







目录
在日常的学习和交流中,我们常常能够听到栈(Stack)和堆(Heap)
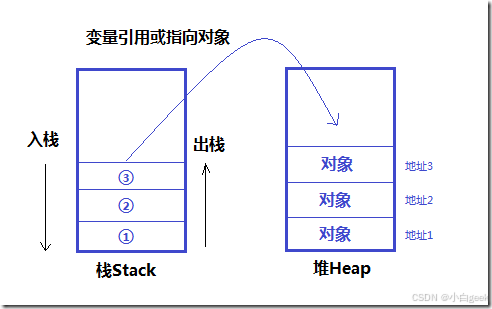
那么栈和堆在硬件上处于什么位置呢?而为什么栈又比堆快呢?两者的区别是什么?本文将详细介绍这些区别,并解释着重解释为什么栈通常能提供比堆更快的性能。
事实上,栈和堆都是计算机内存的一部分,它们在物理硬件上都位于RAM(随机存取存储器)也就是我们常说的“内存”中。然而,尽管它们都在同一块物理内存上,栈和堆的工作方式和特性却有着显著的区别,这些区别导致了栈通常比堆更快。
一、硬件支持上的差异
从硬件的角度来看,栈享有CPU直接提供的支持。现代处理器包含了专门针对栈操作优化的指令集,例如push和pop,这使得栈区的内存分配和回收极其高效。栈上局部变量的连续分配方式也有助于减少CPU缓存失效的情况,进一步提升访问速度。相反,堆是操作系统抽象出来的概念,缺乏CPU级别的直接指令支持,其操作复杂度更高,因此效率相对较低。
二、内存管理策略的不同
栈的管理由编译器自动完成,它采用的是简单且高效的先进后出(LIFO, Last In First Out)后进先出原则。这意味着每次内存分配或释放都只需要调整一个指针即可实现,这样的设计保证了极高的执行效率。相比之下,堆则需要程序员手动进行复杂的内存分配管理,包括但不限于寻找可用内存块、处理内存碎片等挑战,这无疑增加了计算资源的需求。
三、编译期 vs 运行期分配
栈的内存分配是在编译期间确定下来的,因此当程序实际运行时,几乎不需要花费额外时间来处理栈上的内存分配。然而,堆上的内存分配发生在运行时期间,这意味着在程序执行过程中必须动态地搜索合适的内存块,并可能需要调用操作系统服务以扩展数据段。这一过程显然更加耗时。
四、生命周期和内存回收
栈上的数据,如函数内部的局部变量,其生命周期严格绑定于函数的作用域内。一旦函数结束执行,所有相关的栈帧会立即被清除,简化了内存管理并加速了回收过程。而堆上的对象可以跨越多个函数甚至整个应用程序的生命周期存在,这就要求程序员显式地管理这些对象的生命周期,增加了编程的复杂性,同时也带来了潜在的内存泄漏风险。
五、总结
综上所述,栈之所以能够提供比堆更优的性能,主要归功于其简单的结构、直接的硬件支持、快速的内存分配和回收机制以及较低的管理成本。
六、拓展
那我们知道了栈比堆快又有什么用呢,是否属于“八股文”,知道了解,但在实际场景中却很少用到呢?其实在日常的学习还是工作中经常用到,不过编译器为帮我们隐式处理了这个过程,这就是经常会提到的“装箱”与“拆箱”,这个问题会触发GC机制,也就是垃圾回收,会在下一篇文章中讲解关于拆箱与装箱GC优化
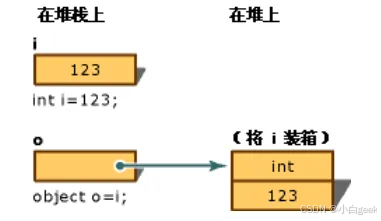
注意事项
值得注意的是,虽然栈提供了更好的性能,但它并非适用于所有的场景。选择使用栈还是堆应当根据具体的应用需求和上下文环境来决定。比如,当需要创建具有较长生命周期的对象或者大型数据结构时,堆可能是更合适的选择;而对于短期存在的小规模数据,则栈是更为理想的地方。
希望这篇文章能够帮助你更好地理解栈和堆之间的性能差异。如果你有任何疑问,请随时留言指正!如果您觉得这篇文章对您有帮助,请帮我点个小小的赞或者分享给需要的同学,也可以关注我的博客获取更多技术文章更新。十分感激!!!



















 1958
1958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











