







对于一个现有的数据集,你需要对数据集进行一个透视,从而了解问题的实际情况和数据的分布特征。一般对于分类和回归问题,都有以下的步骤进行数据透视,从而对数据集有一个更深入的理解。你理解数据的目的是深入了解数据为何具有预测性。
步骤具体操作
1. 数据加载与检查:加载数据,检查形状和完整性,并通过抽样对数据集所处的业务背景有一个清晰的认识。
2. 缺失值处理:检测并处理缺失值(删除或填充)。
3. 异常值处理:检测并处理异常值(删除、截断或平滑)。
4. 输入特征处理:调整形状、转换数据类型、归一化/标准化、特征工程(可选)。
以下以泰坦尼克号的旅客生还信息作为示例数据(我通过加载到本地进行导入):datasets/titanic.csv at master · datasciencedojo/datasets · GitHub![]() https://github.com/datasciencedojo/datasets/blob/master/titanic.csv
https://github.com/datasciencedojo/datasets/blob/master/titanic.csv
1 数据的加载与检查
1.1 数据导入
首先,你需要去找到数据集的介绍官网,请不要先下载下来直接看数据,你应该做的是对这个数据集描述的对象有一个清晰的认识。很多信息只有了解了官方的介绍才能够理解数据集本身为何这样设置。
在你了解完数据集的背景之后,你才需要去考虑数据集的导入方式。我的建议是能下载到本地先下载到本地,因为这样有很高的稳定性。然后根据数据的存储格式选择对应的导入方式。例如:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv(r"C:\Users\10158\Downloads\titanic.csv") 1.2 数据集基本信息的了解
1.2.1 数据集的形状
df.shape ![]()
说明这个数据集是一个二维张量,有891个样本,每个样本有12个属性列进行描述。
1.2.2 数据集的基本信息
我们可以知道这个数据集的目前的数据类型、一共有多少列、每列的非null数量、每列的数据类型、从数据类型统计每类一共有多少列、数据集的大小等等基本信息。特别是知道属性列的数据类型之后,你可以修改数据类别从而更好地服务于后续工作。
df.info()
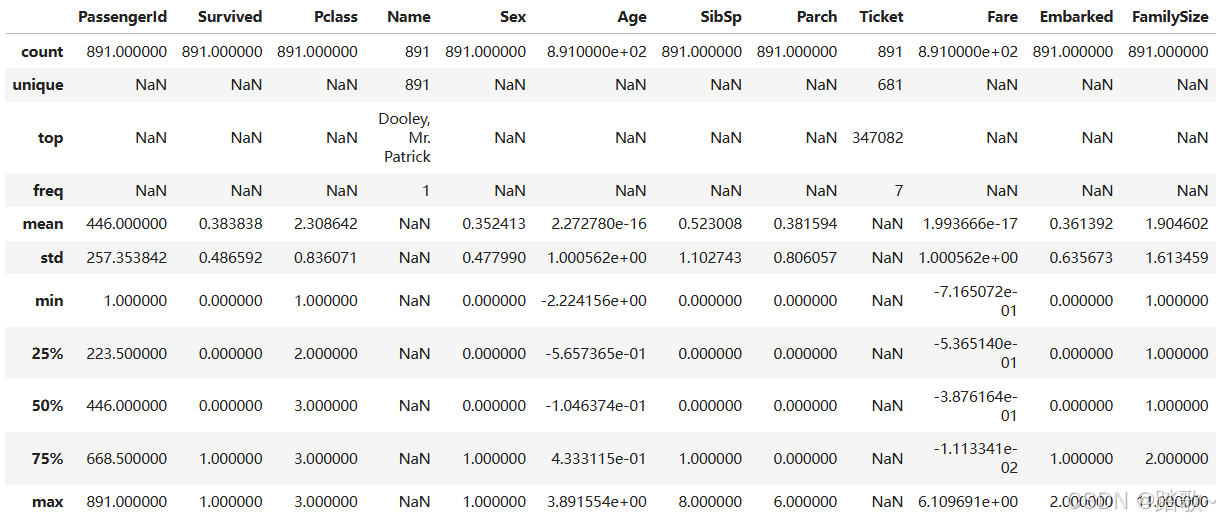
知道了这些基本信息之后,如果想要知道更详细的数据描述信息,你可以使用:
df.describe(include='all')#all的使用可以使得没法用统计手段计算出的列的相关指标用NAN填充
1.2.3 对于每种数据类型要进行可视化
1.2.3.1 图像和自然语言文本
如果数据包含图像或者自然语言,你可以直接查看一些样本(包括标签)。
from tensorflow.keras.datasets import mnist
import matplotlib.pyplot as plt
# 加载 MNIST 数据集
(x_train, y_train), (_, _) = mnist.load_data()
# 显示前 5 张图像和标签
for i in range(5):
plt.figure()
plt.imshow(x_train[i], cmap='gray')#cmap='gray':将图像显示为灰度图。
plt.title(f'Label: {y_train[i]}')
plt.axis('off')
plt.show()
from tensorflow.keras.datasets import imdb
import numpy as np
# 加载 IMDB 数据集
(x_train, y_train), (_, _) = imdb.load_data(num_words=10000)
# 将索引转换为文本
word_index = imdb.get_word_index()
reverse_word_index = {v: k for k, v in word_index.items()}
# 打印第一条评论和标签
decoded_review = ' '.join([reverse_word_index.get(i - 3, '?') for i in x_train[0]])
print(f'Text: {decoded_review}')
print(f'Label: {"Positive" if y_train[0] else "Negative"}')
1.2.3.2 数值特征
如果数据包含数值特征,最好绘制特征的直方图,大致了解特征的取值范围。
from sklearn.datasets import load_iris
import pandas as pd
import matplotlib.pyplot as plt
# 加载 Iris 数据集
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
# 绘制直方图
df.hist(bins=10, figsize=(10, 8))#bins:设置直方图的柱子数量。
plt.suptitle('Iris Dataset Feature Distributions')
plt.show()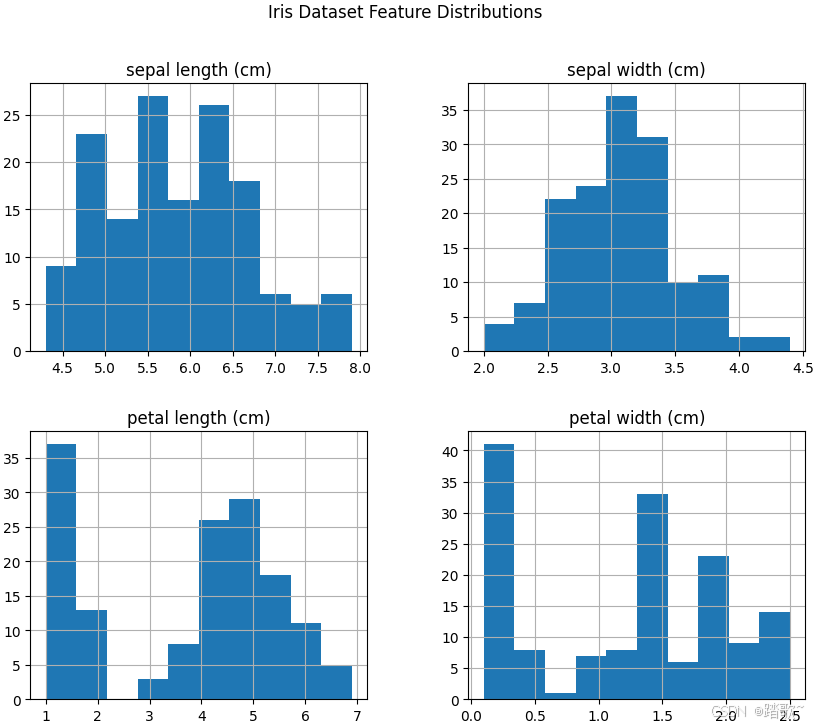
1.2.3.3 位置信息
如果数据包含位置信息,那么可以将其绘制在地图上,观察是否有明显的模式。
import geopandas as gpd
import matplotlib.pyplot as plt
# 加载 Natural Earth 数据
# 假设你已经下载了 'ne_110m_admin_0_countries.shp' 和 'ne_110m_populated_places.shp'
world = gpd.read_file(r"C:\Users\10158\Downloads\ne_110m_admin_0_countries\ne_110m_admin_0_countries.shp")
cities = gpd.read_file(r"C:\Users\10158\Downloads\ne_110m_populated_places\ne_110m_populated_places.shp")
# 绘制地图
ax = world.plot(figsize=(10, 6), color='lightgrey')
cities.plot(ax=ax, color='red', marker='o', markersize=10)
plt.title('World Cities')
plt.show()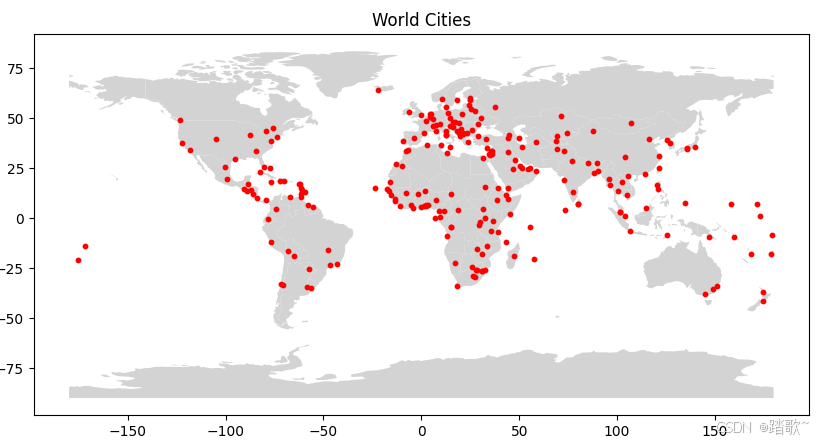
1.2.3.4 类别
如果数据包含类别,你可以画出饼图进行类别比例的观察。如果各个类别出现明显的不均衡,你要慎重考虑这种差异。
import seaborn as sns
import matplotlib.pyplot as plt
# 加载 Titanic 数据集
titanic = sns.load_dataset('titanic')
# 计算类别比例
class_counts = titanic['class'].value_counts()
# 绘制饼图
plt.figure(figsize=(6, 6))
plt.pie(class_counts, labels=class_counts.index, autopct='%1.1f%%', startangle=140)#autopct='%1.1f%%':显示百分比,保留一位小数。startangle=140:从 140 度开始绘制饼图。
plt.title('Titanic Passenger Class Distribution')
plt.show()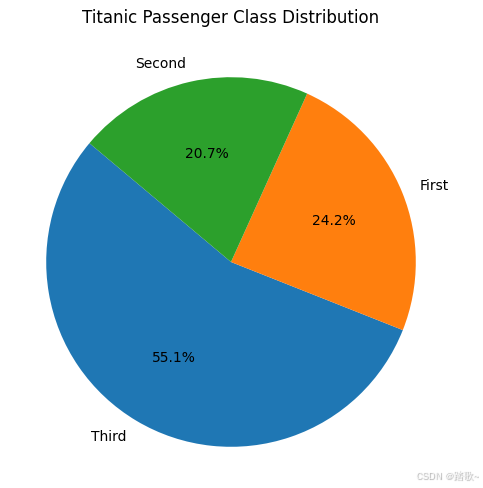
2 缺失值处理
2.1 查看缺失值
2.1.1 查看整体缺失值的情况
df.isnull().sum() 
2.1.2 查看缺失值的索引并访问具体样本
查看所有出现缺失值的样本的序号:
# 检测缺失值
missing_mask = df.isnull().any(axis=1)
# 返回缺失值的索引
df[missing_mask].index.tolist()
查看某一列出现缺失值的样本:
# 检测指定列的缺失值
missing_mask = df['Embarked'].isnull()
# 返回缺失值的索引
df[missing_mask].index.tolist()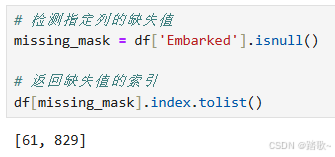
2.2 处理缺失值
2.2.1 对于缺失值占据部分——使用中位数填充
# 处理缺失值
# 对于Age列,我们可以用中位数填充
df['Age'].fillna(df['Age'].median(), inplace=True)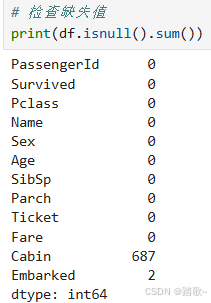
2.2.1 对于大部分都缺失的列——直接删除该列
# 对于Cabin列,缺失值太多,我们可以删除这一列
df.drop('Cabin', axis=1, inplace=True)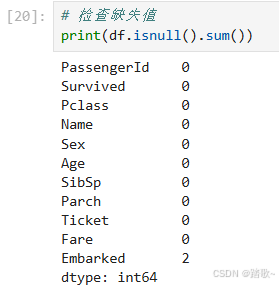
2.2.3 对于极少数的空缺——使用众数进行填充
# 对于Embarked列,我们可以用众数填充
df['Embarked'].fillna(df['Embarked'].mode()[0], inplace=True)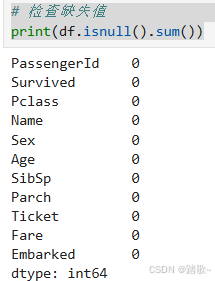
3 异常值处理
3.1 异常值识别
3.1.1 对数值列
可以首先对所有的数值列进行画箱线图的方法进行大致的了解。
# 绘制所有列的箱线图
plt.figure(figsize=(10, 6))
sns.boxplot(data=df)
plt.title('Boxplot of All Columns')
plt.show()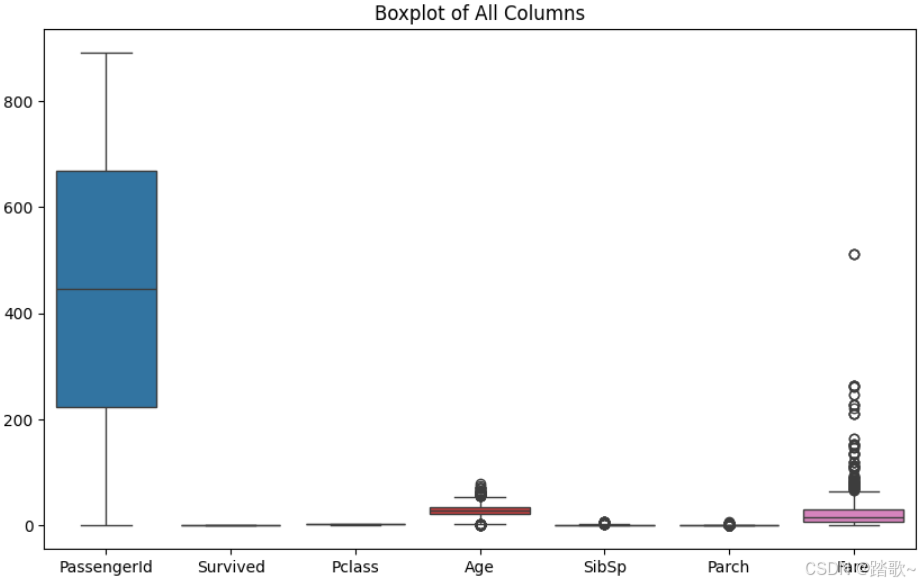
可以很明显的看到,对整体进行箱线图的绘制之后可以发现有些列需要进一步的进行异常值的研究,比如'Age'和'Fare'
那么,对单个列进行箱线图的绘制:
sns.boxplot(x=df['Fare'])
plt.title('Fare Boxplot')
plt.show()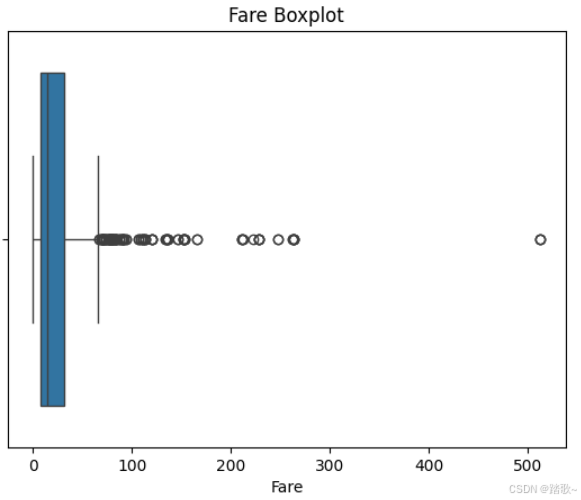
3.1.2 对类别列
对类别列,你需要统计每类的出现频率,如果某一类别频率过高或者过低都可以被选为异常值。
# 统计每个类别的频率
freq = df['Sex'].value_counts(normalize=True)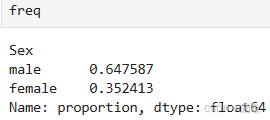
可以看出来,类别不是很均衡,但不能归类为异常值。
3.2 访问具体异常值样本
3.2.1 对数值列
threshold=1.5
# 计算四分位数
Q1 = df['Fare'].quantile(0.25)
Q3 = df['Fare'].quantile(0.75)
IQR = Q3 - Q1
# 计算异常值的上下界
lower_bound = Q1 - threshold * IQR
upper_bound = Q3 + threshold * IQR
# 检测异常值
outlier_mask = (df['Fare'] < lower_bound) | (df['Fare'] > upper_bound)
# 返回异常值的索引
df[outlier_mask].index.tolist()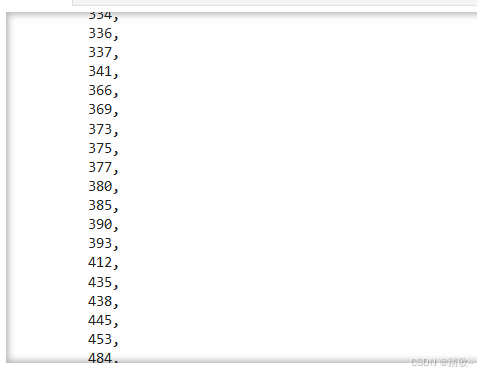
3.2.2 对类别列
anomaly_indices = []
rare_threshold=0.05
# 检测罕见类别
freq = df['Sex'].value_counts(normalize=True)
rare_categories = freq[freq < rare_threshold].index.tolist()
rare_indices = df[df['Sex'].isin(rare_categories)].index.tolist()
anomaly_indices.extend(rare_indices)3.3 处理异常值
3.3.1 对数值列
使用截断法。
# 处理Fare列的异常值,使用截断法
df['Fare'] = np.where(df['Fare'] > 300, 300, df['Fare'])where函数三个参数第一个是识别异常值的条件,第二个参数是异常值全部替换为什么值,第三个参数是不是异常值的数值存成什么值。
3.3.2 对类别列
对极低频率出现的类别可以直接根据上述得出的列表进行删除。
# 删除指定索引的样本
cleaned_data = data.drop(anomaly_indices)4 数值处理
4.1 对类别列进行数值化
# 转换数据类型
df['Sex'] = df['Sex'].map({'male': 0, 'female': 1})
df['Embarked'] = df['Embarked'].map({'S': 0, 'C': 1, 'Q': 2})或者一步到位,对定性特征直接使用哑编码:
OneHotEncoder().fit_transform(df['Embarked'].reshape((-1,1)))4.2 对数值列进行无量纲化
常见的无量纲化的方法有:标准化、区间放缩法、归一化。
无量纲化使不同规格的数据转换到同一规格。常见的无量纲化方法有标准化和区间缩放法。标准化的前提是特征值服从正态分布,标准化后,其转换成标准正态分布。区间缩放法利用了边界值信息,将特征的取值区间缩放到某个特点的范围,例如[0, 1]等。
4.2.1标准化
标准化需要计算特征的均值和标准差,公式表达为:
![]()
使用preproccessing库的StandardScaler类对数据进行标准化的代码如下:
from sklearn.preprocessing import StandardScaler
#标准化,返回值为标准化后的数据
StandardScaler().fit_transform(iris.data)
2.1.2 区间缩放法
区间缩放法的思路有多种,常见的一种为利用两个最值进行缩放,公式表达为:
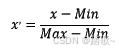
使用preproccessing库的MinMaxScaler类对数据进行区间缩放的代码如下:
from sklearn.preprocessing import MinMaxScaler
#区间缩放,返回值为缩放到[0, 1]区间的数据
MinMaxScaler().fit_transform(iris.data)
2.1.3 归一化的区别
简单来说,标准化是依照特征矩阵的列处理数据,其通过求z-score的方法,将样本的特征值转换到同一量纲下。归一化是依照特征矩阵的行处理数据,其目的在于样本向量在点乘运算或其他核函数计算相似性时,拥有统一的标准,也就是说都转化为“单位向量”。规则为l2的归一化公式如下:
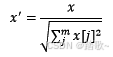
使用preproccessing库的Normalizer类对数据进行归一化的代码如下:
from sklearn.preprocessing import Normalizer
#归一化,返回值为归一化后的数据
Normalizer().fit_transform(iris.data)4.3 对一些定量特征二值化
定量特征二值化的核心在于设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0,公式表达如下:

使用preproccessing库的Binarizer类对数据进行二值化的代码如下:
from sklearn.preprocessing import Binarizer
#二值化,阈值设置为3,返回值为二值化后的数据
Binarizer(threshold=3).fit_transform(iris.data)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











