







 文章解释了字节序(大端与小端)的存在原因,由于计算机电路处理低位字节效率高,导致内部采用小端字节序,但对外部交互通常使用大端字节序。只有在数据读取时才需区分,写入则无需考虑。
文章解释了字节序(大端与小端)的存在原因,由于计算机电路处理低位字节效率高,导致内部采用小端字节序,但对外部交互通常使用大端字节序。只有在数据读取时才需区分,写入则无需考虑。
目录
为什么?
我一直不理解,为什么要有字节序,每次读写都要区分,多麻烦!统一使用大端字节序,不是更方便吗?
最近浏览博客时,解答了所有的疑问。而且,我发现原来的理解是错的,字节序其实很简单。
那么为什么要用大小端字节序?我们又该怎么区分大小端字节序呢?
接下来就一起来看看吧!
计算机硬件有两种储存数据的方式:大端字节序(big endian)和小端字节序(little endian)。
举例来说,数值
0x2211使用两个字节储存:高位字节是0x22,低位字节是0x11
- 大端字节序:高位字节在前(低地址),低位字节在后(低地址),这是人类读写数值的方法。
- 小端字节序:低位字节在前(低地址),高位字节在后(低地址),即以
0x1122形式储存
有一张图可以形象的演示大小端的区别

区分
大端字节序:低地址处存放高字节
小端字节序:低地址处存放低字节
再举一个具体一点的例子
0x1234567的大端字节序和小端字节序的写法如下图
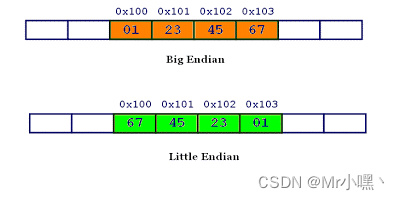
按照我们人类的习惯来说,从左到右的读,即大端字节序,那为什么会有小端字节序?
答案是
计算机电路先处理低位字节,效率比较高,因为计算都是从低位开始的。所以,计算机的内部处理都是小端字节序。
但是,人类还是习惯读写大端字节序。所以,除了计算机的内部处理,其他的场合几乎都是大端字节序,比如网络传输和文件储存。
总结
字节序的处理,就是一句话:
"只有读取的时候,才必须区分字节序,其他情况都不用考虑。"
处理器读取外部数据的时候,必须知道数据的字节序,将其转成正确的值。然后,就正常使用这个值,完全不用再考虑字节序。
即使是向外部设备写入数据,也不用考虑字节序,正常写入一个值即可。外部设备会自己处理字节序的问题。
以上就是本文的全部内容,欢迎大家指正,关注,点赞,感谢!!!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











