






 本文介绍了使用Python爬虫从前程无忧网站抓取岗位信息的步骤,包括分析接口、发送HTTP请求、解析数据及保存信息。通过实际案例展示了如何编码关键词以实现动态搜索功能。
本文介绍了使用Python爬虫从前程无忧网站抓取岗位信息的步骤,包括分析接口、发送HTTP请求、解析数据及保存信息。通过实际案例展示了如何编码关键词以实现动态搜索功能。
用python获取前程无忧网站的岗位信息
通过前程无忧的一个信息接口来获取搜索的相关的岗位信息
先看效果:

打开前程无忧网站,打开开发者模式,进行抓包
先刷新一遍,然后直接全局搜索关键字
找到这个文件
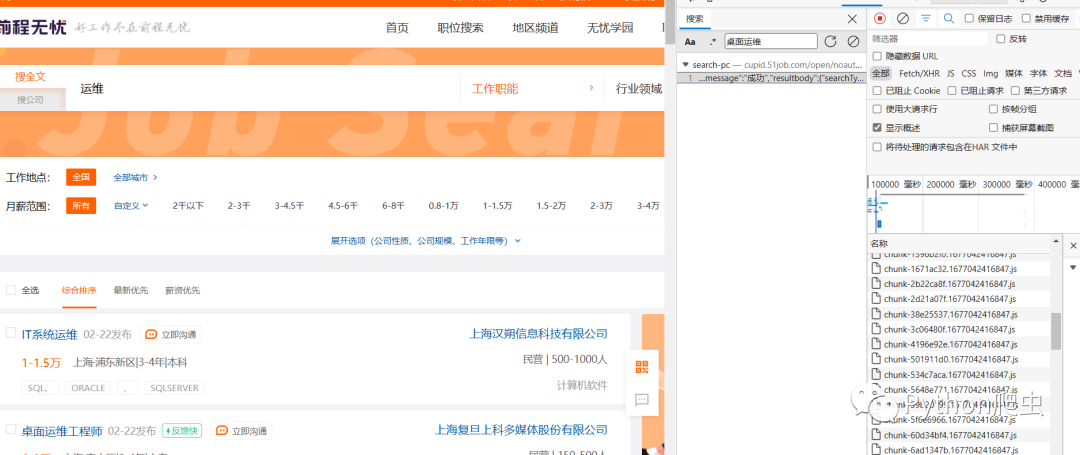
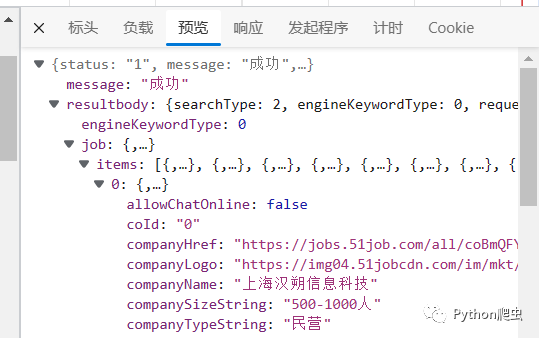
这些就是岗位信息
直接访问这个接口,就可以获取这些信息
点击标头
查看请求url和请求方法
url里timetamp是一个时间戳
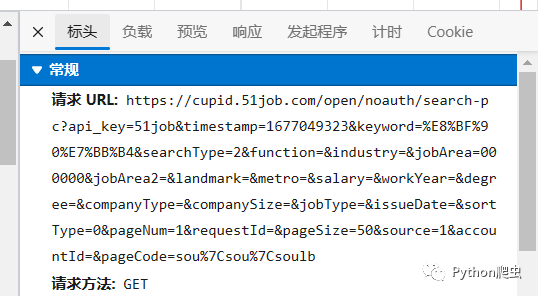
还有请求标头
这个sign是一个加密参数

用python获取前程无忧网站的岗位信息
通过前程无忧的一个信息接口来获取搜索的相关的岗位信息
先看效果:
打开前程无忧网站,打开开发者模式,进行抓包
先刷新一遍,然后直接全局搜索关键字
找到这个文件
这些就是岗位信息
直接访问这个接口,就可以获取这些信息
点击标头
查看请求url和请求方法
url里timetamp是一个时间戳
还有请求标头
这个sign是一个加密参数
 1532
4122
1653
1532
4122
1653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























