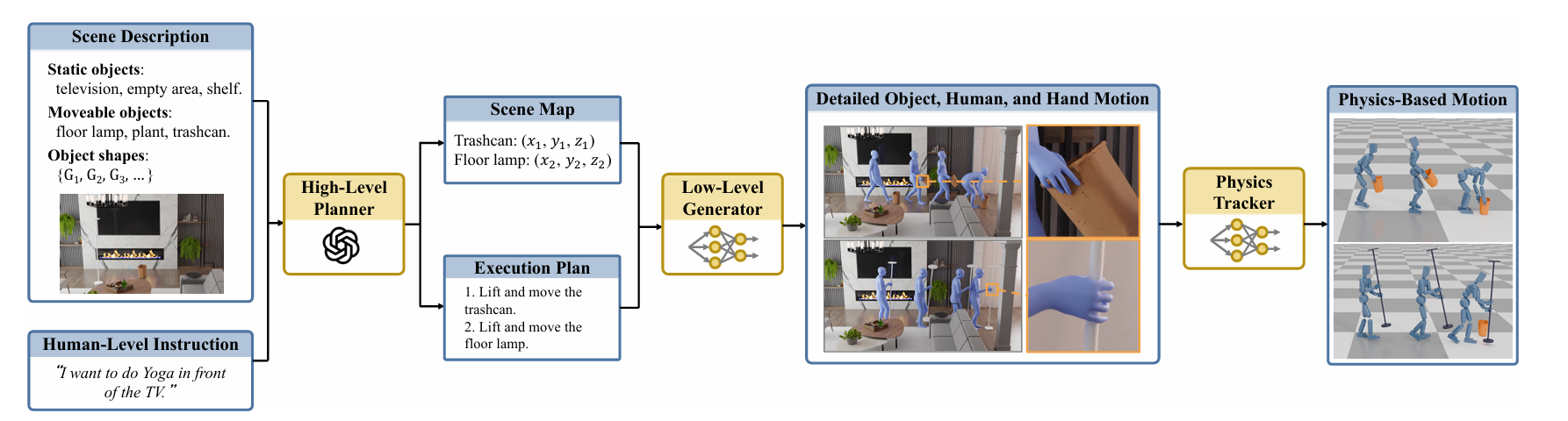
场景图生成
当用户给出一个高级别的指令,比如“设置一个工作空间”,这个指令可能涉及到多个物体(如桌子、椅子、电脑等)以及它们之间的关系。为了将这些抽象的概念转化为具体的行动,我们首先需要确定每个物体的目标位置和朝向。为此,我们使用大型语言模型(LLM)来解析指令,并根据指令内容推断出物体之间的空间关系。例如,“把显示器放在桌子上”可以表示为on(monitor, table),而“让显示器面向椅子”则表示为facing(monitor, chair)。
接下来,我们基于这些空间关系构建了一个场景图,它描述了所有相关物体的位置及其相互联系。通过这种方式,即使指令只是提供了高层次的任务概述,系统也能够准确地确定每一件物品应该放在哪里,从而建立起一个符合逻辑的目标场景。算法会计算出每个物体的具体3D位置,确保最终布置既合理又美观。
执行计划生成
一旦有了目标场景图,下一步就是制定详细的执行计划。这包括决定如何移动各个物体以达到预期布局。例如,如果任务是将显示器放置在桌子上,那么执行计划可能会包含以下几步:“拿起显示器”,“走到桌子旁边”,“将显示器放到桌子上”,“调整显示器的角度”。这里的关键在于保证动作顺序自然且合乎常理,避免出现不合理的行为,如先搬动桌子再取下上面的显示器。
低级别动作生成器:创造真实感的动作序列
低级别动作生成器负责将高级别规划器产生的静态布局信息转化为动态的人类动作。这一部分的工作尤为复杂,因为它不仅要考虑人体的整体运动,还需要精确控制手指的动作,使得整个过程看起来自然流畅。
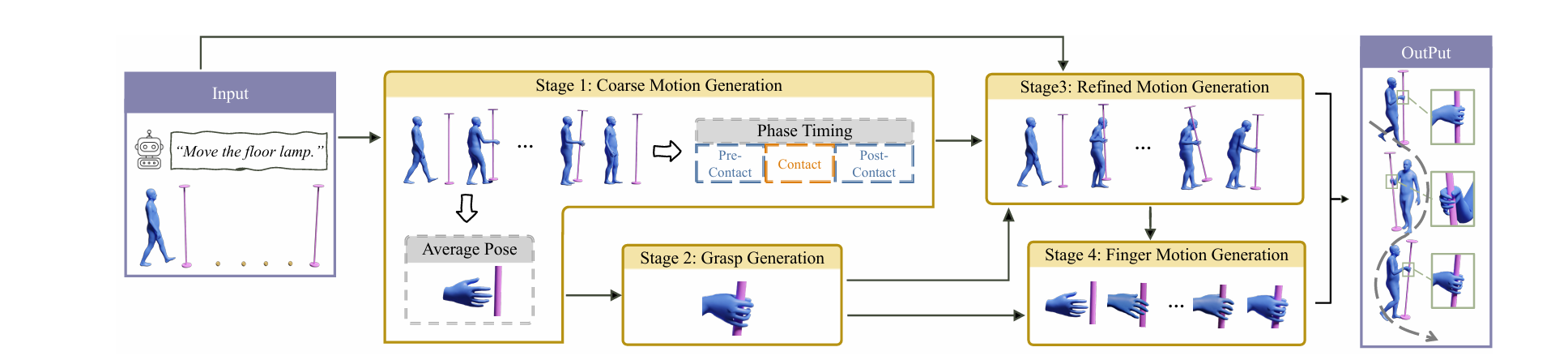
多阶段互动模块
为了实现这一点,研究团队设计了一个四阶段的互动模块:
如下图所示:
-
粗略动作生成(CoarseNet):该阶段的任务是根据初始的人体姿态、物体位置及最终目标位置,生成初步的人体和物体运动轨迹。此时并不涉及手指细节,重点在于捕捉大范围内的动作变化。
-
抓握姿态生成:在第二阶段,系统会根据前一阶段的结果,特别是手腕的姿态,生成合理的抓握姿势。这是因为手指的姿态通常保持相对固定,在接触物体时才会有明显的变化。研究人员采用了最先进的抓握姿态生成方法,考虑到不同大小物体的需求,对原有算法进行了改进,增加了表面采样点的数量,并优化了双手协作情况下的抓握方式。
-
细化动作生成(RefineNet):第三阶段重新生成人体和物体的运动,使之与优化后的抓握姿势相匹配。这一阶段特别关注于解决前两步可能出现的动作不协调问题,例如手部未能准确接触到物体或物体未能稳定停留在预定位置等问题。通过引入额外的条件——手腕相对于物体的位置,以及非接触期间物体应保持静止的要求,RefineNet确保了动作更加连贯且符合物理规律。
-
手指运动生成(FingerNet):最后一个阶段专注于生成手指接近和释放物体时的细腻动作。这部分对于模拟真实的交互至关重要,因为它决定了人物是否能顺利地完成拿取、放置等操作。FingerNet采用条件扩散模型预测手指运动,并结合手掌与物体间的距离关系进行调节,使得动作过渡平滑自然。
此外,为了模拟人在环境中行走的过程,导航模块还负责生成长距离的动作序列,使人物能够在不同地点之间移动,同时保持正确的方向感。此模块同样基于条件扩散模型,输入条件包括起始姿态、路径上的关键点以及行进方向等信息,输出则是连续的人体运动轨迹。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









