







 本文探讨了代码随想录中的算法性能分析,包括时间复杂度(大O表示法)的应用,特别关注递归算法的时间复杂度计算和空间复杂度的概念。还比较了C++、Java和Python等编程语言在内存管理上的差异,强调了栈和堆的区别以及内存泄漏问题在不同语言中的处理方式。
本文探讨了代码随想录中的算法性能分析,包括时间复杂度(大O表示法)的应用,特别关注递归算法的时间复杂度计算和空间复杂度的概念。还比较了C++、Java和Python等编程语言在内存管理上的差异,强调了栈和堆的区别以及内存泄漏问题在不同语言中的处理方式。
来自代码随想录的刷题路线:代码随想录
算法性能分析
时间复杂度:
什么是大O?
算法导论给出的解释:大O用来表示上界的,当用它作为算法的最坏情况运行时间的上界,就是对任意数据输入的运行时间的上界。
O代表的就是一般情况,而不是严格的上界。如图所示: 
O(logn)中的log是以什么为底?
平时说这个算法的时间复杂度是logn的,那么一定是log 以2为底n的对数么?
其实不然,也可以是以10为底n的对数,也可以是以20为底n的对数,但我们统一说 logn,也就是忽略底数的描述。
为什么可以这么做呢?如下图所示:

假如有两个算法的时间复杂度,分别是log以2为底n的对数和log以10为底n的对数,那么这里如果还记得高中数学的话,应该不难理解以2为底n的对数 = 以2为底10的对数 * 以10为底n的对数。
而以2为底10的对数是一个常数,在上文已经讲述了我们计算时间复杂度是忽略常数项系数的。
抽象一下就是在时间复杂度的计算过程中,log以i为底n的对数等于log 以j为底n的对数,所以忽略了i,直接说是logn。
递归算法的时间复杂度
一些同学可能一看到递归就想到了O(log n),其实并不是这样,递归算法的时间复杂度本质上是要看: 递归的次数 * 每次递归中的操作次数。
int function2(int x, int n) {
if (n == 0) {
return 1; // return 1 同样是因为0次方是等于1的
}
return function2(x, n - 1) * x;
}
每次n-1,递归了n次时间复杂度是O(n),每次进行了一个乘法操作,乘法操作的时间复杂度一个常数项O(1),所以这份代码的时间复杂度是 n × 1 = O(n)。
空间复杂度:
空间复杂度是考虑程序运行时占用内存的大小,而不是可执行文件的大小。
空间复杂度是预先大体评估程序内存使用的大小。
代码的内存消耗:
不同语言的内存管理
不同的编程语言各自的内存管理方式。
- C/C++这种内存堆空间的申请和释放完全靠自己管理
- Java 依赖JVM来做内存管理,不了解jvm内存管理的机制,很可能会因一些错误的代码写法而导致内存泄漏或内存溢出
- Python内存管理是由私有堆空间管理的,所有的python对象和数据结构都存储在私有堆空间中。程序员没有访问堆的权限,只有解释器才能操作。
例如Python万物皆对象,并且将内存操作封装的很好,所以python的基本数据类型所用的内存会要远大于存放纯数据类型所占的内存,例如,我们都知道存储int型数据需要四个字节,但是使用Python 申请一个对象来存放数据的话,所用空间要远大于四个字节。
C++的内存管理
以C++为例来介绍一下编程语言的内存管理。
如果我们写C++的程序,就要知道栈和堆的概念,程序运行时所需的内存空间分为 固定部分,和可变部分,如下:
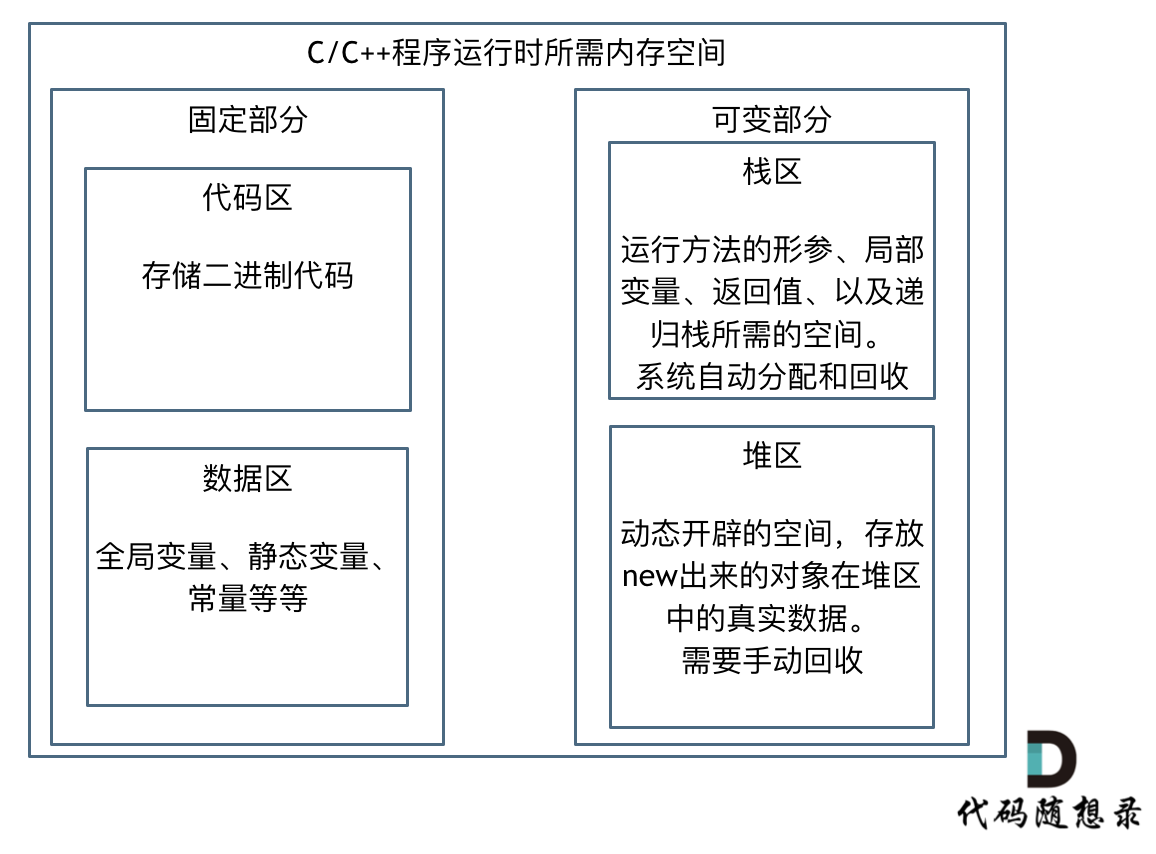
固定部分的内存消耗 是不会随着代码运行产生变化的, 可变部分则是会产生变化的
更具体一些,一个由C/C++编译的程序占用的内存分为以下几个部分:
- 栈区(Stack) :由编译器自动分配释放,存放函数的参数值,局部变量的值等,其操作方式类似于数据结构中的栈。
- 堆区(Heap) :一般由程序员分配释放,若程序员不释放,程序结束时可能由OS收回
- 未初始化数据区(Uninitialized Data): 存放未初始化的全局变量和静态变量
- 初始化数据区(Initialized Data):存放已经初始化的全局变量和静态变量
- 程序代码区(Text):存放函数体的二进制代码
代码区和数据区所占空间都是固定的,而且占用的空间非常小,那么看运行时消耗的内存主要看可变部分。
在可变部分中,栈区间的数据在代码块执行结束之后,系统会自动回收,而堆区间数据是需要程序员自己回收,所以也就是造成内存泄漏的发源地。
而Java、Python的话则不需要程序员去考虑内存泄漏的问题,虚拟机都做了这些事情。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









