







一、基础概念
合批主要是针对这三个概念进行优化减少:
① SetPass Call:一次渲染状态切换,也就是每次切换 材质/Pass 时,就会触发一次SetPass Call
② Draw Call:cpu 调用一次 gpu 绘制函数
③ Batch:表示一组可以一起交给gpu的Draw Call
优化结果可以在 Game窗口-Stats 或 FrameDebugger 中查看。
二、4 种主要合批方式
1. 动态合批 (降低draw call)
cpu 快速 将 共享同一材质&pass 的多个模型合并为一个模型,再通过一次draw call绘制。
- 只有内置管线可用
- 适用于 小的、动态 物体,加起来不能超过900个float4顶点
- 实现:

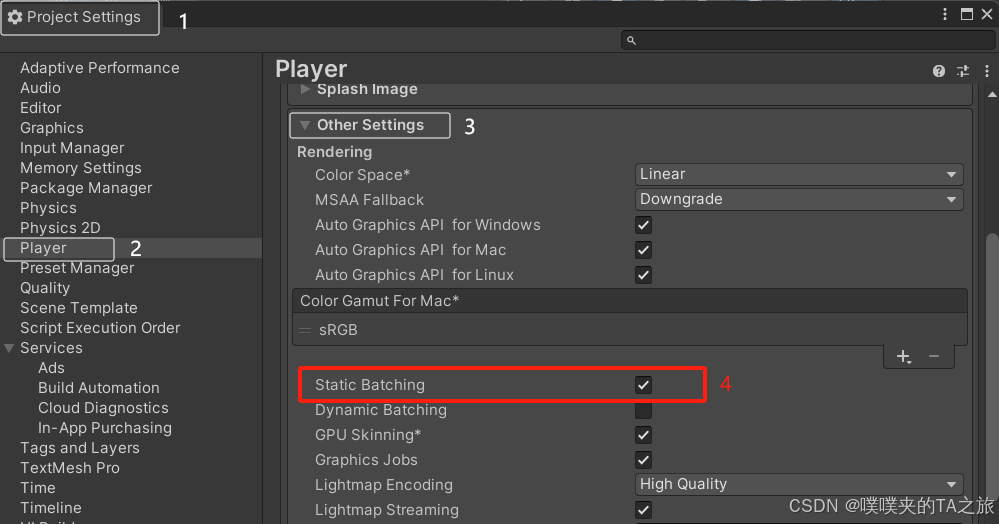
2. 静态合批 (降低batch)
提前 将 着色器相同的静态物体 合并为一个模型,且预先进行坐标变换。
- 适用所有管线
- 空间换时间
- 减少batch但不减少draw call
- 实现:
3. GPU Instancing (降低draw call)
适用于 同一模型的微小差异大批渲染,只提交一个mesh和材质,但提交所有实例的差异化信息,然后对同一个mesh在GPU中进行变换绘制。
- 适用所有管线
- 完全相同的 Mesh & 材质,只有材质参数不同
- 实现:表面着色器
(1) 启用。
如果是完全一样的材质,直接勾选Material的Inspector面板中的 Enable GPU Instancing 选项即可,后面的两步都可以省略。
![]()
(2) 修改shader。
如果每个模型的材质属性有差异的话,就可以在表面着色器的以下部分的代码中设置有所差异的属性。

(3) 从cs脚本中为属性传入不同值。
eg:


- 实现:顶点片元着色器
流程和表面着色器基本一致,只是第二步中会稍微复杂一点。
(1) 启用。
同样是需要启用gpu instancing选项,但对于顶点片元这种着色器生成的材质面板上是没有该选项的,所以shader中需要添加使用instancing的变体。
![]()
(2) 修改shader。
① 顶点着色器的输入输出结构中注册实例化ID;
② 设置有所差异的属性;
③ 顶点与片元着色器中,让其能访问结构体,并顺利传递。
④ 使用②中设置好的属性。



(3) 从cs脚本中为属性传入不同值。与表面着色器一致。
4. SRP Batcher (降低set pass call)
对使用同一材质/Pass的不同模型,通过 减少无需更新的数据buffer的更新频次 来降低set pass call 进行加速。(将使用过的材质数据缓存到显卡中,之后再使用该材质就不需要重新从cpu再传数据了,直接用显卡中的数据)
- 只支持SRP
- 不减少draw call
- 如果本身的stepasscall占比就不高,主要的时间开销就是drawcall的话,使用这个方法的前后帧率提升就不明显
 --优化后->
--优化后->
- 实现:
(1) 将管线配置的inspector面板改为debug模式,然后勾选Use SRP Batcher。

(2) 【可选步骤】因为SRP Batcher只对相邻的渲染指令生效,所以要确保连续渲染。例如在我的卡渲那篇文章中,就通过RenderObjects将描边pass的渲染提取到连续的顺序来渲染,这样就为后续的合并提供了基础条件。
(3) 修改Shader变量:将pass中的变量用 CBUFFER_START(UnityPerMaterial) 和 CBUFFER_END 包裹起来。如果是多pass的shader,还需要确保每个pass中的变量及其顺序是一致的。
如果修改正确,shader的inspector面板中就会显示SRP Batcher是compatible的,如果依然不符合标准,会显示not compatible并给出错误提示。
![]()


















 625
625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









