







 本教程通过Python爬虫爬取淘宝沙发类目商品,进行数据清洗、分析和可视化,包括词云、销量、价格分布等。使用jieba分词、matplotlib和seaborn等工具,探讨商品标题、销量、价格和省份分布等关键指标。
本教程通过Python爬虫爬取淘宝沙发类目商品,进行数据清洗、分析和可视化,包括词云、销量、价格分布等。使用jieba分词、matplotlib和seaborn等工具,探讨商品标题、销量、价格和省份分布等关键指标。

如需完整代码,加 LiteMango(付费)
项目内容
本案例选择>> 商品类目:沙发;
数量:共100页 4400个商品;
筛选条件:天猫、销量从高到低、价格500元以上。
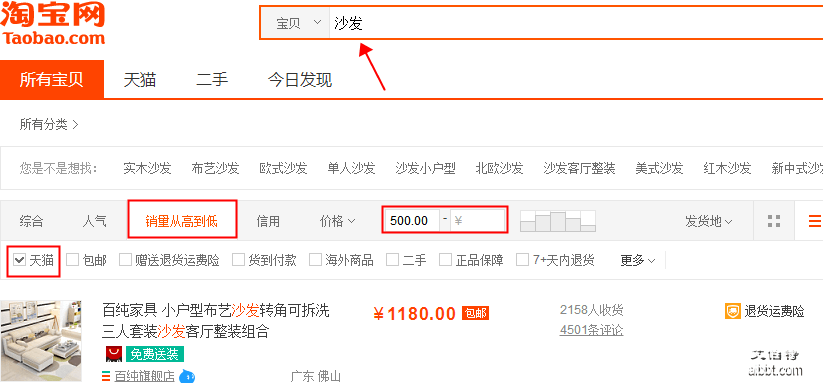
以下是分析,源码点击文末链接
项目目的
2. 不同关键词word对应的sales的统计分析
3. 商品的价格分布情况分析
4. 商品的销量分布情况分析
5. 不同价格区间的商品的平均销量分布
6. 商品价格对销量的影响分析
7. 商品价格对销售额的影响分析
8. 不同省份或城市的商品数量分布
9.不同省份的商品平均销量分布
注:本项目仅以以上几项分析为例。
项目步骤
2. 对数据进行清洗和处理
3. 文本分析:jieba分词、wordcloud可视化
4. 数据柱形图可视化 barh
5. 数据直方图可视化 hist
6. 数据散点图可视化 scatter
7. 数据回归分析可视化 regplot
工具&模块:
工具:本案例代码编辑工具 Anaconda的Spyder
模块:requests、retrying、missingno、jieba、matplotlib、wordcloud、imread、seaborn 等。
原代码和相关文档文末自取
一、爬取数据
因淘宝网是反爬虫的,虽然使用多线程、修改headers参数,但仍然不能保证每次100%爬取,所以 我增加了循环爬取,每次循环爬取未爬取成功的页 直至所有页爬取成功停止。
说明:淘宝商品页为JSON格式 这里使用正则表达式进行
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 905
905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









