







 本文深入探讨NLP的主要任务和技术,包括数据清洗、分词、词性标注、命名实体识别、词向量表示、句法语义分析、文本相似度计算和文本分类。通过垃圾短信文本分类实战,展示了NLP在实际项目中的应用,使用fasttext进行词向量学习和lightgbm模型进行文本分类。
本文深入探讨NLP的主要任务和技术,包括数据清洗、分词、词性标注、命名实体识别、词向量表示、句法语义分析、文本相似度计算和文本分类。通过垃圾短信文本分类实战,展示了NLP在实际项目中的应用,使用fasttext进行词向量学习和lightgbm模型进行文本分类。
NLP,自然语言处理就是用计算机来分析和生成自然语言(文本、语音),目的是让人类可以用自然语言形式跟计算机系统进行人机交互,从而更便捷、有效地进行信息管理。
NLP是人工智能领域历史较为悠久的领域,但由于语言的复杂性(语言表达多样性/歧义/模糊等等),如今的发展及收效相对缓慢。比尔·盖茨曾说过,"NLP是 AI 皇冠上的明珠。" 在光鲜绚丽的同时,却可望而不可及(...)。

为了揭开NLP的神秘面纱,本文接下来会梳理下NLP流程、主要任务及算法,并最终落到实际NLP项目(经典的文本分类任务的实战)。顺便说一句,个人水平有限,不足之处还请留言指出~~
二、NLP主要任务及技术
NLP任务可以大致分为词法分析、句法分析、语义分析三个层面。具体的,本文按照单词-》句子-》文本做顺序展开,并介绍各个层面的任务及对应技术。本节上半部分的分词、命名实体识别、词向量等等可以视为NLP基础的任务。下半部分的句子关系、文本生成及分类任务可以看做NLP主要的应用任务。
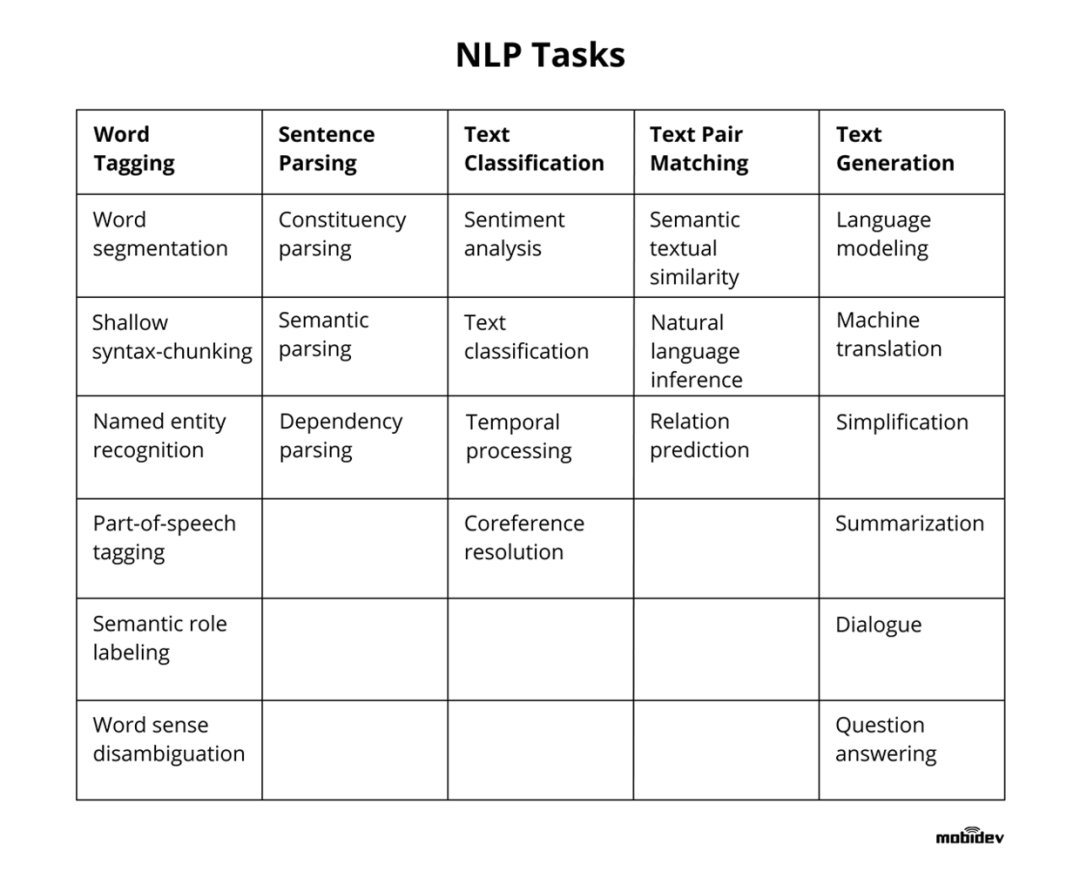
这里,贴一张自然语言处理的技术路线图,介绍了NLP任务及主流模型的分支:
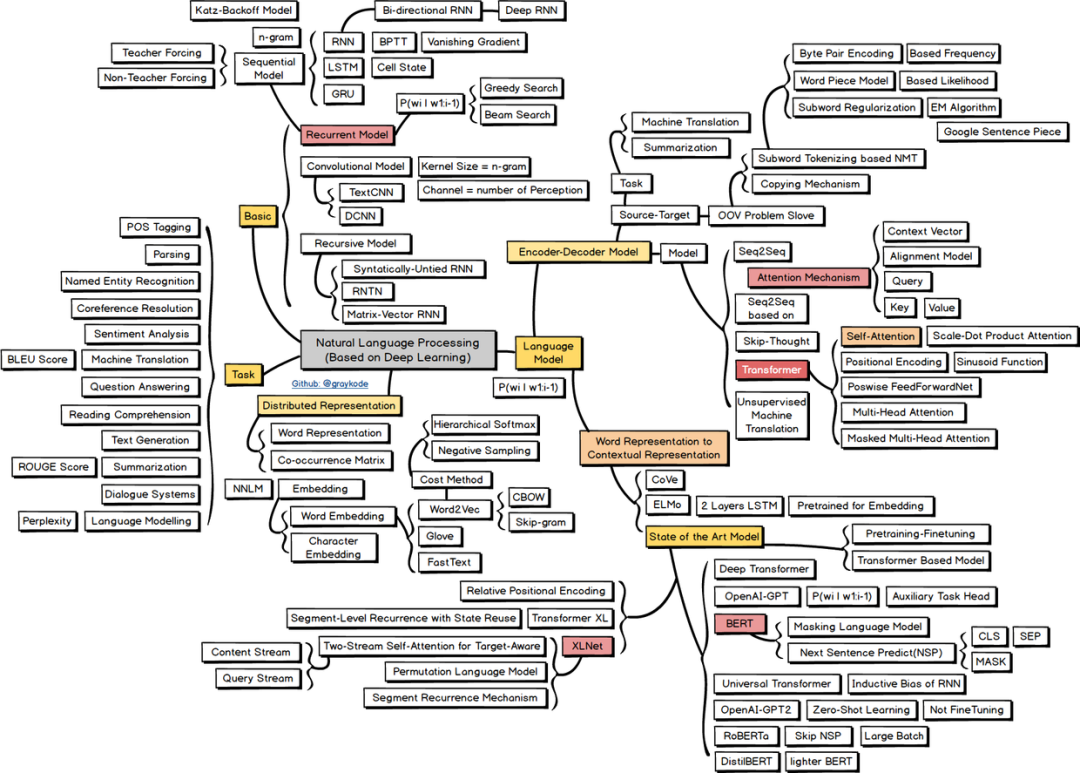
高清图可如下路径下载(原作者graykode):https://github.com/aialgorithm/AiPy/tree/master/Ai%E7%9F%A5%E8%AF%86%E5%9B%BE%E5%86%8C/Ai_Roadmap
2.1 数据清洗 + 分词(系列标注任务)
-
数据语料清洗。我们拿到文本的数据语料(Corpus)后,通常首先要做的是,分析并清洗下文本,主要用正则匹配删除掉数字及标点符号(一般这些都是噪音,对于实际任务没有帮助),做下分词后,删掉一些无关的词(停用词),对于英文还需要统一下复数、语态、时态等不同形态的单词形式,也就是词干/词形还原。
-
分词。即划分为词单元(token),是一个常见的序列标注任务。对于英文等拉丁语系的语句分词,天然可以通过空格做分词,

对于中文语句,由于中文词语是连续的,可以用结巴分词(基于trie tree+维特比等算法实现最大概率的词语切分)等工具实现。
import jieba
jieba.lcut("我的地址是上海市松江区中山街道华光药房")
>>> ['我', '的', '地址', '是', '上海市', '松江区', '中山', '街道', '华光', '药房']
-
英文分词后的词干/词形等还原(去除时态 语态及复数等信息,统一为一个“单词”形态)。这并不是必须的,还是根据实际任务是否需要保留时态、语态等信息,有WordNetLemmatizer、 SnowballStemmer等方法。
-
分词及清洗文本后,还需要对照前后的效果差异,在做些微调。这里可以统计下个单词的频率、句长等指标,还可以通过像词云等工具做下可视化~
from wordcloud import WordCloud
ham_msg_cloud = WordCloud(width =520, height =260,max_font_size=50, background_color ="black", colormap='Blues').generate(原文本语料)
plt.figure(figsize=(16,10))
plt.imshow(ham_msg_cloud, interpolation='bilinear')
plt.axis('off') # turn off axis
plt.show()

2.2 词性标注(系列标注任务)
词性标注是对句子中的成分做简单分析,区分出分名词、动词、形容词之类。对于句法分析、信息
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 821
821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









