






这是之前写的一个爬虫,现在分享一下。这次主要是使用BeautifulSoup,这个是最简单的一种方法。但是这次使用了lambda匿名函数,该函数是python中的一种表达式,lambda函数格式为:冒号前是参数,冒号的右边为表达式。lambda返回值函数的地址,也就是函数对象。还是一步步分析:
匹配到新的URL地址,然后获取新的URL的地址下的内容。
#设置访问头
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
ll = []
def geturl(url): #传入地址
res=requests.get(url,headers=headers)
#设置编码
res.encoding=res.apparent_encoding
#对网页进行解析
soup=BeautifulSoup(res.text,'html.parser')
#查找并获得新链接
lianjie=soup.find_all('p',class_='t1')
for i in lianjie:
try:
lianjie2=i.find('a')['href']
ll.append(lianjie2)
except:
pass
return ll获取新的地址并爬取该地址下的内容。
def getinfo(URL): #获得新的地址并进行其地址下的内容爬取
res=requests.get(URL,headers=headers)
res.encoding=res.apparent_encoding
soup=BeautifulSoup(res.text,'html.parser')
#查找匹配’div’,class_=’cn’下的内容
all=soup.find_all('div',class_='cn')
#查找匹配职位、地址、公司名称、公司介绍和学历要求等等。
for each in all:
zhiwei=each.find('h1').text
diqu=each.find('span',class_='lname')
gongsi=each.find('p',class_='cname').text.strip('\n')
jianjie=each.find('p',class_='msg ltype').text
jianjie1='--'.join(list(map(lambda x:x.strip(),jianjie.split('|'))))
xinzi=each.find('strong').text
all2=soup.find_all('div',class_='tCompany_main')对公司的岗位职责进一步爬取,对公司的信息,职责等进行爬取
for each2 in all2: #获得年限要求和职责的URL进行爬取
jingyan=each2.find_all('span',class_='sp4')
jingyan1='--'.join(list(map(lambda x:x.text.strip(),jingyan)))
fuli=each2.find_all('p',class_='t2')
fuli1='--'.join('--'.join(list(map(lambda x:x.text.strip(),fuli))).split('\n'))
zhize=each2.find_all('div',class_='bmsg job_msg inbox')
for p in zhize:
zhize1=p.find_all('p')
zhize2='\n'.join(list(map(lambda x:x.text.strip(),zhize1)))
dizhi=each2.find('div',class_='bmsg inbox')
xinxi=each2.find('div',class_='tmsg inbox')详细代码:
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import time
j=51
while j<60:
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
ll = []
def geturl(url):
res=requests.get(url,headers=headers)
res.encoding=res.apparent_encoding
soup=BeautifulSoup(res.text,'html.parser')
lianjie=soup.find_all('p',class_='t1')
for i in lianjie:
try:
lianjie2=i.find('a')['href']
ll.append(lianjie2)
except:
pass
return ll
total=[]
def getinfo(URL):
res=requests.get(URL,headers=headers)
res.encoding=res.apparent_encoding
soup=BeautifulSoup(res.text,'html.parser')
all=soup.find_all('div',class_='cn')
for each in all:
zhiwei=each.find('h1').text
diqu=each.find('span',class_='lname')
gongsi=each.find('p',class_='cname').text.strip('\n')
#print(gongsi)
jianjie=each.find('p',class_='msg ltype').text
print(jianjie)
jianjie1='--'.join(list(map(lambda x:x.strip(),jianjie.split('|'))))
#print(jianjie1)
xinzi=each.find('strong').text
#print(xinzi)
all2=soup.find_all('div',class_='tCompany_main')
for each2 in all2:
jingyan=each2.find_all('span',class_='sp4')
jingyan1='--'.join(list(map(lambda x:x.text.strip(),jingyan)))
fuli=each2.find_all('p',class_='t2')
fuli1='--'.join('--'.join(list(map(lambda x:x.text.strip(),fuli))).split('\n'))
zhize=each2.find_all('div',class_='bmsg job_msg inbox')
for p in zhize:
zhize1=p.find_all('p')
zhize2='\n'.join(list(map(lambda x:x.text.strip(),zhize1)))
dizhi=each2.find('div',class_='bmsg inbox')
xinxi=each2.find('div',class_='tmsg inbox')
#print(zhize2)
with open('C:\\Users\\USER\\Desktop\\biyeshejidaimai\\gongzuoxinxi.txt','a+',encoding='utf-8') as f:
f.write(str(jianjie)+'\n')
f.close()
print("正在写入第"+str(j)+"页数据")
info={#'zhiwei':zhiwei,
#'diqu':diqu,
#'gongsi':gongsi,
#'jianjie':jianjie1,
'xinzi':xinzi,
#'jingyan':jingyan1,
#'fuli':fuli1,
'zhize':zhize2,
#'dizhi':dizhi,
'xinxi':xinxi}
total.append(info)
return total
if __name__ == '__main__':
url='https://search.51job.com/list/260200,000000,0000,00,9,99,%E8%AE%A1%E7%AE%97%E6%9C%BA,2,'+str(j)+'.html'#只抓一页,可以for循环抓多页
for i in geturl(url)[1:]:
time.sleep(2)
getinfo(i)
import pandas as pd
df=pd.DataFrame(total)
df.to_excel('C:\\Users\\USER\\Desktop\\biyeshejidaimai\\zhaopinjieshao.xls')
j=j+1
结果如下:
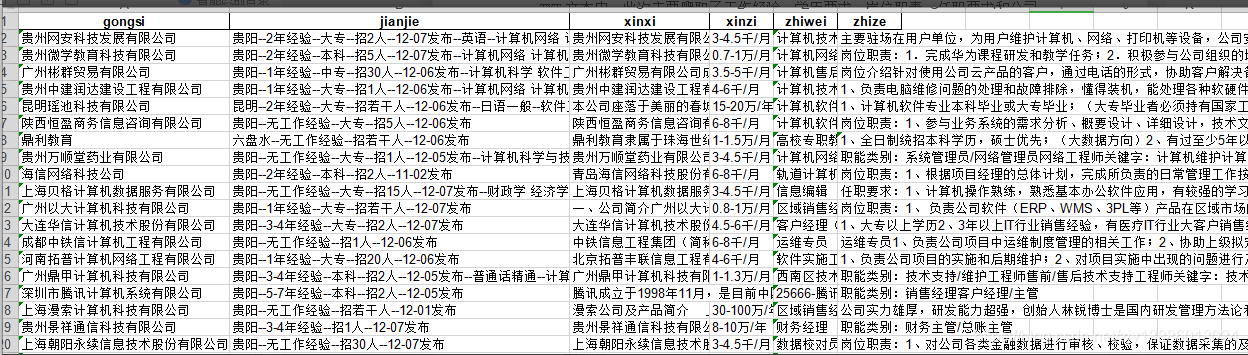
好了,就到这里。

















 6086
6086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









