






GraphRAG
传统RAG的局限性
- 忽视关系 :文本内容通常并非孤立而是相互关联的。传统的 RAG 无法捕获,仅靠语义相似性无法呈现的重要结构化关系知识。比如,在通过引用关系连接论文的引用网络中,传统的 RAG 方法侧重于依据查询找到相关论文,却忽略了论文之间重要的引用关系。
- 冗余信息 :RAG 在连接成提示时,常以文本片段的形式重复内容,致使上下文过长,陷入“Lost in the Middle”的困境。Lost in the Middle:在处理需要识别相关上下文的信息的任务(文档问答、键值对索引)时,大模型对相关信息的位置很敏感;当相关的信息在输入prompt的开头或者结尾时,能够取得较好的效果,而当相关的信息在prompt中间部分时,性能会显著下降。
- 缺乏全局信息 :RAG 只能检索文档的子集,无法全面掌握全局信息,因而在诸如查询聚焦摘要(Query-Focused Summarization,QFS)等任务中表现不佳。
概念
graphRAG是将知识库被表示为一个由实体(例如人物、地点、事件等)和这些实体之间的关系组成的网络。graphRAG从知识库中中检索包含与给定查询相关的关系知识的图元素,这些元素可能包括用于生成响应的节点、三元组、路径或子图。
三元组(Triple)是知识图谱中用于表示实体(Entities)及其相互关系(Relations)的基本数据单位,通常由主体,谓语,客体构成。
Text-Attributed Graphs,简称TAG,是文本属性图的英文表达。它是 GraphRAG 中使用的图形数据的通用和通用格式。
技术逻辑
基于图的索引(G-Indexing)
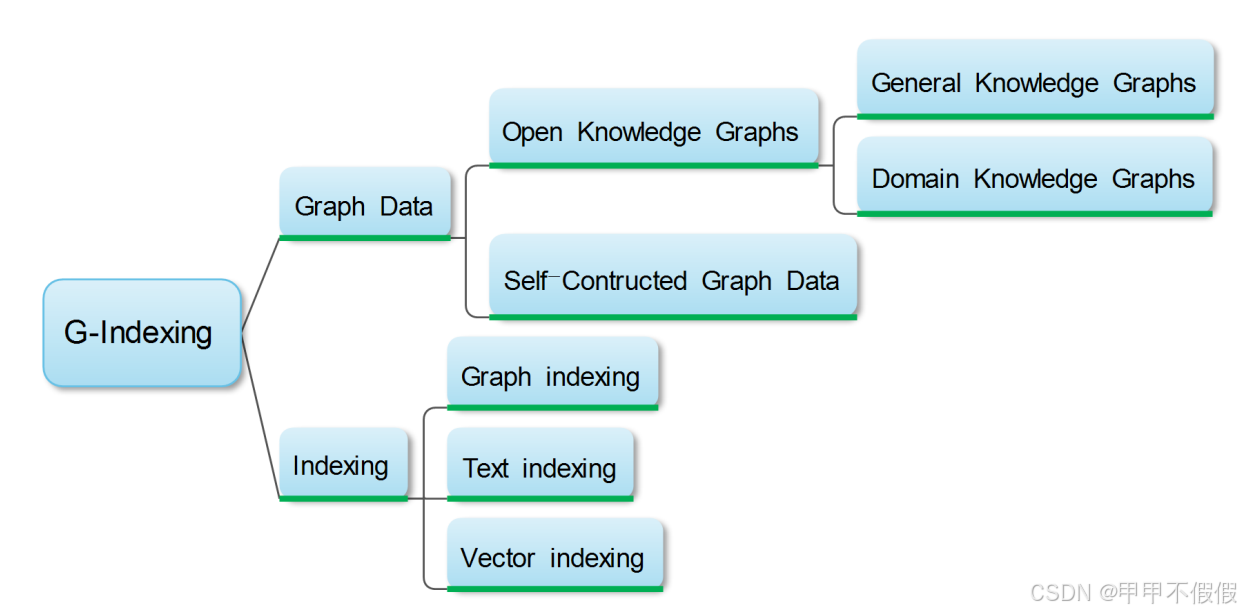
识别或构建图数据库,并在其基础上建立索引,索引过程通常涵盖映射节点和边的属性,在相互连接的节点间建立指针,以及组织数据以支持快速遍历和检索操作。索引决定了后续检索阶段的精细程度。
图引导检索(G-Retrieval)
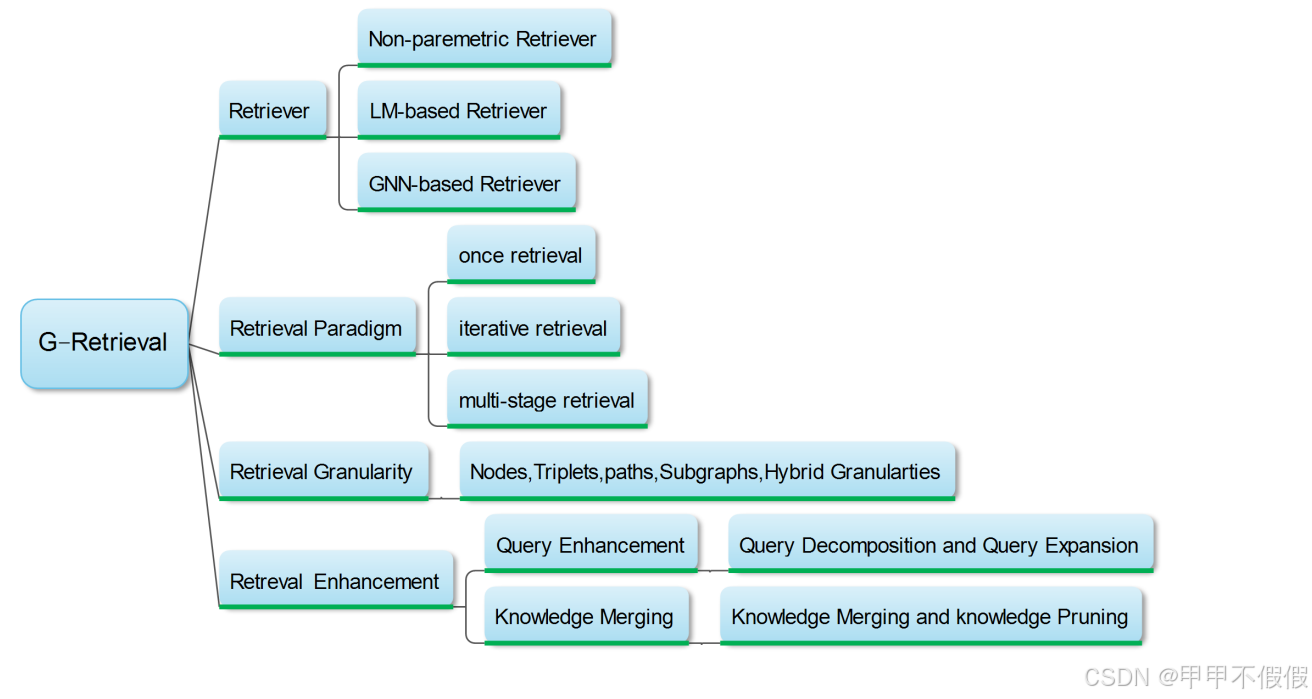
根据用户的查询或输入从图形数据库中提取相关信息,在知识图谱中提取最相关的元素(例如,实体、三元组、路径、子图)
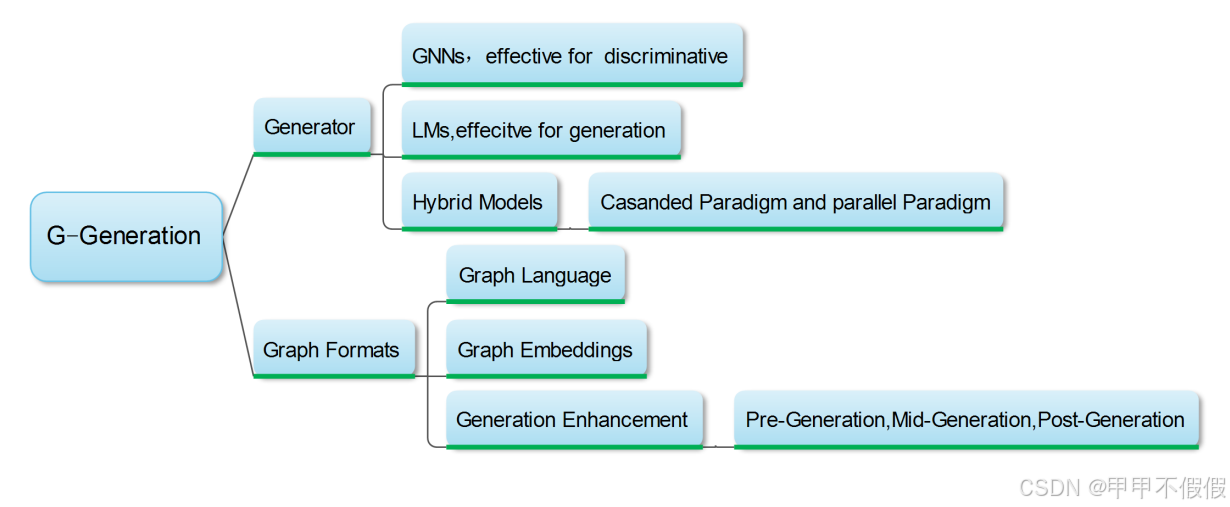
图增强生成(G-Generation)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









