






引言
帮助对transformer了解的人群,梳理transformer的相关知识,以来为后续工作奠定知识基础和应付就业面试问题。
发展历史
在transformer提出前
使用的最多的模型是seq2seq,但是该模型有自身的问题
- 难以捕捉到输入序列中距离较远的信息之间的关系,导致这问题的原因是Seq2Seq模型通常使用循环神经网络(RNNs)作为其编码器和解码器,而RNN在处理长序列时可能会遇到梯度消失或梯度爆炸的问题
- 沿时间维度顺序处理数据,无法并行处理数据,导致处理速度过慢。
在transformer提出后
于2017年文章《attention is all you need》中提出了transformer,基于不同架构基础衍生出三种不同技术产物:
- Decoder-Based,产出GPT1~GPT3、ChatGPT等
- Encoder-Decoder,产出T5、BART、GLM
- Encoder-Based,产出BERT,XLM等
概念
是一种基于自注意力机制的深度学习模型架构,输入和输出都是是序列信息
架构
多个结构相同参数不同的Encoder和Deconder
Encoder
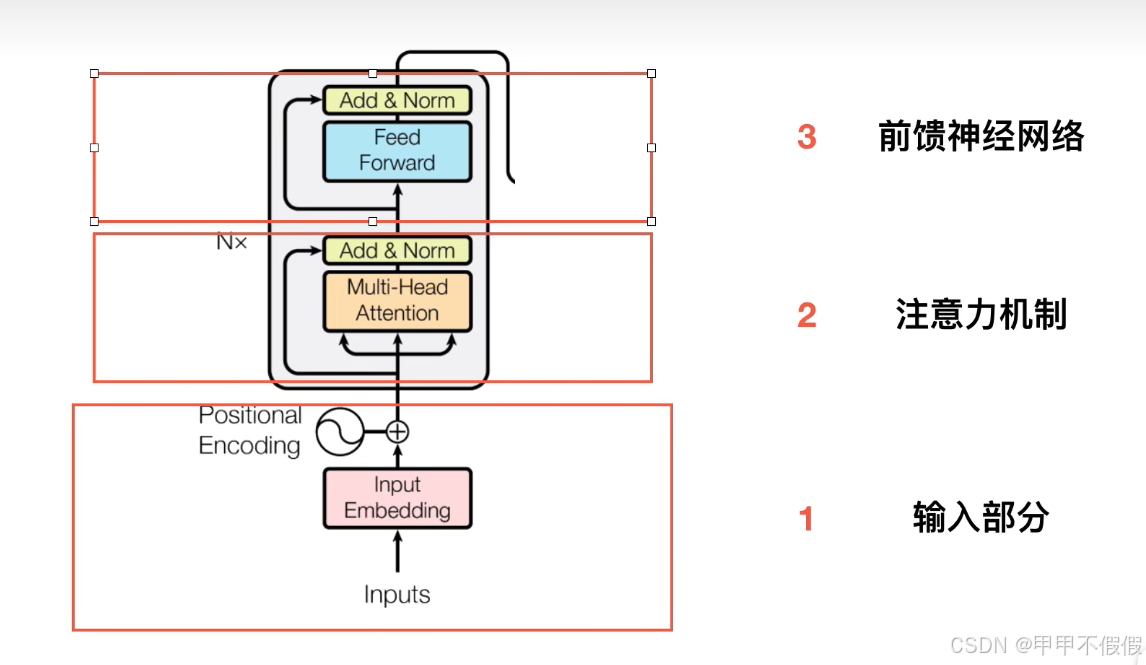
一个Encoder包含三个部分,输入部分,注意力机制,前馈神经网络。
输入部分
输入部分包含两个部分:Embedding和位置嵌入;
Embedding
将输入数据变成向量,详细步骤参考文章wordEmbedding工程;
位置嵌入
需求性:区别于传统的RNN,多头注意力机制对所有的数据并行处理,这种处理方案增加了处理的效率,但是忽略单词之间的关系所以要进行位置编码。
编码方式:使用正弦和余弦函数,来进行位置编码,得到位置矩阵,公式如下:
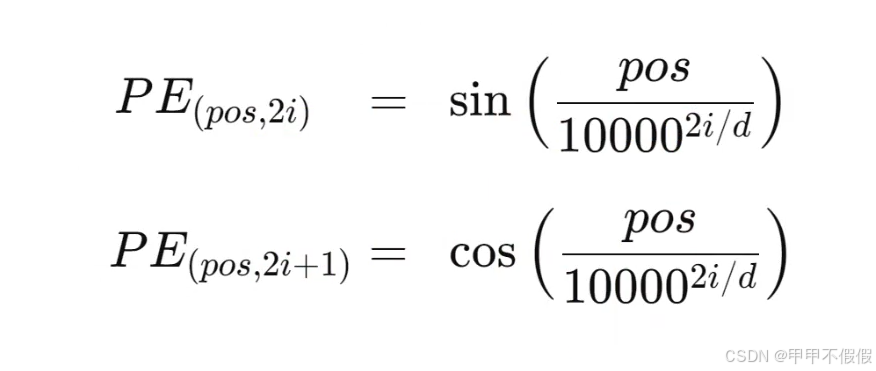
其中pos是指该词向量在序列中的位置索引;i 表示位置编码向量中的维度索引
使用方法:将位置矩阵与嵌入矩阵相加最后输出
这种直接与词向量相加的位置嵌入方法为什么不会破坏词向量原本的信息: 因为会使用大量的训练数据让神经网络训练并整合‘词向量+位置编码’的信息,能够对深层次的区分和理解。
tips:位置编码的方式有绝对位置编码和相对位置编码两种,绝对位置编码中会包含相对位置信息,但是这种相对位置信息会在注意力机制那里消失
自注意力机制
在transformer中的注意力机制
Decoder

















 1001
1001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









