







一、描述
交叉熵损失函数(Cross-Entropy Loss)是在机器学习和深度学习中常用的一种损失函数,用于衡量模型输出与真实标签之间的差异。交叉熵损失函数通常用于分类任务,特别是在多分类问题中。
二、公式与定义
公式一:
p(x)为概率,取值范围为(0,1),所以L(x)大于0小于正无穷
-log(p(x))可以表示当结果概率p(x)越大时,L(x)损失值越小
定义:
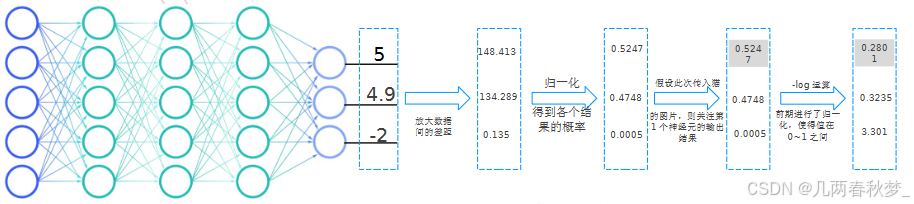
假设第一个神经元是猫,第二个是狗,第三个是鸟
1、我们将传入猫的照片得到三份数据(输出层有三个神经元)
2、将数据进行放大(放大数据间的差距)
3、归一化,用来得到各个结果的概率(因为我们传入的是猫的照片,而第一个输出神经元是猫,所以我们关注第一个神经元输出结果)
4、利用公式对三个输出结果概率进行-log运算(比较)
如果传入猫照片,猫的神经元输出数值相比其他越大
计算的损失值会越小,也表明越靠近真实结果
如果训练时,分类错了,则会出现较大的损失值
公式二:
-M:类别的数量
:符号函数(0或1),如果样本i的真实类别等于c取1,否则取0
:观测样本i属于类别c的预测概率
定义:
1、先把所得到的损失值累加起来,如果传入的数据与样本类别相同,取1,否则取0,这样我们就把符合样本的损失值累加起来。
2、如果传入多个样本,就将多个样本损失值累加起来,再除以样本即可。
三、优缺点
优点:
1、能够直接衡量模型预测与真实标签之间的差异,有效解决梯度消失问题
2、符号最大似然估计原理,并在多类别分类问题中表现良好
缺点:
1、对极端预测值敏感,数值不稳定,并且不适用于回归问题或其他类型的任务
2、在处理极端概率和数值不稳定性时,可鞥需要进行额外的处理
3、对于其他任务类型,需要选择适当的损失函数
四、案例
Pytorch有内置的torch.nn.CrossEntropyLoss计算交叉熵,当使用该方法作为损失函数时需要注意两点,一个是因为torch.nn.CrossEntropyLoss内置了Softmax运算,因此不需要在网络的最后添加Softmax层,一个是给进去函数的label应该是一个整数,而不是one-hot编码形式,因为他会自动对给进去的标签进行onehot编码,再跟网络的预测结果算交叉熵。
import torch
'''
每一个样本都有一个标签,表示它的真实类别。在深度学习中,通常是分批进行训练。
对于一个N分类问题,样本的标签只可能是0、1、2 ... N-1
则对于一个3分类问题,样本的标签只可能是0或1或2。
当batch_size为5时,这一个batch的标签是一个形状为[batch_size]的tensor,即shape为[5]
'''
# 一个batch(batch_size=5)的标签
label = torch.tensor([1, 2, 0, 1, 0])
print(label.shape) # [5]
'''
对于一个3分类问题,当训练时batch_size为5,
则深度网络对每一个batch的预测值是一个形状为[batch_size, classes]的tensor,即shape为[5, 3]
以深度网络对第一个样本的预测值[0.5, 0.8, -1.2]为例,
经过Softmax层后,得到[0.3949, 0.5330, 0.0721],表示深度网络认为第一个样本属于0,1,2这三类的概率分别是0.3949,0.5330, 0.0721
'''
predict = torch.tensor([[0.5, 0.8, -1.2],
[-0.2, 1.8, 0.5],
[0.3, 0.2, 0.7],
[0.6, -0.8, -0.4],
[-0.4, 0.2, 0.8]])
print(predict.shape) # [5, 3]
# 当reduction='none'时,输出是对每一个样本预测的损失
loss_func = torch.nn.CrossEntropyLoss(reduction='none')
loss = loss_func(predict, label)
print(loss) # tensor([0.6292, 1.6421, 1.2228, 1.8790, 1.8152])
# 当reduction='sum'时,输出是对这一个batch预测的损失之和
loss_func = torch.nn.CrossEntropyLoss(reduction='sum')
loss = loss_func(predict, label)
print(loss) # tensor(7.1883)
# 当reduction='mean'时,输出是对这一个batch预测的平均损失
loss_func = torch.nn.CrossEntropyLoss(reduction='mean')
loss = loss_func(predict, label)
print(loss) # tensor(1.4377)



















 3179
3179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











